All Places > Website > Blog > Authors
dhladky
Two weeks ago two independent teams ran into the same issue. They deployed artifacts to repository.jboss.org and then they found out, that their builds are failing, because Maven was not able to download some of the checksums. "repository.jboss.org" is an Apache instance, that load balances two Nexus proxy servers to mitigate the load. Both proxy servers read the data from a single master server.
It took us some time to find the reason, because not all check sums were missing and to make things even more interesting, some checksums were missing on just one of the proxies and some on both. Also in some cases sha1 checksum was missing, while md5 was present and vice versa...
We have a good news and a bad news for you. The good news is the builds will no longer crash due to "not found" checksums. Bad news is unless https://issues.sonatype.org/browse/NEXUS-7654 is resolved, directory listings on repository.jboss.org artifacts may not be accurate and it may have missing directories (they do not affect builds, just browsing with a web browser).
What Went Wrong?
For all the servers we use Sonatype Nexus version 2.7. If I want to explain the problem it is important to explain how the Proxy Repository with Smart Proxy feature works.
Proxy Repository works like a cache. You build some project with a dependency on some artifact. Maven has a deterministic way how to calculate the URL of the downloaded file (artifact). Your Maven client calculates this URL and tries to download the file from the calculated location in your proxy server.
Now two things can happen - the proxy repository already has the file and your Maven client downloads it from this location. Or the file is not present in the proxy repository on that URL. The proxy repository has "remote repository" defined. If the file is not found locally, Nexus tries to find the file in the remote repository. Then it either returns and stores the artifact or return not found to your client.
Nexus also knows, that if it downloads an artifact, there may be checksums available for it. The checksum is calculated as <URL of your artifact> + ".md5" or <URL of your artifact> + ".sha1". When Nexus downloads your artifact, it also remembers, if the checksums were present for this artifact.
I mentioned a Smart Proxy Feature. Normally the proxy repository remains empty, unless someone builds his project and his Maven client downloads some files from the proxy. With each build, the proxy repository is slowly filled with artifacts that are requested. This is useful, because if you for example use Maven Central as the remote repository, your proxy server is not flooded by zillions of artifacts from the remote, that no one uses. However directory listings on the proxy server do not display the directory listings of the remotes, but the artifacts cached locally. This means builds are OK, but people browsing such repository often complain about "missing artifacts".
Smart Proxy feature allowed us to solve this problem. Whenever someone deployed artifacts to the master server (= remote repository for the proxies), the smart proxy immediately pushed those to the configured proxy servers. However here lies the pitfall.
In the current version of Nexus when artifacts are released, they are pushed to the proxy servers immediately. Proxy server also checks for existence of checksums, however in some cases the proxy server checks for their existence after the master server releases the artifact but before the master manages to properly release the checksums. The proxy server marks a note the artifact does not have the checksum even if it should have it. And in case your Maven client is configured to always check the checksums, your build will fails.
How We Fixed the Problem
Ideal solution would be to fix the Smart Proxy feature. This will be done sooner or later by Sonatype, you can monitor the progress here https://issues.sonatype.org/browse/NEXUS-7654. However I needed it to be fixed now so the builds do not fail anymore. I had to disable the smart proxy feature for now. That way the artifact is requested by the nearest build and it is very unlikely to happen a microsecond after the artifact is published. That way the master server has enough time to release the checksums as well.
The builds will no longer fail, however due to the continuous populating of the proxy repositories directory listing will not always display all available artifacts. And do you remember I mentioned we have two proxy servers behind a load balancer? If you think it might mean one directory listing could possibly display different artifacts when accessed several times (the same URL), you are right.
There is a way how to fix this, but the way is very annoying. If you are a team leader you should consider it though. After you release your artifacts, you need to download all of them from both proxy servers.
Their URLs are proxy01-repository.jboss.org and proxy02-repository.jboss.org. You have to be in Red Hat intranet and you might have to add those two to your hosts file. The IP address of both is 10.38.5.26.
Final Word
I would like to thank vladimir_v and Rich Seddon (and his colleagues) from Sonatype for their help during the investigation of the problem. As soon as https://issues.sonatype.org/browse/NEXUS-7654 is fixed and I will update our Nexus to the fixed version and re-enable smart proxy so the both proxy servers become automatically populated again.
People report a bug that when they refresh Maven repository in their web browser (repository.jboss.org), they get different results (missing artifacts). This appears like a big bug, however I would like to shed light into this rather cosmetic problem.
It is caused by our new infrastructure behind repository.jboss.org. Originally there was just one server that handled artifacts. As the load increased this solution started not to be good enough. Therefore we added two proxy machines in front of the original one. They serve as mirrors for the original instance and they are load balanced by Apache. A classical mirror is a complete copy of all artifacts. The proxy machines are not classical mirrors though. The files are served using proxy repositories of Sonatype Nexus, that stores just content people ask for on the machines. When an artifact is requested, Nexus delivers it from the local content and if he does not find it locally it tries to obtain it from the master. However directory listing in the web browser is always served from the locally stored content.
