Buddy Replication for JBoss Cache 1.4.0 "Jalapeno"
- Manik Surtani (manik@jboss.org)
(Discuss this design on this forum thread)
Introduction
Buddy replication is based on a concept where data is replicated to a finite number of nodes in a cluster rather than the entire cluster. This helps a cluster scale by not impacting network replication traffic, nor node memory usage as more nodes are added.
Network traffic cost
Network traffic is always restricted to the number of buddy nodes configured. This may not be that great a saving as IP multicast may be used to broadcast changes, but replies (if synchronous replication is used) and subsequent wait time will increase in a linear fashion with every node added to a cluster. When the number of buddies is finite and fixed, nodes can be added to a cluster without any such impact as this replication cost is always static.
Memory cost
With buddy replication, memory usage for each node will be approximately (b+1) X where X is the average data size of each node and b is the number of buddies per node. This scales a lot better than total replication where each node would hold nX where n is the number of nodes in the cluster. Being a function of n, you can see that with total replication, memory usage per node increases with the number of nodes while with buddy replication, this does not happen.
Pre-requisties and assumptions
It is assumed that a decent load balancer will be in use so requests are evenly spread across a cluster and sticky sessions (or equivalent for use cases other than HTTP session replication) are used so that recurring data accesses happen on fixed nodes.
Design concepts
For the sake of simplicity in explanation, I will assume that the number of buddies are set at 1.
Diagram 1: Operational cluster
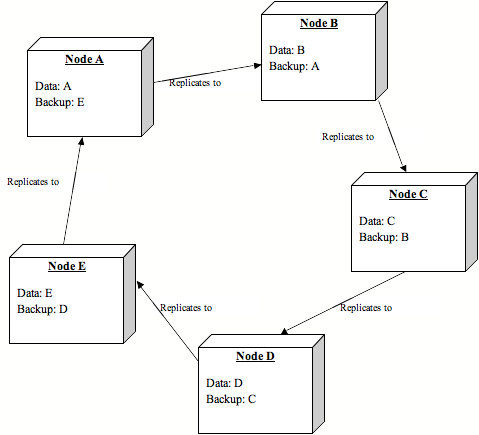
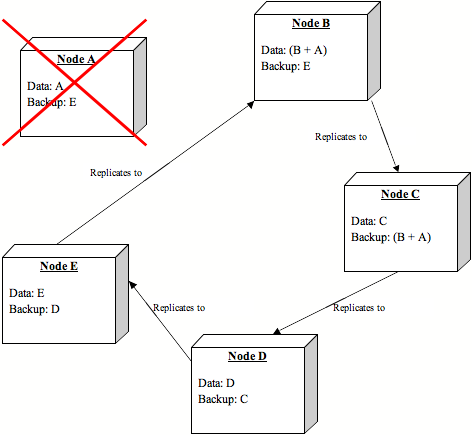
Diagram 2: With node failure
Assume 5 nodes in a cluster, nodes A, B, C, D and E.
Each node has its own data, and the backup data of one other node.
Data is only replicated to the buddy node, not to the entire cluster (synchronous or asynchronous replication may be used)
If a node fails (e.g., A is removed from the cluster) its data is still backed up on B. As nodes start looking for this data, it gravitates from B to the requesting node, which will now take ownership of this data and treat it as its own.
B then starts acting as backup node for E.
Gravitation of data
As requests come in to cache instances which do not have the requested data locally, nodes then ask the cluster for the data and move that data to their local state.
Taking ownership of this data allows for the data most used by specific cache instances to be located closest to such cache instances.
When a cache instance takes ownership of data, it forces the original owner (and any buddies) to remove this data from their in-memory state.
In the above scenario, this allows for the original state of A - backed up on B - to spread out evenly across the cluster as the load balancer directs requests meant for A across the cluster.
Alternative implementation: Data slicing
The alternative to such a scenario where a node inherits all the backup data of a dead node is for the backup node to slice the data evenly and distribute it across the remaining cluster nodes rather than taking ownership of the data.
