Introdução
Neste artigo estaremos abordando como o atributo mappedBy do Hibernate funciona, quando usar e quais os seus comportamentos nos mapeamentos OneToOne e OneToMany. Não falaremos do seu comportamento no mapeamento ManyToMany. Este artigo é voltado para quem já conhece o Hibernate, e com isso não nos aprofundaremos em como utilizar este framework, mas em como o atributo mappedBy funciona nos estudos de casos propóstos.
As ferramentas utilizadas para testes fora: Eclipse Neon.2, Hibernate 5.2.7, PostgreSQL 9.5.2.
MappedBy
O atributo mappedBy é utilizado quando temos um relacionamento bidirecional mapeado entre duas classes. Ele é um atributo para ser utilizado nas annotations @OneToMany, @OneToOne e @ManyToMany. Para utilizamos, devemos declarar ele dentro da annotation e informar o nome do atributo da classe utilizada no mapeamento na outra ponta do relacionamento. Abaixo temos um exemplo.
Produto.java
@ManyToOne(cascade=CascadeType.ALL) @JoinColumn(name="venda_id", referencedColumnName="id",nullable=false) private Venda venda;
Venda.java
@OneToMany(mappedBy="venda") private Set<Produto> produto;
Neste exemplo estamos fazendo um mapeamento bidirecional entre as classes Venda e Produto, onde uma venda pode conter vários produtos e um produto somente pode conter uma venda. Neste exemplo, o atributo mappedBy recebe como valor a string “venda”, que é o nome do atributo da classe na outra ponta do relacionamento.
Relacionamento Many to One
No banco de dados relacional, uma relação Many to One (em português Muitos para Um) é constituida pelo compartilhamento do ID das tuplas da tabela pai com as tuplas relacionadas da tabela filha, para este ID servir como chave estrangeira. Ou seja, é criada uma coluna na tabela filha que conterá o ID da tupla da tabela pai. Abaixo temos um exemplo de modelagem de um relacionamento Many to One.
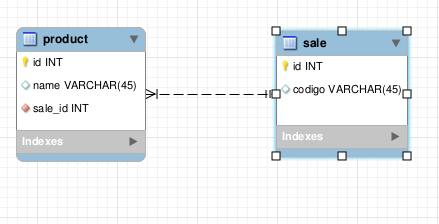
No exemplo acima, a tabela product contém a coluna sale_id para chave estrangeira, que faz referência para o id da tabela sale. Com isso, garantimos que somente exista uma venda para cada produto e muitos produto para cada venda. Sale é a tabela pai e product é a tabela filha.
MappedBy no relacionamento Many to One Bidirecional
Quando criamos um mapeamento Many to One Bidirecional, devemos sempre informar para o Hibernate quem é o pai da relação. Com essa finalidade foi criado o atributo mappedBy. Ao informarmos este atributo na classe, estamos dizendo que a classe é o pai e na outra ponta contém os filhos. Afinal, o @ManyToOne é feito nos filhos. Abaixo teremos o exemplo detalhado da análise de caso utilizando uma tabela chamada product e outra chamada sale.
Classe Product
@Entity
@Table(name="product")
public class Product implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue
@Column(name="id")
private Integer id;
@Column(name="name")
private String name;
@ManyToOne
@JoinColumn(name="sale_id", referencedColumnName="id",nullable=false)
private Sale sale;
@OneToMany()
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Sale getSale() {
return sale;
}
public void setSale(Sale sale) {
this.sale = sale;
}
}
Classe Sale
@Entity
@Table(name="sale")
public class Sale implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue
@Column(name="id")
private Integer id;
@Column(name="codigo")
private String codigo;
@OneToMany(mappedBy="sale", cascade= CascadeType.ALL)
private Set<Product> product;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getCodigo() {
return codigo;
}
public void setCodigo(String codigo) {
this.codigo = codigo;
}
public Set<Product> getProduct() {
return product;
}
public void setProduct(Set<Product> product) {
this.product = product;
}
}
Classe SaleDAO
public class SaleDAO {
public Sale save(Sale sale){
Session sessao= Fabrica.getInstence().openSession();
Transaction transacao=sessao.beginTransaction();
sessao.save(sale);
transacao.commit();
sessao.close();
return sale;
}
}
Classe que contém o método main
public class App{
public static void main( String[] args ){
Sale sale = new Sale();
sale.setCodigo("XYZ");
Product product1 = new Product();
product1.setName("Curso de Hibernate");
product1.setSale(sale);
Product product2 = new Product();
product2.setName("Curso de Java");
product2.setSale(sale);
Set<Product> products = new HashSet<Product>);
products.add(product1);
products.add(product2);
sale.setProduct(products);
new SaleDAO().save(sale);
}
}
Ao executar este código obtemos o seguinte resultado:
select * from product;
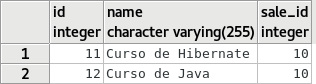
select * from sale;

