This content has been marked as final.
Show 7 replies
-
1. Re: Cross-site replication error in 6.0.2
vbchin2 Jun 3, 2014 6:34 PM (in response to infiniuser)
This has been done for you with the project below. Please take a look! I know you are using the community project and would like to run with it but just to prove the Cross Site Replication, you can initially use the demo and then understand how to configure your XML files to make things work on the community Infinispan server.
-
2. Re: Cross-site replication error in 6.0.2
infiniuser Jun 3, 2014 7:23 PM (in response to vbchin2)
Hi Vijay,
I had seen this project and compared my config (attached along with question) with jdg-site1.xml, couldn't find any major difference in terms of x-site config apart from TCP vs UDP. Could you please give some pointers on what the "no physical address for SiteMaster(DC1)," , "no route to DC2:" errors mean and where to specify these so that ISPN understands the address/route.
Thanks,
Joseph
-
3. Re: Cross-site replication error in 6.0.2
vbchin2 Jun 3, 2014 9:04 PM (in response to infiniuser)
Few questions:
- Are you passing the port number as well for the initial XSITE hosts in the form : 192.168.1.2[7600],192.168.1.3[7600] ?
- Are the DC1 nodes and DC2 nodes clustering in their respective data centers ?
- Can you try removing all the caches from the 'clustered' cache container leaving just one, lets say 'xsite-cache' and also mark it as the default one ?
- If all the DC1 nodes are being run on a the same VM, are you ensuring that port-offsets are applied ? If port-offset is 100, then the list in #1 would be : 192.168.1.2[7600],192.168.1.2[7700]
Start with one node on DC1 and one node on DC2. Attach the startup script so that I know how you are invoking it. Also try applying the below mentioned line to see if makes any difference.
If nothing works out attach the DC1.xml and DC2.xml files and make sure that when you diff both of them other the required changes are different between the files while the rest is the same. Also, when everything fails, try using UDP multicast if your network (between the two hosts) supports it and test the outcome.
-
4. Re: Cross-site replication error in 6.0.2
infiniuser Jun 3, 2014 10:54 PM (in response to vbchin2)
Answers below inline, i couldn't find the line which you mentioned as "try applying the below mentioned line to see if makes any difference." -- guess it got lost in formatting?
Are you passing the port number as well for the initial XSITE hosts in the form : 192.168.1.2[7600],192.168.1.3[7600] ?
The jgroups.tcpping.initial_hosts and jgroups.tcpping.initial_hosts-xsite are passed as system properties with port number - like host1[7800],host2[7800]
- Are the DC1 nodes and DC2 nodes clustering in their respective data centers ?
Yes, they were working standalone separately with the default clustered.xml configuration.
- Can you try removing all the caches from the 'clustered' cache container leaving just one, lets say 'xsite-cache' and also mark it as the default one ?
Yes, will try it. However, there were no errors specific to any cache upon startup.
- If all the DC1 nodes are being run on a the same VM, are you ensuring that port-offsets are applied ? If port-offset is 100, then the list in #1 would be : 192.168.1.2[7600],192.168.1.2[7700]
All the nodes are in their own machines.
The runtime process detail (from ps) from a node in DC1 is :
/usr/java/default/bin/java -D[Standalone] -server -XX:+UseCompressedOops -XX:+TieredCompilation -Xms2g -Xmx2g -Dsun.rmi.dgc.client.gcInterval=3600000 -Dsun.rmi.dgc.server.gcInterval=3600000 -XX:PermSize=128m -XX:MaxPermSize=256m -Djava.net.preferIPv4Stack=true -Dorg.jboss.resolver.warning=true -Djboss.modules.system.pkgs=org.jboss.byteman -Djboss.server.base.dir=/abc -Djboss.server.log.dir=/abc/log -Djboss.server.config.dir=/abc/configuration -Djboss.server.default.config=clustered-xsite-DC1.xml -Djboss.socket.binding.port-offset=200 -Djava.awt.headless=true -Djboss.bind.address=10.235.xxx.yyy-Djboss.bind.address.management=10.235.xxx.yyy -Djboss.default.jgroups.stack=tcp -Djgroups.tcpping.initial_hosts=host1[7800],host2[7800],host3[7800],host4[7800],host5[7800],host6[7800],host7[7800],host8[7800] -Djgroups.tcpping.initial_hosts-xsite=host5[7800],host6[7800],host7[7800],host8[7800] -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -Xloggc:/abc/log/gc.20140603-191336.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Dsun.net.inetaddr.ttl=60 -Dorg.jboss.boot.log.file=/abc/log/boot.log -Dlogging.configuration=file:/abc/configuration/logging.properties -jar /appl/infinispan-server-6.0.2.Final/jboss-modules.jar -mp /appl/infinispan-server-6.0.2.Final/modules -jaxpmodule javax.xml.jaxp-provider org.jboss.as.standalone -Djboss.home.dir=/appl/infinispan-server-6.0.2.Final
host1 to host4 are in DC1 and host5 to host8 in DC2.
