Note: infinispan does not acquire locks for reads, so by “lock” I always mean write lock, i.e. lock that is being acquired when data is written to the cluster.
1.
During a transaction locks are acquired locally before commit time.
E.g. on same node two transactions running:
Tx1: writes to keys {a, b, c} in that order
Tx2: writes to keys {a, c, d} in that order
- these two transactions will execute in sequence, as after Tx1 locks “a” Tx2 won’t be able to make any progress until Tx1 is finsihed.
- remote transactions that need to acquire a remote lock on “a” (for prepare) won’t be able to do any progress until Tx1 (and potentially Tx2) are completed.
Suggested optimization: do not acquire any locks until prepare time. Use same behavior as when reading the keys. This would reduce lock’s scope and give better throughput by allowing more parallelism between transactions.
Also a current problem is that the locking behaviour might affect "only" the local node if this happens to not be an owner, or it could block all other nodes wanting the lock if it happens to be an owner. So the behaviour is different if the node happens to be the coordinator of the involved keys or not.
Note: This optimization is tracked by ISPN-1131 which also contains the suggested design for implementing it.
2.
Non transactional writes from two nodes on the same key (tx situation discussed at a further point).
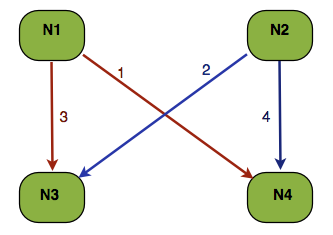
Let’s say we have key “a” so that consistentHash(“a”) = {N3, N4}. Two threads write on key “a” on nodes N1 and N2, at the same time. With the right timing RPCs can take place in the order indicated in the above diagram. Both 3 and 4 deadlock in this case, and the resulting delay won't affect only these keys but also all other locks the two transactions might already have acquired.
Possible optimization:
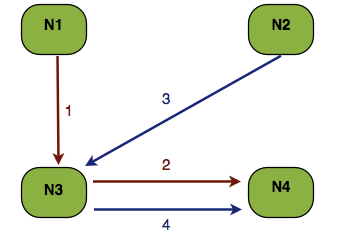
Disregarding numOwners always go to the main owner first (in this case N3). Acquire lock on it and pass it the job of multicast to the remaining nodes:
- this makes sure that there won’t be deadlocks when multiple nodes write on the same key
- user performance is affected as 1 and 2 are now executed in sequence
- optimization stands for high contention on same key
- also valid for situations where async replication is used as it offers better overall consistency and potentially better throughput by not having deadlocks
Note: this solution involves 2RPCs for non transactinable operations. This optimization can be achieved with 2RPCs by using transactions with locking single node, as described by optimization number 4 below. In other words this optimization can be thought of as a particular case of optimization 4.
3.
This one is about another approach for deadlock avoidance. Optimization is for distributed caches, without eager locking (default config).
Tx1: writes on “a” then “b”
Tx2: writes on “b” then “a”
With some “right” timing => deadlock during prepare time.
Suggested optimization:
- during prepare for each transaction order the keys based on their consistent hash value
- acquire the locks in this sequence
- this means that locks are NOT acquired in the order in which the corresponding operation has happened
- this will assure that there won’t be a deadlock between the two transaction
Notes:
- might not work for keys that hash to the same value. For these we can use key’s native hash code - this is valid if Object.hashCode is overridden. Optionally we can expose a pluggable user callback to tell us the ordering.
- this can be extended to replicated and local caches as well.
- it is simpler and more efficient than the current DLD mechanism as it doesn’t force one TX to rollback.
Note: This optimization is tracked by ISPN-1132 which also contains the suggested design for implementing it.
4.
This is similar to 2 but extended to transactions. Let’s say we have Tx1 on node N1 writing to {a,b,c} and Tx2 on N2 writing {d,e,c}. Also consistentHash(c) = {N3, N4}
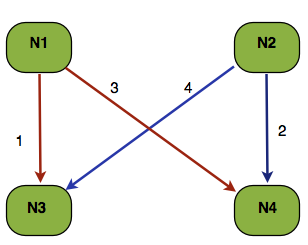
If the prepare RPCs happen in the order shown on above diagram then:
- Tx1 has lock on c@N3
- Tx2 has lock on c@N4
- RPC 3 and 4 block and Tx1 and Tx2 are in a deadlock
- not handled by current DLD mechanism as e.g. on node N4 there’s no way to determine who owns the lock on N3 without querying N3 (RPC) for this.
- what happens?
- locks on {a,b,c,d,e,f} are being held for (potentially) lockAcquisitionTimeout - defaults to 10 seconds
- at least of of Tx1/Tx2 won’t succeed - potentially both!
- bad for throughput!!!
Suggested optimization:
- only acquire lock on the main data owner. mainDataOwner(key) = consistentHash(key).get(0). In the above example the main data owner for “c” is N3
- multicast the prepare message to other backups as well, just don’t acquire locks there.
Given the example, what would be the output with the optimization in place?
Tx1 won’t block on Tx2 when acquiring lock on N4 (RPC 3 in above diagram). It will be able to complete and, after releasing locks allow Tx2 to complete as well.
Note: This optimization is tracked by ISPN-1137 which also contains the suggested design for implementing it.
Comments