Teiid at its core is a distribued query engine. The query engine has support for relational, procedural, XML, and XQuery execution. Most of the development effort has focused on the relational path, but significant effort has also gone into the procedural and XML query execution. See the diagram below for a basic breakdown of the architecture:
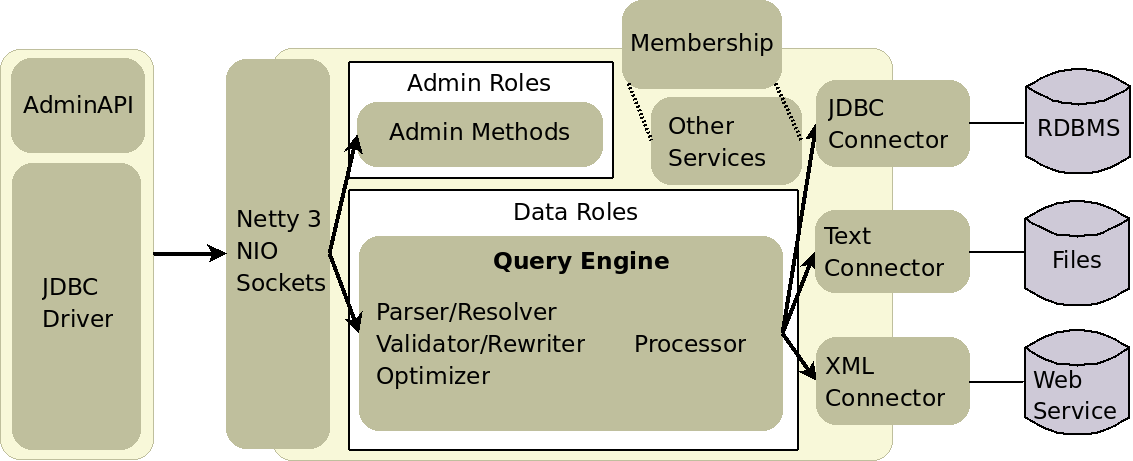
Each of the connectors shown on the right can actually have many instances. Each instance is refered to as a connector binding, which operates independently of all other connector bindings, and is similar to a connection pool to an application server.
The archictecture use separate queues/thread pools (configurable for connector bindings, the socket transport, the query engine, and admin methods) to appropriately scale load.
Direct integration with JBoss Technologies
- Netty3 provides the NIO sockets that supports JDBC and any remote client call.
- JBossTS provides the XA Transaction manager that coordinates imported XA and local XA transactions.
- JBossCache provides the distributed cache implementation backing cluster-wide stores for authentication, result-set, service registry, and other caches.
- JGroups (besides being utilized under JBossCache) provides custer wide messaging.
- The platform product utilizes JON to provide monitoring and a subset of administrative capabilities.
Other notable dependencies
- Guice provides basic DI in service creation and top level classes.
- Beanshell provides the scriptable runtime for the adminshell.
- JavaCC is used to generate the parser for our SQL grammar.
The relational engine's planning and processing facilities are quite similar to what is found in a traditional database. However the focus on planning is on efficient query push-down rather than index utilization or other storage engine details.
Compared to other, more traditional, Java databases Teiid approach is significantly enhaced with respect to:
- Memory Usage – the BufferManager acts as a memory manager for batches (with passivation) to ensure that memory will not be exhausted.
- Non-blocking distributed queries – rather than waiting for source query results processor thread detach from the plan and pick up a plan that has work. Also source queries will be issues in parallel as much as possible.
- Time slicing – plans produce batches for a time slice before re-queuing and allowing their thread to do other work (preemptive control only between batches)
- Caching – ResultSets at the connector and user query level can be reused on a session or vdb basis
Comments