And this is the reason, why the two machines have different directory listing. If one artifact is requested by someone the load balancer uses one of the mirrors and the artifact is added to the directory listing of that particular instance. But when one display the repository listing and then refreshes it, what may happen is that the listing will be displayed from the second instance, that does not have the artifact yet .
So i you worry about your builds - no worry! Both mirrors are identical and always return all the requested artifacts (even if it appears they are not there). Browsing the repositories using web browser may be confusing though. I will fix the issue somehow buthe builds are fine so the problem is not that big as it appears to be.
Today we switched to the new hardware for repository.jboss.org. Two new dedicated servers now serve artifacts to the whole community.
We are happy, that we achieved a significant increase of request handling speed. After one hour of service there are no errors reported yet, but, please, if you find something odd, report it to help@jboss.org so we can investigate it.
As we announced a week ago, we switched repository.jboss.org to a new hardware. Unfortunately our Apache does not seem to handle current load and so we are switching back to the original hardware. We are sorry for any inconvenience during the last hour.
There were troubles in the past with repository.jboss.org Maven repository, because the server was heavily overloaded by requests from the community. We did quite a lot of optimizations. A part of the load has already been removed by adding Akamai infrastructure in front of product artifacts. Also we added some automatic cleaning tasks to the system and optimized authentication plugin. As a result the server is now quite stable. Calling it fast would be exaggerating though. But there is a hope.....
Next week (2014-07-14 12:00 PM UTC) we scheduled switching the load from one old machine to two brand new servers that would split the load between one another. Why I am writing about it? Well it is a good news for anyone using repository.jboss.org but on the other hand there might be a risk of some issues we are not aware yet.
So I would like to ask project leaders: if you plan some important event on Monday July, 14th (release, conference etc.), please, contact me so we can reschedule the hardware changes to some "safer" date.
Jboss Maven repository (repository.jboss.org) supposed to have three levels of users of staging profiles. Anonymous users had no rights to Nexus staging suite. A JBoss Developer group was supposed be able to deploy artifacts to staging group and a Productization group was supposed to be able to release and promote staging artifacts.
However for some historical reason the last two groups were merged together allowing the developer group to be able to release and promote artifacts as well.
After the server upgrade today, these two groups will be distinguished again. So that means it is possible it may affect your work - it did not matter, if you had been just in the "JBoss Developer" group before, but if so and you need to release or promote staged artifacts, you need to ask me (e-mail to help(at)jboss.org) and your project leader (to confirm your privilege).
Right now anonymous users have read access to all the artifacts on this server. This policy is about to be changed. The old repositories, that were accessible will remain accessible for anonymous users in future and also some other repositories will be added.
However some of the new repositories will not be accessible for general public (they will contain immature testing stuff). Why am I writing about a change, that most of the people will not even notice?
The thing is I might have missed something. If you want to know if your project will be OK, you can try to build it using "jboss-anonymous" account (password "anonymous") instead of the anonymous access. If it fails due to missing rights, please, report the issue here.
Pages like http://www.jboss.org/gatein/downloads/gateinportal.html or http://www.jboss.org/drools/downloads use a nice "Directory listing" paragraph. This paragraph mirrors a file system and keeps the download pages up-to-date without the actual page to be manually updated. This paragraph was introduced by Jozef Chocholáček, but in the next release (= 7.8.0 Magnolia) several enhancements and fixes were done. The release will go public on Wednesday December 5th at 2:00 PM (CET).
Latest release hightlight
This feature was present in the previous version, but it was completely overhauled. It is backwards compatible thought. You can place a hightlight to the new version of your product between the paragraph title and the directory listing. Originally the highlight text was hard-coded to "Looking for the latest version? Download". Now it is just a default text, but you can change it to whatever you want. Also originally it was possible to higlight just one link, now it is up to you how many of them you want to use.
How to set this up? First of all you need to have a file lastRelease.properties in the root directory of your project. If this file is found, it is not displayed in the paragraph, but its content is parsed and used to set the content of the paragraph instead. Why are those settings in the filesystem and not in the Magnolia paragraph dialog? It is likely the latest versions are generated and deployed by some automatic process. And while it is easy to just copy one more file to some directory, it would be much harder to modify things in a web form automatically.