For a number of reasons, I have decided that this is an unfeasible approach and not to implement it:
Organisation within a tree of data is unknown and slicing may result in corrupt data.
Even when specifically speaking of HTTP Session replication where data structure is known, when TreeCacheAOP is used (FIELD level replication) we don't know the relationship between data elements which makes slicing a challenge again.
Traversing the tree to try and 'guess' data boundaries for slicing may be expensive.
I also see slicing as unnecessary because using data gravitation alleviates the imbalance of some nodes holding more data than others in a cluster.
Dealing with more than 1 buddy
Behaviour is precisely the same as when dealing with just one buddy. The first instance to provide a valid respose to a data gravitation request is the one that is used as the source of data.
A buddy node dies
The Data Owner detects this, and nominates more buddies to meet its configured requirement.
Initiates state transfers to these buddies so backups are preserved.
Implementation overview
Buddy replication will be implemented by enhancing the BaseRPCInterceptor. This way existing replication semantics do not change in any of the subclasses of the BaseRPCInterceptor - the only thing that changes is the BaseRPCInterceptor.replicateCall() method, which based on configuration, replicates to the entire group or to specific nodes.
The BaseRPCInterceptor will maintain a reference to a BuddyManager (if configured), which will use a BuddyLocator (see below) to maintain a list of buddies.
Configuring buddy replication
A new configuration element - BuddyReplicationConfig - will be used. The element will take an XML config element, to maintain consistency with the way eviction policies and cache loaders are configured.
<attribute name="BuddyReplicationConfig"> <config> <buddyReplicationEnabled>true</buddyReplicationEnabled> <buddyLocatorClass>org.jboss.cache.cluster.NextMemberBuddyLocator</buddyLocatorClass> <buddyCommunicationTimeout>15000</buddyCommunicationTimeout> <buddyLocatorProperties>numBuddies = 3</buddyLocatorProperties> <dataGravitationRemoveOnFind>true</dataGravitationRemoveOnFind> <dataGravitationSearchBackupTrees>true</dataGravitationSearchBackupTrees> <autoDataGravitation>false</autoDataGravitation> <buddyPoolName>groupOne</buddyPoolName> </config> </attribute>
If this configuration element is left empty or is ignored altogether, the BaseRPCInterceptor will revert to replicating to the entire cluster.
The buddyLocatorClass element is optional, and defaults to NextMemberBuddyLocator. The configuration element is provided for future expandability/customisation.
The buddyPoolName element is optional, and if specified, creates a logical subgroup and only picks buddies who share the same buddy pool name. This helps you (the sys admin) assert some control over how buddy selection takes place. For example, you may have 3 power sources in your HA cluster and you may want to ensure that buddies picked are never on the same power source. If not specified, this defaults to an internal constant name which then treats the entire cluster as a single buddy pool.
The buddyCommunicationTimeout property is optional and defaults to 10000. This is the timeout used for RPC calls to remote caches when setting up buddy groups.
The only mandatory property here is buddyReplicationEnabled, which is used to enable/disable buddy replication.
In its simplest form, Buddy Replication could be enabled with:
<attribute name="BuddyReplicationConfig"> <config> <buddyReplicationEnabled>true</buddyReplicationEnabled> </config> </attribute>
Gravitation of data
Data gravitation is implemented as an Interceptor, that sits after the CacheLoaderInterceptor. If data gravitation is enabled for the invocation (more on this in a bit)
the interceptor tests if the node exists in teh cache (after potentially loading/activating it). If not, it will broadcast a data gravitation call for this node and all
subnodes, and proceed to take ownership of it.
Enabling data gravitation for a particular invocation can be done in two ways. Enabling autoDataGravitation (false by default) or by setting an Option (see the Options API).
Finding your buddy
Upon startup, the BuddyManager will use the configured BuddyLocator implementation to help it locate and select its buddy or buddies. Note that the BuddyLocator is only invoked when a change in cluster membership is detected.