Como podemos ver, as tuplas foram salvas conforme desejado, e a coluna sale_id da tabela product foi devidamente populada, respeitando o cascade.
Relacionamento One to One
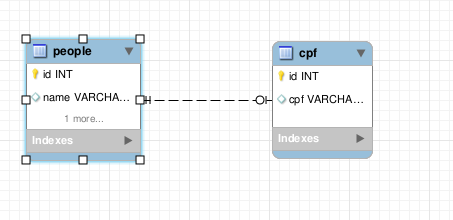
No banco de dados relacional, uma relação One to One (em português Um para Um) pode ser feita de duas maneiras. Uma colocando o mesmo ID nas tuplas relacionadas das tabelas, e a outra criando uma coluna nas duas tabelas para servir de chave estrangeira para tabela relacionada. Abaixo temos um exemplo dos dois casos respectivamente.

No exemplo acima, a tabela people contém a coluna cpf_id para chave estrangeira, que faz referência para o id da tabela cpf, e na tabela cpf contém a coluna people_id para chave estrangeira, que faz referência para o id da tabela people. Com isso, garantimos que somente exista um cpf para cada pessoa e uma pessoa para cada cpf.
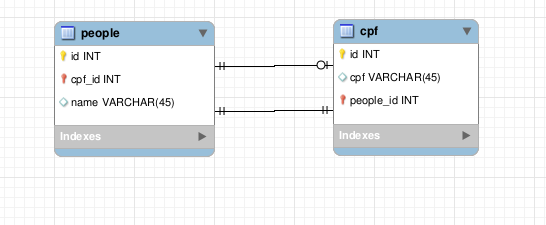
No exemplo acima, a tabela people e a tabela cpf contém o mesmo valor no atributo id, que é a chave primária das tabelas. Com isso, garantimos que somente exista um cpf para cada pessoa e uma pessoa para cada cpf.
O relacionamento One to One é importante quando queremos criar uma modelagem que permita que cada tupla de uma tabela contenha apenas uma tupla relacionada à ela na outra tabela do relacionamento, e vice versa. Um exemplo bom disso é o relacionamento de Pessoa com CPF. Uma Pessoa somente terá um CPF associado a ela e um CPF somente terá uma Pessoa associada a ele.
MappedBy no relacionamento One to One Bidirecional
Quando o mapeamento One to One é feito criando um atributo de chave estrangeira em cada tabela, devemos verificar se a utilização do atributo mappedBy será necessária no nosso mapeamento da Entity, pois como foi falado acima, o atributo mappedBy informa quem é o pai do relacionamento, ou seja, quem terá a sua chave primária referenciada como chave estrangeira na outra tabela. Como neste relacionamento ambas as tabelas recebem a chave estrageira, a utilização do mappedBy não é necessário ou até mesmo inadequado para o caso.
Ao utilizar o atributo mappedBy neste tipo de modelagem de banco de dados, nenhum efeito colateral ocorrerá se não utilizarmos o Cascade. Contudo, se utilizarmos o Cascade na modelagem da Entity, ao salvar a Entity pai, a Entity filha também será salva, porém o atributo de chave estrageira na Entity filha não será salva. Abaixo teremos o exemplo detalhado da análise de caso utilizando uma tabela chamada people e outra chamada cpf.
Modelagem da Base de Dados:
Classe People:
@Entity
@Table(name="people")
public class People implements Serializable {
@Id
@GeneratedValue
@Column(name="id")
private Integer id;
@Column(name="name")
private String name;
@OneToOne(cascade=CascadeType.ALL)
@JoinColumn(name="cpf_id", referencedColumnName="id",nullable=false)
private Cpf cpf;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Cpf getCpf() {
return cpf;
}
public void setCpf(Cpf cpf) {
this.cpf = cpf;
}
}
Classe CPF:
@Entity
@Table(name="cpf")
public class Cpf implements Serializable{
@Id
@GeneratedValue
@Column(name="id")
public Integer id;
@Column(name="cpf")
private String cpf;
@OneToOne(mappedBy="cpf")
@JoinColumn(name="people_id")
public People people;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getCpf() {
return cpf;
}
public void setCpf(String cpf) {
this.cpf = cpf;
}
public People getPeople() {
return people;
}
public void setPeople(People people) {
this.people = people;
}
}
DAO:
public class PeopleDAO {
public People save(People people){
Session sessao= Fabrica.getInstence().openSession();
Transaction transacao=sessao.beginTransaction();
sessao.save(people);
transacao.commit();
sessao.close();
return people;
}
}
Classe que contém a main:
public class App{
public static void main( String[] args ){
People people = new People();
people.setName("Renata");
Cpf cpf = new Cpf();
cpf.setCpf("11111111111");
people.setCpf(cpf);
cpf.setPeople(people);
new PeopleDAO().save(people);
}
}
Como podemos ver, na classe People temos um mapeamento OnetoOne com Cpf, utilizando o atributo cascade=CascadeType.ALL, ou seja, todas as ações feitas no People serão cascateadas no Cpf. Ao executarmos o código obtemos o seguinte resultado:
select * from people;

select * from cpf;

