This page contains some brainstorming around being able to deploy JBoss Cache to replicate state across multiple data centres, JBCACHE-816
Weblogic contains similar functionality limited to the HTTP session replication use case which you can find in Weblogic Session Replication Across Clusters.
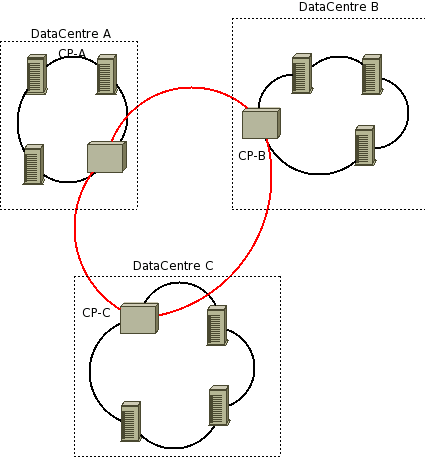
TODO: Diagrams to help understand different scenarios.
Update - 12/03/09
Cache listener based approach is not the most adequate due to the following reasons. Instead, an interceptor should be developed:
- marshalling -> interceptor could take the command itself and forward that, versus listener that needs to convert command into listener event and we then need to convert it back to a command -> think performance!!!
- potential sync replication future! if listener, we can't make cross cluster invocations synched because we'll get callbacks either before or after local sync repl has finished. We're not part of synchronous invocation. If we're an interceptor, we're part of the synch invocation and could potentially implement 2pc accross clusters!
- ping pong effect! no need for wacky disabling of event notifications that would affect other components such as TC L1 cache. Just pass up the stack.
General advice:
- Do not create your own JGroups channel, get it from RPCManager.
New approach altogether - Checkpoint Streaming
- Let's say there's a cluster of 3 nodes: A, B and C and contents are: A=1,2 B=7, C=10,12
- Now, Y joins in another cluster but it's configured for inter cluster replication.
- When Y joins, A instructs B and C to open an start streaming channel and start with a full backup. B&C do not respond immediately, they wait until it's their time so that they don't all stream at the same time (B does it after 1 min, C after 2).
- A streams the contents over of B and C when it receives them over to Y. A takes its contents and streams them over to Y as well when it's his turn.
- What's the content of the full backup? An image of each node that contains keys for which the node is primary (data partitioning).
- Y receives [1,2,7,10,12] contents in different moments in time and spreads them based on its hash algorithm and tolopology.
- Next time around, A=1,2,3 B=7,8 C=10,12,11
- Periodically, B & C send diffs to A, which forwards to Y. A forwards diffs to Y as well.
- These diffs could be big, so store them in file system. Diffs stored in disk in B, C and A so that they don't take up extra memory.
- These diffs or backups are streamed over to Y, no serialization or accumulation!
- Now, Z, in a new cluster, joins the inter cluster bridge.
- It's now time for a full backup, so A asks B&C to schedule a full backup and stream it throw A and sends it to Z.
- A crashes and B takes over - keys rebalanced -> a full backup needs to be forced next time around. -> C needs to open stream with B.
- Y gets uddated with 25 - ideally would only send whatever has been updated cos it's not coordinator - only diffs. Full backups are only send by the inter cluster bridge coordinator!! We don't want Y sending full backups.
- What if diffs from Y were sent at the same time B did a full backup? negotiate...
- How to deal with removes? Let is expire in other clusters? That'd be dangerous
- If 10 removed from C and B fails, a full backup has to be sent, how do we deal with 10 which is present in Y?
- Prefix keys with location (i.e cluster = NY) + version (1,2,3...etc)? Y knows that 10 is not in FB and it originalted in NY.
- Would be compat diffs? No, Difficult!
- Full backup contains keys for which you're primary only too (same as diffs)
---
Current Solution - Primary/Backup Clusters
This solution aims to:
- Facilitate recovery of complete primary/production cluster failures by keeping standby backup clusters ready to take over if necessary.
This solution assumes that:
- Communication between primary and backup cluster is asynchronous; It's not about 100% data reliability.
- While the primary cluster is up, all clients are directed there and hence, communication between primary and backup cluster(s) is unidirectional, from primary to backup.
- Switching over clients from primary to backup is either done via external intervention or via an intelligent global load balancer that is able to detect when the primary cluster has gone down.
This solution consists of:
- A new component based on a JBoss Cache Listener that is running in at least one cluster node within the primary cluster and one cluster node in each of the existing backup clusters. The number of nodes where the component would run would be configurable to be able to cope with cluster node failures. The 2nd in line would maintain the last N updates and replay them when it takes over.
- Component in primary and backup are linked by a JGroups communication channel suited for long distances.
- Component in primary cluster maintains a queue of modifications lists (if transactional commit/prepares) or puts/removes (non-transactional) that are sent to backup cluster(s) components asynchronously.
- Component in backup cluster(s) spreads data evenly accross backup nodes using application consistent hashing mechanism. For example: In the case of HTTP sessions, a specific session data needs always to be in the same backup node. Note: If all backup nodes contained all state, it'd be easier+simpler for state transfer purpouses (proxy on primary can request state, or non buddy state from others in primary, for backup startup), and after a cluster failover there wouldn't need to a calculation on the load balancer side of who's got which session cos all of them had it.
- If cache uses buddy replication:
- Component in primary cluster needs to be active in at least one node in each buddy group listening for updates and pushing them to node queueing updates. If could be that the component is active in all nodes.
Caveats:
- How does a component node whether it's running in primary or backup cluster? Initially static and then modified at runtime in case of cluster failure?
- In buddy replication, how to avoid multiple identical puts being queued? Only the original one is needed. Does the component only live in one of the nodes of each buddy group? From a cache listener perspective, is there a difference between a cache put and a put from a buddy replication?
Discarded Alternatives:
- Rather than the component maintaining a queue of modifications, whether transactional or just put/removes, an alternative would be for such component to retrieve a snapshot periodically and pass it on to the other cluster. Such snapshots would have to make sure that they're transactionally consistent.
- Advantages here are
- Component becomes stateless.
- Disadvantage here are:
- If you're getting snapshot it from coordinator (non buddy scenario) or ask individual nodes to return their non buddy state, this could affect normal functioning of these nodes, potentially overloading them. Maybe snapshots could be retrieved when node(s) are not busy, with some kind of CPU check/threshold?
- In the backup cache state would need to be cleared and reapplied, more work.
- Two continuous snapshots would contain a lot of redundant data.
Other Solutions - Cluster Load Balancing
This solution aims to:
- Allow inter cluster replication to recover from complete cluster failure while spreading load between separated clusters or data centres. For example: clients could be directed to the cluster with less traffic or closest to the client.
This solution assumes that:
- There're no primary/backup clusters, all clusters are active.
- Clients could be directed to a cluster or the other based on cluster load or proximity.
- Communication between clusters is still asynchronous.
- Sticky sessions are in use, with failover attempting to find a node within the local cluster, before doing a failover to a different cluster.
This solution consists of:
- Needs further thought.
Caveats:
- How to avoid data going backwards and forwards between the different clusters taking in account that all clusters can replicate to each other? Avoid ping-pong effect. Periodic snaphot transfer could help here.
Comments