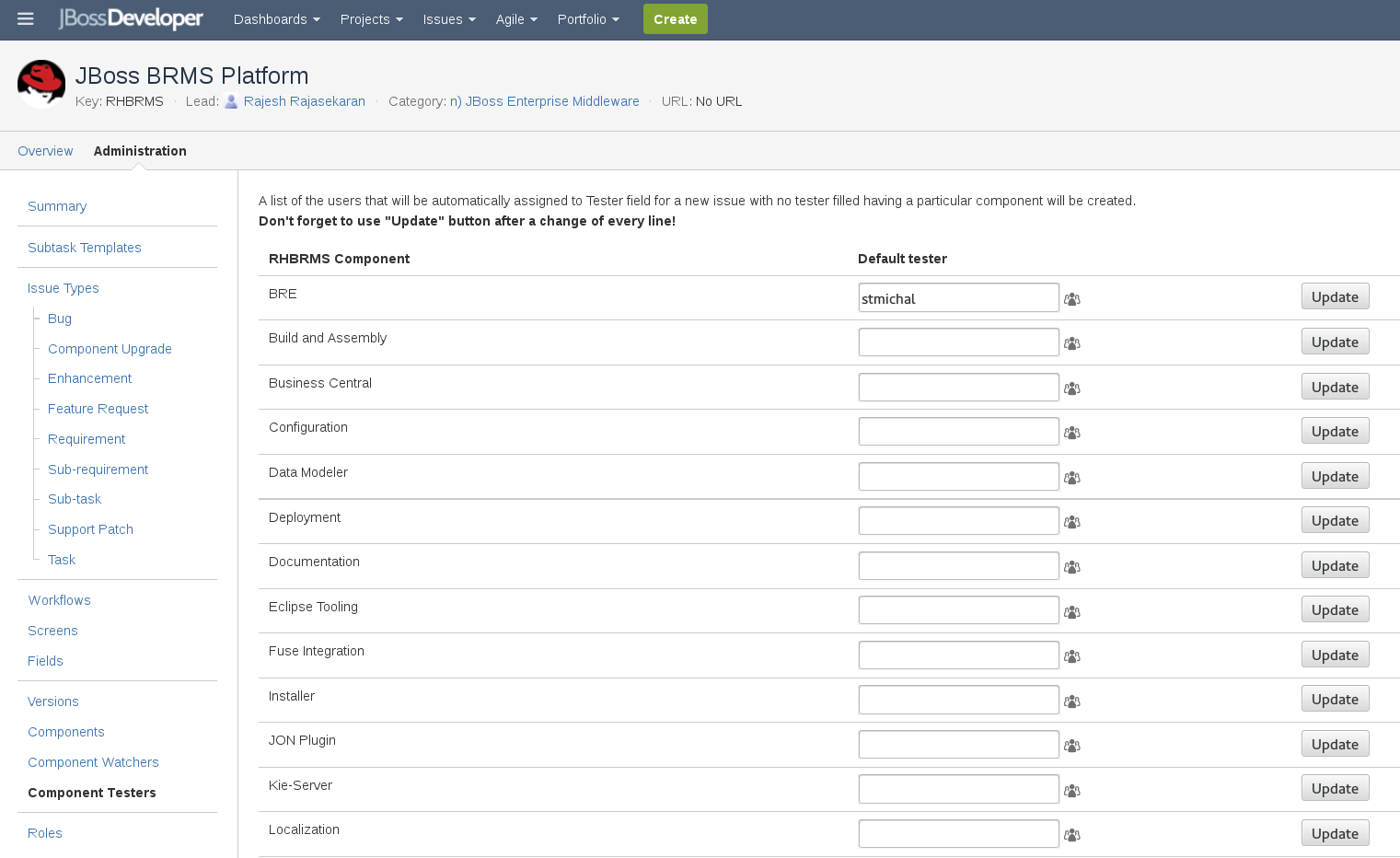
Two weeks ago two independent teams ran into the same issue. They deployed artifacts to repository.jboss.org and then they found out, that their builds are failing, because Maven was not able to download some of the checksums. "repository.jboss.org" is an Apache instance, that load balances two Nexus proxy servers to mitigate the load. Both proxy servers read the data from a single master server.
