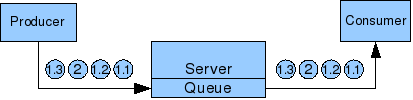
Currently when a large message is sent it is sent as one large message. This means that it hogs the transport for the duration of the send or receive meaning other messages (including Ping messages) have to wait for its completion. In the following diagram if message 1 is large, message 2 would have to wait until completion of the send.

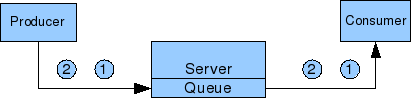
The solution is to break up large messages into smaller, say 1k, messages. This allows the all message 2 to be delivered whilst message 1 is being delivered.

Implementation:
We add another level of abstraction that sits in between the RemotingConnection and the Session for sending messages and between the dispatcher and the Handler for receiving messages. This would be a PacketAssembler that would have assemble() and disAssemble() methods. The disassemble method would be called by the RemotingConnection and would split the packet and send each packet via the session, in reality it would be the same packet sent each time but between each write but its correlation id would be incremented. The assemble would do the same in reverse and would be called by the dispatcher. This would wait for all the parts of the message to be received before dispatching to the appropriate handler.
disassembling the message:
currently in the encode() method of PacketImpl we write the length, type, response target, target, and executorid direct to the MessagingBuffer. The first thing we do is add a new field correlationId and a flag to specify if it is the last packet. The correlation id would be -1 if it was a single packet. Currently the next thing written to the buffer is the body via the encodeBody() method. This would be where we would only write how ever many bytes are needed for each send and would be controlled via the correlation id, i.e. 1024 correlationid to 1024 correlationid + 1023. For doing this there are 2 different approaches:
1.When the first packet is encoded we encode the body to a different Message Buffer and then write to the original buffer only the first n bytes, and then subsequently for each resend of the packet write the appropriate part of the buffer. If the whole message body is split however it means that it always has to be reassembled on the server, which means we would have to deal separately with saving memory on the server, by writing the payload to file etc. Obviously, we only use a different buffer if the message is to be split.
2.The second is to only do the splitting for the payload I.e. the body of MessageImpl. Currently the whole body is written to the stream , we would do a similar thing here by only writing a portion of the body each time depending on the correlation id. This means that as far as the server is concerned its just another message and would deal with it the same way. With this approach however we would have to change the routing policy so split messages are always consumed by the same consumer and also if a consumer dies before receiving all the portions of a message are redelivered to a new consumer. Also it would be difficult handling expiry of messages etc.
I think I prefer 1. as it doesn't change the semantics of routing etc, we just deal with large messages on the server separately by saving the payload to a file.
Assembling the message
This is the same just done in reverse. The dispatcher would pass the messages to the PacketAssembler and once the PacketAssembler had received and assembled all the packets it would pass the full packet to the handler. If we went with solution 1 above its at this point that we could serialise the payload direct to disk and not into memory.
Comments