Overview
This article describes the architecture and implementation of the clustered service registry used in SwitchYard. If you are interested in how clustering is configured and used in SwitchYard, check out the Clustering documentation.
The purpose of the clustered service registry is to hold information about which services are currently provided in a cluster of SwitchYard instances. The following details are recorded in the registry for each service published:
- Service name
- Domain name
- Endpoint address - the physical access point for the service
- Node name - the cluster node on which the service is deployed
- Service contract - the abstract invocation contract for the service which consists of the message exchange pattern and message types
Registry Operations and Lifecycle
There are three basic operations for the service registry:
- Adding a service endpoint to the registry. This happens when an instance is started and when an application is deployed.
- Query the registry for service details:
- What services are available in a domain?
- What nodes is a service deployed on?
- What are the details (e.g. endpoint) of a given service on a given node?
- Remove an entity is removed from the registry. There are two scenarios here:
- A member has dropped from the cluster. All node entries for the dropped member should be removed from the registry.
- A service has been undeployed. The service entry should be removed from the node(s) where it was undeployed.
Registry Structure and Content
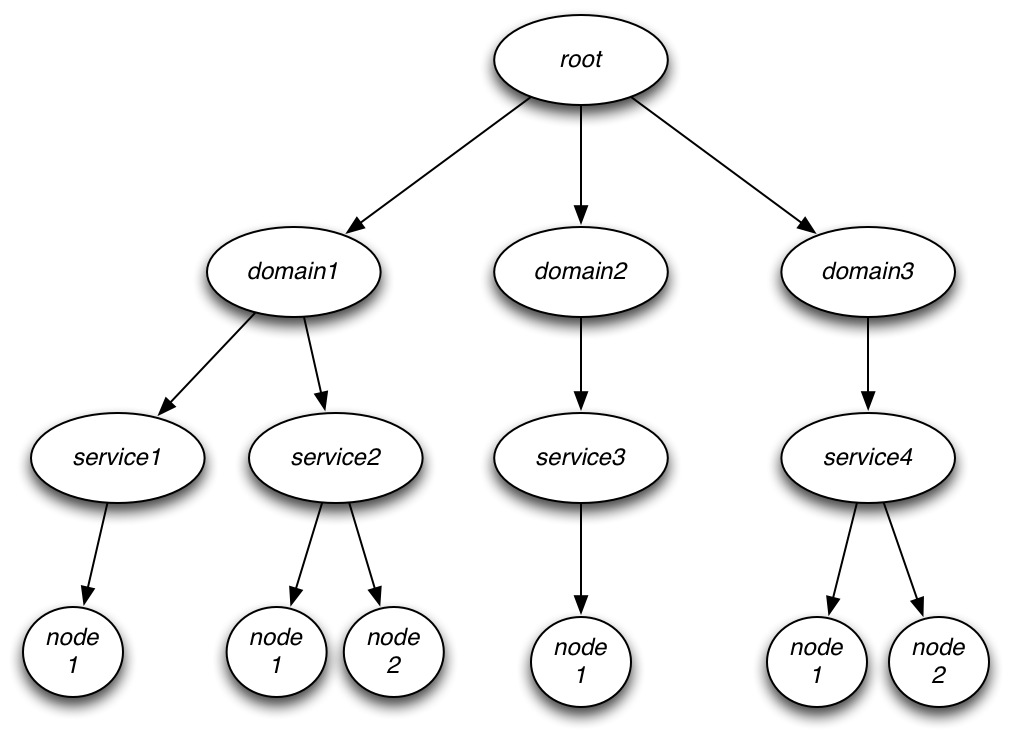
Based on the operations described above, a tree structure works quite well to represent the registry content. An example of a registry tree can be found below. The hierarchy goes like this:
- Root - base of the tree
- Domain - a service domain is a collection of deployed services. Best to think of it as an encapsulation or namespace for services within the registry.
- Service - a service belongs to a single domain and can be deployed on multiple nodes.
- Node - nodes are stored as keys of each service node. If a service is deployed on multiple instances in a cluster, it will have one entry per node.
Implementation Notes
The current implementation of the registry is based on a replicated Infinispan cache. We use the TreeCache API to manipulate the tree for several reasons:
- Querying is straightforward and serialization/deserialization of service details is restricted to the service endpoints returned by the query. For example, querying for all services in domain2 in the above diagram is a tree traversal to get to /domain2/service3 and then serialization of a single result.
- Removal requires no deserializaiton at all.
- The world needs more trees, right?
The registry is expected to reflect the current runtime state of the SwitchYard cluster. Services are added when applications are deployed/started and removed when they are stopped/undeployed. To account for the case of unexpected node failure, we have registred a listener which catches ViewChangedEvents and removes service node entries in response to dropped nodes.
If you're interested in surveying the implementation, check out InfinispanRegistry. The service registration detail which serves as the value of each node entry is RemoteEndpoint. We want tight control over how RemoteEndpoint is serialized, so you'll notice that we have our own Serializer implementation which is used in InfinispanRegistry to store/retrieve RemoteEndpoint as a String in the registry (this is JSON under the covers).
Comments