OK. So we have this lastRelease.properties file. It is a classical property file, where on each line you write a key, "=" character and after it its value. The lastRelease.properties has following keys:
| Key | Description |
|---|---|
| lastRelease | A link to the page with the last release. The URL can be either absolute (in that case no processing is done on it) or relative. If it is relative a base URL is added to the link (in case of JBoss pages it is http://downloads.jboss.org). If this key is missing, the latest release will not be highlighted and just the directory listing will be displayed in the paragraph. |
| lastReleaseText | If ommited, this key defaults to "Looking for the latest version? Download ". If you specify it, your text will be displayed prior to the link on the web page. |
| lastReleaseURLText | While lastRelease specifies the URL to the latest release, the path might not be pretty for human readers. Therefore you can specify a text, that will be displayed in the web browser. If ommited, the paragraph tries to dig some pretty name from the lastRelease value, but the result will not be as nice as if you specify it yourself. |
If you need more links to the latest versions (i.e. your project has several parts and you want to highlight each part), now you can add numbers to the key after the name starting with 0 and increasing by one in the lastRelease.properties file. The paragraph will render all the highlights unless finds a missing number. So if you specify lastRelease0, lastRelease1 and lastRelease3 keys, the first two will be displayed, but lastRelease3 will be ignored, because lastRelease2 is not present.
The keys lastReleaseText and lastReleaseURLText have their numbered variants and of course the number binds all together. However the defaults are slightly different here, because the long texts are not good if used several times:
| Key | Description |
|---|---|
| lastRelease<n> | A link to the page with the last release. If ommited, lastRelease<n+1> and the higher will not be processed. |
| lastReleaseText<n> | The text prior to the link.It defaults to lastReleaseURLText<n> with ": ". If neither lastReleaseURLText<n> is specified, the default value of lastReleaseURLText<n> + ": " is used. |
| lastReleaseURLText<n> | Similar to the unnumbered lastReleaseURLText. |
Example:
lastRelease=http://absolutepath.some.org/dir/subdir
lastReleaseText=Download the newest version here:
lastReleaseURLText=Latest Release
lastRelease0=latest0
lastRelease1=latest1
lastReleaseText1=Latest release 1:
lastRelease2=latest2
lastReleaseText2=Latest release 2:
lastReleaseURLText2=Download
Will render as
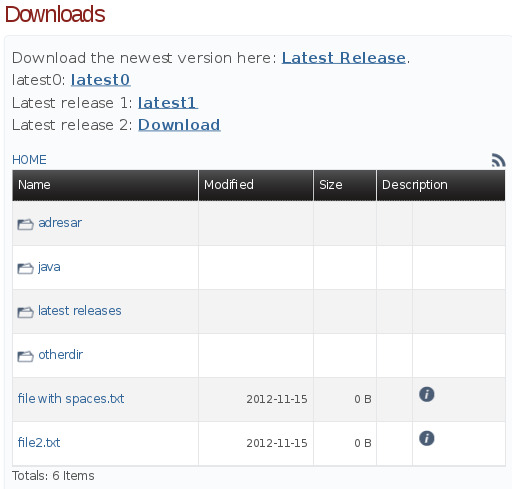
What you can not see on the picture are the values of the links. So the first link (under Latest Release) will be as http://absolutepath.some.org/dir/subdir, because the path was absolute and therfore unchanged. The second highlight is not nice, because lastReleaseText0 and lastReleaseURL0 were not specified and latest0: latest0 is the best what the paragraph was able to dig out from it. The URL under latest0 will be http://downloads.jboss.org/latest0, because the link is relative. The remaining two highlights are better, because the values are specified.
Note: the numbered and unnumbered keys are independent. You can use just numbered, just unnumbered or both variants.
Enough about the last release highlights. I need to explain some other new feature before I will be able describe some magic you can do with those highlights.
More directory listing paragraphs on a single web page
The old directory listing paragraph was supposed to be alone on a web page. Also it interfered with another Magnolia paragraph, but it is another story. It was not mentioned anywhere, so some users put several directory listing paragraphs on a single page. When someone navigated within the directory structure displayed in the paragraph, that paragraph displayed the content of the chosen subdirectory (correct), but the other paragraphs reported errors, because they tried to search for the same subdirectory in their part of file system, but they did not have it.
Now the navigation is independent in each paragraph. Originally "dir" attribute was added to the URL of the download page. E.g. http://localhost:8080/exampleformpage.html?dir=java caused the paragraph to render the content of the "java" directory. Now it changed. The dir attribute now holds the identification of the paragraph. I.e. if we have two paragraphs on the single page, the URL might look like http://localhost:8080/author/exampleformpage.html?dir=01%3Ddownloads%3B00%3Djava%3B. The URL says, that in the paragraph 01 downloads subdirectory should be displayed and the paragraph 00 should display the java subdirectory. It looks horrible, but %3D is "=" and %3B is ";". So if you hover your mouse above the link in your browser, you will see something like http://localhost:8080/author/exampleformpage.html?dir=01=downloads;00=java; . I think that makes things clear.