Backing up data
To ensure that backup data is maintained separate from primary data on each node, each node will use an internal subtree for each buddy group it participates in, and will contain the name of the Buddy Group it is backing up for. This Buddy Group name is simply a String representation of JGroups Address of the Data Owner of that Buddy Group.
/_buddy_backup_/server01:7890/ /_buddy_backup_/server02:7890/
Also, users would have to ensure that any eviction policies set up are not applied to the /_buddy_backup_ subtree.
Implementation details
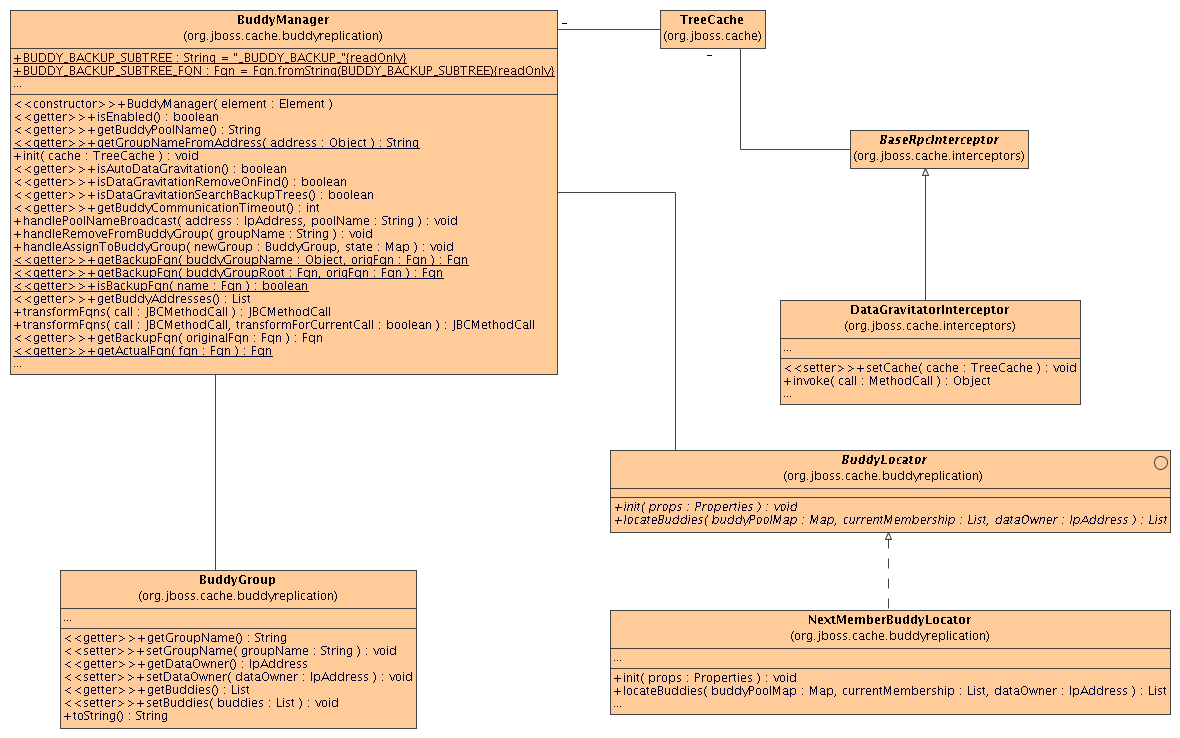
1. TreeCache
The TreeCache class will be enhanced to define 3 new internal methods:
public void _remoteAssignToBuddyGroup(BuddyGroup group, Map state)
public void _remoteRemoveFromBuddyGroup(String groupName)
public void _remoteAnnounceBuddyPoolName(IpAddress address, String buddyPoolName)
The first two methods are called on remote caches (buddies) by Data Owners to add them or remove them from a BuddyGroup.
The last one is called on all remote caches (multicast) every time a view change is detected, so each cache has an accurate map of buddy pools. This method is only called if a buddy pool is configured.