Conforme podemos observar, a coluna people_id não foi populada. Isso ocorreu porque o hibernate entendeu que o pai da relação é a classe Cpf, que mapeia a tabela cpf. É importante lembrar que o mappedBy sempre deverá estar no pai, pois como o pai cede seu id para ser utilizado como chave estrangeira nas filhas, o mapeamento no Hibernate sempre ocorrerá nas filhas, para mapear a coluna que refencia o pai.
Agora, vamos demostrar o mapeamento One to One Bidirecional feito da forma correta, sem utilizar o mappedBy.
Classe People:
@Entity
@Table(name="people")
public class People implements Serializable {
@Id
@GeneratedValue
@Column(name="id")
private Integer id;
@Column(name="name")
private String name;
@OneToOne(cascade=CascadeType.ALL)
@JoinColumn(name="cpf_id", referencedColumnName="id",nullable=false)
private Cpf cpf;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Cpf getCpf() {
return cpf;
}
public void setCpf(Cpf cpf) {
this.cpf = cpf;
}
}
Classe CPF:
@Entity
@Table(name="cpf")
public class Cpf implements Serializable{
@Id
@GeneratedValue
@Column(name="id")
private Integer id;
@Column(name="cpf")
private String cpf;
@OneToOne
@JoinColumn(name="people_id", referencedColumnName="id")
private People people;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getCpf() {
return cpf;
}
public void setCpf(String cpf) {
this.cpf = cpf;
}
public People getPeople() {
return people;
}
public void setPeople(People people) {
this.people = people;
}
}
DAO:
public class PeopleDAO {
public People save(People people){
Session sessao= Fabrica.getInstence().openSession();
Transaction transacao=sessao.beginTransaction();
sessao.save(people);
transacao.commit();
sessao.close();
return people;
}
}
Classe que contém a main:
public class App{
public static void main( String[] args ){
People people = new People();
people.setName("Roberta");
Cpf cpf = new Cpf();
cpf.setCpf("22222222222");
people.setCpf(cpf);
cpf.setPeople(people);
new PeopleDAO().save(people);
}
}
Ao executarmos este código obtemos o seguinte resultado:
select * from people;

select * from cpf;

Como podemos reparar, uma nova tupla foi adicionada nas tabelas people e cpf. Contudo, na tabela cpf, diferente da tupla de id=2, a nova tupla (de id=6) contém a coluna people_id populada com o valor 5, que é o id da nova tupla na tabela people, alcançando assim o objetivo desejado.
Já o mapeamento One to One bidirecional utilizando o mesmo ID nas tuplas relacionadas das tabelas (Associação por ID) temos o seguinte código:
Classe People
@Entity
@Table(name="people")
public class People implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue
@Column(name="id")
private Integer id;
@Column(name="name")
private String name;
@OneToOne(cascade=CascadeType.ALL)
@PrimaryKeyJoinColumn
private Cpf cpf;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Cpf getCpf() {
return cpf;
}
public void setCpf(Cpf cpf) {
this.cpf = cpf;
}
}
Classe Cpf
@Entity
@Table(name="cpf")
public class Cpf implements Serializable{
private static final long serialVersionUID = 1L;
@Id
@Column(name="id")
@GenericGenerator(strategy="foreign",name="generator",parameters=@Parameter(value="people", name = "property"))
@GeneratedValue(generator = "generator")
private Integer id;
@Column(name="cpf")
private String cpf;
@OneToOne(mappedBy="cpf")
private People people;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getCpf() {
return cpf;
}
public void setCpf(String cpf) {
this.cpf = cpf;
}
public People getPeople() {
return people;
}
public void setPeople(People people) {
this.people = people;
}
}
Podemos reparar que neste código há as seguintes linhas:
@GenericGenerator(strategy="foreign",name="generator",parameters=@Parameter(value="people", name = "property")) @GeneratedValue(generator = "generator") private Integer id;
Estas linhas informam para o Hibernate que o id será o valor vindo da chave estrangeira (foreigh key), e que o propriedade da classe que representa esse relacionamento é a propriedade “people”. Este código gera o seguinte resultado:
select * from people;
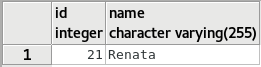
select * from cpf;

Conclusão
A utilização do mappedBy é necessário em quase todas as possibilidades de mapeamento bidirecionais, porém quando utilizamos um mapeamento One to One bidirecional em que cada tabela do relacionamento tem uma coluna de chave estrangeira para a outra ponta do relacionamento, o mappedBy não é recomendado, pois trará efeitos colaterais quando for feito o uso de cascades. Com isso, orientamos que seja feita uma análise mais cautelosa quando existir este tipo de relacionamento.
Bibliografia
Comments