One question - what is the significance of "clustered" and "global" clusters. In the startup logs of host1, i can see :
18:48:56,207 INFO [stdout] (MSC service thread 1-3) GMS: address=host1/DC1, cluster=clustered, physical address=10.235.xxx.yyy:7800
and few lines later..
18:48:59,543 INFO [stdout] (Timer-2,shared=tcp) GMS: address=_host1/DC1:DC1, cluster=global, physical address=10.235.xxx.yyy:7801
but not in all nodes. Others show only cluster=clustered
-
5. Re: Cross-site replication error in 6.0.2
vbchin2 Jun 4, 2014 3:35 AM (in response to infiniuser)
Joseph,
In the material you provided, all looks good but I sincerely hope when you say host1 in the output of ps, it actually was showing a IP address for host1. Am I correct ? If No, then host1 should be replaced by the actual IP address of host1, host2 with actual IP of host2 and so on.
The line I meant to copy but I forgot is/was :
I do not have much at this point to suggest beyond what I already have. The only thing that you could do, in addition is to wipe the log files on every node (preferably have 2 node per DC as a starting test case), start them and capture the logs (on every node).
You may optionally turn on TRACE logging for org.jgroups, look at this line for example:
Add a similar element as line #75 but change jacorb.config to org.jgroups and ERROR level to TRACE. This will bloat your log files but it would be worth looking at them.
As mentioned before if everything else fails, please attach the clustered.xml file for one node from DC1 and one node from DC2. I can volunteer to check it for you.
-
6. Re: Re: Cross-site replication error in 6.0.2
infiniuser Jun 5, 2014 1:39 AM (in response to vbchin2)
Hi Vijay,
The host1, host2 etc. were actual hostnames, not IPs. All of the hosts are in the same n/w and DC, just that we made two clusters and marked them as separate DCs for testing. The final deployment with have each cluster on separate DC, requiring x-site replication. With an updated configuration (attached), we were able to put entries in one DC and get them in another, though i am not sure if this means x-site is really working . There is "message dropped" error in DC2 logs (see below), but the numberOfEntries in the cache statistics Mbean is > 0. The cluster size was reduced to 2 per DC and -Djgroups.tcpping.initial_hosts-all=host1[7800],host2[7800],host5[7800],host6[7800] - i.e all hosts were mentioned ; 1,2 in DC1 and 5,6 in DC2
However, the cache put() becomes really slow after couple of operations, even though all of them get persisted. Attached is the log for 10 puts into "default" and "SESSIONCACHE" , note the 20s delay between some of the puts.
