Intro
This page talks about the latest performance improvements in optimistic locking in the upcoming JBoss Cache 1.3.0 "Wasabi".
History
Optimistic locking was first released as a preview technology in JBoss Cache 1.2.4 and while we encouraged people to try it out, we did not recommend it for production use. The feedback we got from this release was invaluable though, and helped us target specific areas for improvement with the 'production' version in 1.3.0.
Where have things improved?
When using optimistic locking in LOCAL mode, things were decisively slower than pessimistically locked configurations. This was due to an excessive overhead when copying node data from memory to a workspace used by the transaction. This has been heavily overhauled.
In addition, the verification process when a transaction commits was inefficient in the way it traversed node trees to look for and validate changes. This too has been heavily overhauled.
The third major bottleneck had to do with merging data froma transaction workspace back into the underlying treecache. Inefficiencies in both node traversal and copying have been worked out and removed.
Where things are now
These problems compounded themselves - and particularly when using cache loaders - made optimistic locking in JBoss Cache 1.2.4 virtually unusable. In addition to other optimisations in the cache loader code, improvements made above ensure that this is no longer the case in JBoss Cache 1.3.0. While an optimistically locked will always be slower than a pessimistically locked one due to the extra processes that go in to handling the concurrency afforded by optimistic locking, it is no longer unusably slow.
Performance tests
A few simple tests show that optimistic locking is a lot closer to pessimistic locking in terms of performance, all using cache mode as LOCAL.
The tests were run on the following environment:
a single server
running SuSE Enterprise Linux 9/2.6 Kernel
2 x 3.06 GHz P4 Xeon CPUs
2GB of RAM.
Sun JDK 1.5.0_05
The format of the tests were:
Perform a number of put()'s, followed by get()'s and then remove()'s, on each iteration on a separate node.
1000 iterations of each are run first as a 'warm up' to bring the JIT up to speed.
5 threads running 10000 iterations each run and measured.
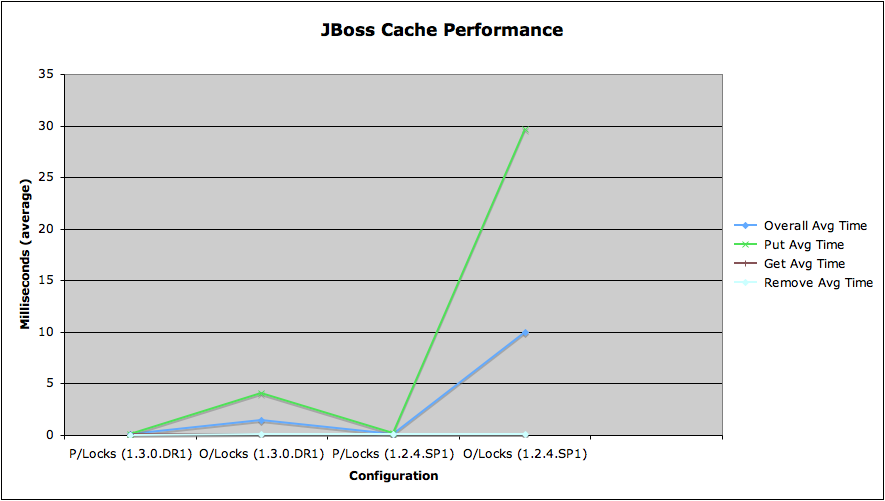
Results
Test Name | Overall Avg Time | Put Avg Time | Get Avg Time | Remove Avg Time |
|---|---|---|---|---|
P/Locks (1.3.0.DR1) | 0.04926 | 0.0537 | 0.07588 | 0.0182 |
O/Locks (1.3.0.DR1) | 1.4313 | 4.0922 | 0.0793 | 0.1224 |
P/Locks (1.2.4.SP1) | 0.121073333 | 0.1741 | 0.07916 | 0.10996 |
O/Locks (1.2.4.SP1) | 9.941566667 | 29.64734 | 0.0704 | 0.10696 |
Comments