It took us some time to find the reason, because not all check sums were missing and to make things even more interesting, some checksums were missing on just one of the proxies and some on both. Also in some cases sha1 checksum was missing, while md5 was present and vice versa...
We have a good news and a bad news for you. The good news is the builds will no longer crash due to "not found" checksums. Bad news is unless https://issues.sonatype.org/browse/NEXUS-7654 is resolved, directory listings on repository.jboss.org artifacts may not be accurate and it may have missing directories (they do not affect builds, just browsing with a web browser).
What Went Wrong?
For all the servers we use Sonatype Nexus version 2.7. If I want to explain the problem it is important to explain how the Proxy Repository with Smart Proxy feature works.
Proxy Repository works like a cache. You build some project with a dependency on some artifact. Maven has a deterministic way how to calculate the URL of the downloaded file (artifact). Your Maven client calculates this URL and tries to download the file from the calculated location in your proxy server.
Now two things can happen - the proxy repository already has the file and your Maven client downloads it from this location. Or the file is not present in the proxy repository on that URL. The proxy repository has "remote repository" defined. If the file is not found locally, Nexus tries to find the file in the remote repository. Then it either returns and stores the artifact or return not found to your client.
Nexus also knows, that if it downloads an artifact, there may be checksums available for it. The checksum is calculated as <URL of your artifact> + ".md5" or <URL of your artifact> + ".sha1". When Nexus downloads your artifact, it also remembers, if the checksums were present for this artifact.
I mentioned a Smart Proxy Feature. Normally the proxy repository remains empty, unless someone builds his project and his Maven client downloads some files from the proxy. With each build, the proxy repository is slowly filled with artifacts that are requested. This is useful, because if you for example use Maven Central as the remote repository, your proxy server is not flooded by zillions of artifacts from the remote, that no one uses. However directory listings on the proxy server do not display the directory listings of the remotes, but the artifacts cached locally. This means builds are OK, but people browsing such repository often complain about "missing artifacts".
Smart Proxy feature allowed us to solve this problem. Whenever someone deployed artifacts to the master server (= remote repository for the proxies), the smart proxy immediately pushed those to the configured proxy servers. However here lies the pitfall.
In the current version of Nexus when artifacts are released, they are pushed to the proxy servers immediately. Proxy server also checks for existence of checksums, however in some cases the proxy server checks for their existence after the master server releases the artifact but before the master manages to properly release the checksums. The proxy server marks a note the artifact does not have the checksum even if it should have it. And in case your Maven client is configured to always check the checksums, your build will fails.
How We Fixed the Problem
Ideal solution would be to fix the Smart Proxy feature. This will be done sooner or later by Sonatype, you can monitor the progress here https://issues.sonatype.org/browse/NEXUS-7654. However I needed it to be fixed now so the builds do not fail anymore. I had to disable the smart proxy feature for now. That way the artifact is requested by the nearest build and it is very unlikely to happen a microsecond after the artifact is published. That way the master server has enough time to release the checksums as well.
The builds will no longer fail, however due to the continuous populating of the proxy repositories directory listing will not always display all available artifacts. And do you remember I mentioned we have two proxy servers behind a load balancer? If you think it might mean one directory listing could possibly display different artifacts when accessed several times (the same URL), you are right.
There is a way how to fix this, but the way is very annoying. If you are a team leader you should consider it though. After you release your artifacts, you need to download all of them from both proxy servers.
Their URLs are proxy01-repository.jboss.org and proxy02-repository.jboss.org. You have to be in Red Hat intranet and you might have to add those two to your hosts file. The IP address of both is 10.38.5.26.
Final Word
I would like to thank vladimir_v and Rich Seddon (and his colleagues) from Sonatype for their help during the investigation of the problem. As soon as https://issues.sonatype.org/browse/NEXUS-7654 is fixed and I will update our Nexus to the fixed version and re-enable smart proxy so the both proxy servers become automatically populated again.