[ We already had some discussions in the last few days, but also in the past - have a look at the "Relationship service", "Dependent Resources" and also "Design agentless management" in the RHQ wiki. ]
A resource in the following is regarded in the RHQ way as a managed entity. This may be represented by 0..n resources in other systems.
RHQ
Current RHQ uses a hierarchical inventory model which is basically a forrest with trees that have resources of category "platform" (= host) as roots.
Each agent that is running on a host to manage resources on it, maps to such a platform resource.
A resource is defined by a static resource type inside a plugin. The resource type defines the capabilities of a resource via facets (metrics, operations, ...).
This obviously has its drawbacks:
- RHQ assumes in many places that an agent is managing the resource, neglecting the fact that resources could also be created via the REST-api without any agent.
- While in the model, there is no real way of expressing a host with many virtual guests that are in fact also platforms. The host + the guests can all appear in the forrest, but there is no way to express that if the host goes down, all guests also go down.
- The hierarchical model does not allow to specify things that logically belong together, but which may have different parents.
Take the example of an application that consist of a load balancer, three application servers and a database.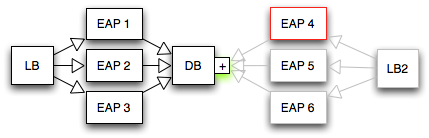
In this example the database is also shared with another application. - Resources are relatively static. The developer needs to know at development time which metrics or operations a resource will have. This does not allow to just import an arbitrary MBean or SNMP-entity as the names and numbers of properties are not known at plugin design time.
A strong trait of the current model is the existence of metadata, that allows to describe a resource and its properties by textual descriptions, but also with e.g. units, default values or lists of allowed values.
Requirements for a future model would be:
- allow to provide metadata for resource and
- allow to express parent child relations as today
- allow to group (similar) resources together as today
- allow to group resources together into applications. Note that this is different from what we see today as a mixed group, as there are dependencies e.g. in the are of availability, where the application can still be available if one application server fails. The resource model must allow to show those dependencies
- allow to statically define resource types with metadata
- allow to define resource (types) on the fly from an editor or by querying e.g. an mbean server
- provide out of the box support for multiple tenants. Tenants can be completely different users / customers, but could also be different organizational units
The above basically consits of two larger areas:
- defining a resource
- defining relationships between resources
The next question is what properties does a resource have to have. And so often we can not know the answer in advance. Most probably those attributes should be present:
- (technical) unique identifier(s) like a uuid - with a namespace (e.g. "{rhq}dead-beef" or {fabric8:c0de-cafe}. This allows to interact with other systems and to link a resource in RHQ with the resource in the other system
- display name
- human readable description
- owner / tenant: This is to limit access to resources by users of a tenant.
- list of key-value pairs, that provide additional properties
- resource url that specifies how to reach the resource to operate on it. We need to define custom schemas like dmr:// if they do not yet exist.
Relationships between resources
Relationships in the model can be seen as a graph with the resources being nodes and links pointing to the other resource. Links will get names or tags identifying the relationship to the other resource. Take the following image as an example:
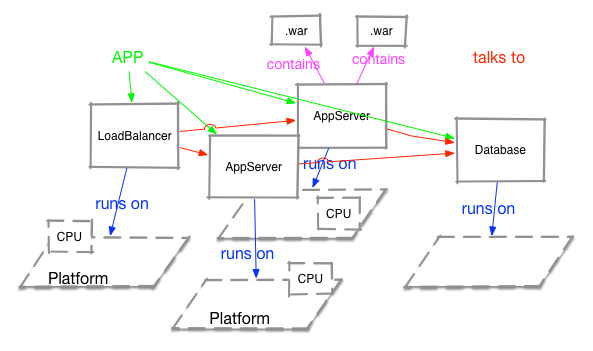
Here we have an application that consists of 4 components. We have links denoting the application (is "application" itself a resource?) with relationships "talks to". Then there are "runs on" relations as well as "includes". Depending on what is needed, we need to filter on the tags/names of the links.
There are already some relations depicted above. Another one could be "starts before" to indicate that the DB must be up before starting the application servers.
It must be possible to insert new resources in the graph. E.g in above drawing it must be possible to insert a third application server or a apache httpd in between load balancer and the application servers.
While discovery should find out as much as possible for those relations, we need to provide a manual way of manipulating the links.
Relationship of the resource / inventory model to other management systems
RHQ.next will not (always) live alone, but users may have other systems deployed like Fabric8, Red Hat Satellite, manageIq or others. In such a scenario, there may be a need to query the other system to gather data of a resource or to ask the other system to provision new data onto the resource.
As stated above, we need a way to identify the resource in the other system and mark it as "the same". We probably also need an indicator which system "owns" the resource and if multiple systems have data, an idea what data we can get from where.
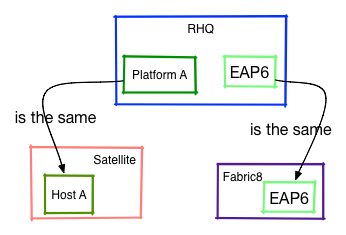
With this information at hand, it will then be possible to e.g. tell Satellite to deploy a new rpm on what is known as "Plattform A" inside RHQ and then to tell Fabric8 to deploy an additional web application onto the EAP6 resource.
Model elements
What model elements do we need? Above we have identified the Resource and the Application.
Groups are a strong point in RHQ as well. Do we need to have explicit Groups or can they just seen as a special graph where all resources have a "member of" link pointing to what? The current DynaGroup language is certainly a plus that we should keep (and extend).
Additional (meta) data
The above only talks about resources and how they interact with each other. In reality resources do not exist inside management systems just for the joy of it, but because there are actions to be performed on them: run operations, provision data, take measurements and show their availability status. All of this needs additional (meta) data.
Now we have projects like RHQ metrics that are used to store (and display) metrics. The inventory needs to know what metrics are supposed to go there and may also need to specify collection intervals ("schedules") for metric taking (this could also go into RHQ Metrics though). I guess individual metrics need also to have an URL (Rest endpoint of RHQ Metrics) to identify and address it. The metadata of the metric itself (units, trendsup/dynamic, derived metrics) needs to live in RHQ Metrics though as e.g. display code needs to access it from there.
Similar for alerting. Inventory needs to have a link with alert definitions per resource, but the individual alert definition will live in the alert engine. The engine will work on individual incoming data items (e.g. metrics, logfile line, availability record). When creating the final alert object it may or may not need input from the Inventory to e.g. include resource name into the alert message.
Security / Access control
Access to resources and facets like operations or recored metrics may have the need to be protected.
Current RHQ already has a pretty good RBAC system, EAP another one.
Access roles of a user are per tenant id. A user can have access to multiple tenants though. Imagine individual OpenShift users as individual tenants and then an administrator that is monitoring the OpenShift platform itself which should be able to see metrics from multiple tenants.
For operations we need to make sure that the access control is per operation, as there are more dangerous ones ("reboot") that only users with elevated rights should be able to trigger. We need to investigate if such differentiation in rights should be applied to other areas as well (e.g. user can only see certain metrics of a resource).
I guess that a relatively generic setup can be used here
{namespace}:item-id:(tenant,access level)+where the namespace defines the item class (metrics, alert, alert def, operation, ...) the item-id identifies the item and then there is the list of the access rights.
Inventory storage
While it is probably a bit too early to talk about future storage, it is clear that the actual hierarchical model inside a relational database with recursive queries has its drawbacks.
Comments