2. BuddyManager
This class controls the group for which a TreeCache instance is a Data Owner as well as all other groups for which the TreeCache instance participates as a buddy. If buddy replication is configured, an instance of BuddyManager is created and referenced by the TreeCache.
The BuddyManager maintains a reference to a single BuddyGroup for which the TreeCache instance is Data Owner, as well as a collection of BuddyGroups for which the TreeCache is a buddy.
Creates a BuddyGroupMembershipMonitor, which implements TreeCacheListener, and registers this monitor to react to changes in the underlying group structure.
Maintains a reference to an instance of BuddyLocator, used to build a BuddyGroup.
3. BuddyGroup
This class maintains a List of Addresses which represent the buddy nodes for the group. The class also maintains an Address reference of the Data Owner as well as a String representing the group name (dataOwnerAddress.toString()?). The class also creates an Fqn which is a backup root for this group, typically being the value of Fqn.fromString("/_buddy_backup_/" + groupName). This is used by BuddyManager.transformFqns(MethodCall call).
This class will be passed over the wire as an argument to RPC calls.
4. BaseRPCInterceptor
When replicateCall() is called on this interceptor, it will only replicate to BuddyManager.getBuddyAddresses() rather than the entire cluster, if a BuddyManager is available. In addition, it will transform the method call it tries to replicate by using BuddyManager.transformFqns(MethodCall call) before replicating anything.
5. BuddyLocator
This interface defines 2 methods:
public void init(Properties p);
which is used to pass in locator specific properties to the implementation on startup.
public List getBuddies(List groupMembers);
selects one or more buddies from a list of group members. End users may extend buddy replication functionality by providing their own buddy locating algorithms.
NextMemberBuddyLocator
Will be shipped with JBoss Cache. Picks a buddy based on who is 'next in line'. Will take in an optional configuration property numBuddies (defaults to 1) and will attempt to select as many buddies when getBuddies() is called. This also takes in another optional configuration property ignoreColocatedBuddies, defaulting to true, which ensures that nodes on the same physical machine are not selected as buddies.
Colocated nodes are detected by comparing their InetAddress properties. We can also detect all the InetAddress instances available on a single host by consulting the enumeration returned by java.net.NetworkInterface.getNetworkInterfaces(). This will conclusively tell us whether 2 cluster members are on the same host or not.
Only buddies who share the same pool name are considered if buddyPoolName is configured.
In the end, buddy pools and ignoring colocated hosts are just hints - if no buddies can be found to meet these constraints, buddies that don't meet these constraints will be tried.
Transferring state
When nominating buddies
When a buddy is nominated to participate in a BuddyGroup (by having its _remoteAssignToGroup() method called), the Data Owner's state will be pushed as an argument of the call. State is then stored under /_buddy_backup_/server01:7890/. Note that this takes place in a separate thread, so that _remoteAssignToGroup() can return immediately.
Changes to state transfer code
One major change in the state transfer code will be to exclude anything under /_buddy_backup_ when marshalling the tree.
Also, when invoked by BuddyManager.assignToGroup(), the state transfer process should be able to store state received in the relevant backup subtree. This may mean overloading the local state transfer method with a root under which state would be stored, defaulting to TreeCache.getRoot(). Note that this does not affect remote state transfer methods so there should be no issue regarding backward compatibility.
Also, with buddy replication, initial state transfers should always be disabled as nodes will pull down state relevant to their BuddyGroups as they are assigned to such groups.
Further Reading and Research References
The following articles and papers were used as sources in understanding other implementations of buddy replication andsimilar mechanisms.
http://www.theserverside.com/articles/article.tss?l=J2EEClustering
http://www.usenix.org/events/hotos03/tech/full_papers/ling/ling_html/index.html
Related wiki pages:
BuddyReplicationAndHttpSessions
BuddyReplicationAndClusteredSSO
(Discuss this design on this forum thread)



Comments