Jun 05, 2014 12:00:35 AM org.infinispan.quickstart.embeddedcache.HotRodQuickstart main
INFO: SESSIONCACHE size after 2:2
Jun 05, 2014 12:00:56 AM org.infinispan.quickstart.embeddedcache.HotRodQuickstart main
INFO: SESSIONCACHE size after 3:3
During this time, the server side logs are :
host1 (DC1 - where put is being invoked) is :
00:00:45,860 WARN [org.infinispan.xsite.BackupSenderImpl] (HotRodServerWorker-180) ISPN000202: Problems backing up data for cache SESSIONCACHE to site DC2: org.infinispan.util.concurrent.TimeoutException: Timed out after 10 seconds waiting for a response from DC2 (sync, timeout=10000)
00:00:55,934 WARN [org.infinispan.xsite.BackupSenderImpl] (HotRodServerWorker-180) ISPN000202: Problems backing up data for cache default to site DC2: org.infinispan.util.concurrent.TimeoutException: Timed out after 10 seconds waiting for a response from DC2 (sync, timeout=10000)
00:01:06,371 WARN [org.infinispan.xsite.BackupSenderImpl] (HotRodServerWorker-180) ISPN000202: Problems backing up data for cache SESSIONCACHE to site DC2: org.infinispan.util.concurrent.TimeoutException: Timed out after 10 seconds waiting for a response from DC2 (sync, timeout=10000)
host5 (DC2):
00:02:17,947 WARN [org.jgroups.protocols.TCP] (TransferQueueBundler,shared=tcp-xsite) JGRP000032: null: no physical address for SiteMaster(DC2), dropping message
00:02:18,703 WARN [org.jgroups.protocols.TCP] (TransferQueueBundler,shared=tcp-xsite) JGRP000032: null: no physical address for SiteMaster(DC2), dropping message
00:02:20,083 WARN [org.jgroups.protocols.TCP] (TransferQueueBundler,shared=tcp-xsite) JGRP000032: null: no physical address for SiteMaster(DC2), dropping message
00:02:20,704 WARN [org.jgroups.protocols.TCP] (TransferQueueBundler,shared=tcp-xsite) JGRP000032: null: no physical address for SiteMaster(DC2), dropping message
host6 (DC2) :
00:00:34,981 WARN [org.infinispan.xsite.BackupSenderImpl] (HotRodServerWorker-270) ISPN000202: Problems backing up data for cache default to site DC1: UnreachableException: member=SiteMaster(DC1)
00:00:35,225 WARN [org.infinispan.xsite.BackupSenderImpl] (HotRodServerWorker-270) ISPN000202: Problems backing up data for cache SESSIONCACHE to site DC1: UnreachableException: member=SiteMaster(DC1)
00:00:35,319 WARN [org.infinispan.xsite.BackupSenderImpl] (HotRodServerWorker-270) ISPN000202: Problems backing up data for cache default to site DC1: UnreachableException: member=SiteMaster(DC1)
00:00:56,108 WARN [org.infinispan.xsite.BackupSenderImpl] (HotRodServerWorker-270) ISPN000202: Problems backing up data for cache SESSIONCACHE to site DC1: UnreachableException: member=SiteMaster(DC1)
00:00:56,238 WARN [org.infinispan.xsite.BackupSenderImpl] (HotRodServerWorker-270) ISPN000202: Problems backing up data for cache default to site DC1: UnreachableException: member=SiteMaster(DC1)
MBean stats mismatchThough 10 entries were put (from host1), only a lower number is seen in numberOfEntries in JMX (host1 - 6, host2 -3, host5-6, host6 -5) , but i am able to retrieve all 10 from host1. Does this mean some of the entries are dropped, or this a MBean reporting issue?
-
clustered-xsite-DC2.xml 16.1 KB
-
client.log.zip 722 bytes
-
clustered-xsite-DC1.xml 16.0 KB
-
-
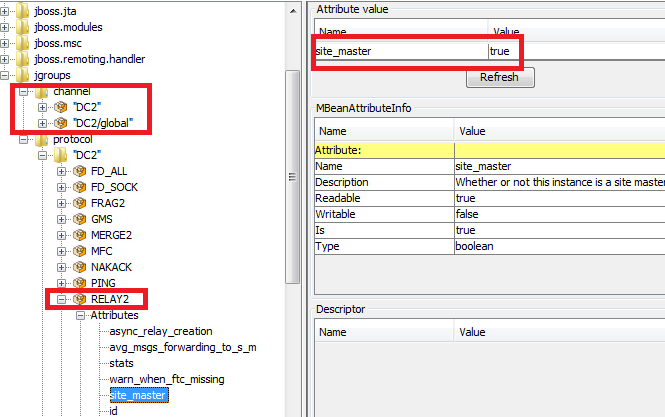
7. Re: Re: Re: Cross-site replication error in 6.0.2
infiniuser Jun 13, 2014 2:42 AM (in response to infiniuser)
Hi Vijay,
Could you please share how the JGroups MBeans look like for each of the nodes - especially the "site master" nodes. I have attached the MBean view from the cluster ; noticed that the first node to be started up (DC2 in this example) gets the SiteMaster status and has a "global" channel in addition to it's own DC channel, but the node on the other cluster does not get this status (site_master=false). The error is "no physical address for SiteMaster(DCx)" where x is the node on DC that was started second.
Thanks,
Joseph
-
jgroups-mbeans.png 34.2 KB
-