The promised "directory listing magic"
In case you know how the dir parameter works, you may use this knowledge to construct the URL to your "latest release highlight" section. And if I speak about this feature as "latest release", the reason why you have it there may be completely different. I.e. if you have a project with several logical parts - one with a validation, second with a persistence or whatever.
The easiest way how to use it is to find the directory with the content you would like to highlight in the web browser. Copy the link and use it into your lastRelease.properties file. Keep in mind that that way you can set all the directory listing paragraphs of a single page.
Complete list of directoryListing paragraph changes in the new version
(just in the case someone cares).
- fixed crashes when serveral directoryListing paragraphs were on the same page
+ when date is selected as a sorting column, a file name is a secondary column
- fixed a problem with broken colors after sorting in directoryListing paragraph
- removed several possibilities to crash directoryListing paragraph by adding wrong paths
+ if more than just one directoryListing paragraph are present on a page, user can navigate independently in each. The system rembers the position in each paragraph instead of displaying an error
- fixed a problem with expanding of checksums of files, that have the same checksum (a completely different div on the page was expanded)
* newer version of Modeshape library is used
+ added some info about how to use the paragraph into Magnolia form of the paragraph.
- fixed a problem with spaces in the latest release highlight links.
http://www.jboss.org uses a plugin, that displas the last tweets from #jbossdeveloper. Very nice and useful plugin. However Jaikirian Pai suggested, that it would be nice, if the displayed Twitter account name was clickable and led to the user's profile. It was good idea. However it took some time to find out how to do that. Twitter has some documentation, but the features they describe do not include this (well at least it is well hidden and so I was unable to find it there).
So I thought this article might help you, if you want to do the same thing. If you know the user's account number, you can use following link:
http://twitter.com/account/redirect_by_id?id=<account number>
I.e. my profile is http://twitter.com/account/redirect_by_id?id=612507302
It is really just that easy, if you know the link.
And how to get the account number? Well there are many ways. If you are in Java, twitter4j can be pretty handy. But this is another story, that depends on what you have at your disposal. Or if you just want yours, you can use this web page http://www.idfromuser.com. Remember to use @ before your name.
http://www.jboss.org runs mainly on Magnolia CMS. It is a web application, that runs on JBoss application server. Eng-ops (= the team responsible for maintaining infrastructure) reported, that logging does not work properly (the bug), because the logs are larger and larger and they are becomming huge. Jozef, the former colleague of mine, updated the configuration of the application server. We use log4j so the whole thing did not appear to be complicated. But the reality is sometimes quite interesting and so this issue remained unsolved for quite a long time.
Prequel - console.log is too long
First information I got was, that console.log is too long and everything from Java is logged into it. What I found in jboss-log4j.xml was very interesting:
<!-- ============================== -->
<!-- Append messages to the console -->
<!-- ============================== -->
<!-- appender name="CONSOLE" class="org.apache.log4j.ConsoleAppender">
<errorHandler class="org.jboss.logging.util.OnlyOnceErrorHandler"/>
<param name="Target" value="System.out"/>
<param name="Threshold" value="INFO"/>
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%d{ABSOLUTE} %-5p [%c{1}] %m%n"/>
</layout>
</appender -->
.............................
<!-- ======================= -->
<!-- Setup the Root category -->
<!-- ======================= -->
<root>
<!-- appender-ref ref="CONSOLE"/ -->
<appender-ref ref="FILE"/>
</root>
I knew little about log4j at start, but I knew what <!-- and --> does in xml. Just comment! So what the hell.... I asked Eng-ops to delete the old console.log file and to restart JBoss AS. The console.log was recreated and contained just a few lines of code. I also tried to raise some errors from applicaton, that might appear in this log (big thanks to Google for changing the API for getting Google analytics for giving me the error I needed). The error did not appear in the console.log, but in the log, that belonged to the specific web application responsible for rendering the web page instead. Nice! I asked again and was told, that the problem is actually server.log, not console.log. Aehmmm.....
The real fun - server.log too long
The configuration of the logger appeared to be valid:
<!-- A time/date based rolling appender -->
<appender name="FILE" class="org.jboss.logging.appender.DailyRollingFileAppender">
<errorHandler class="org.jboss.logging.util.OnlyOnceErrorHandler"/>
<param name="File" value="${jboss.server.log.dir}/server.log"/>
<param name="Append" value="true"/>
<param name="Threshold" value="INFO"/>
<!-- Rollover at midnight each day -->
<param name="DatePattern" value="'.'yyyy-MM-dd"/>
<layout class="org.apache.log4j.PatternLayout">
<!-- The default pattern: Date Priority [Category] Message\n -->
<param name="ConversionPattern" value="%d %-5p [%c] %m%n"/>
</layout>
</appender>
I copy pasted it on my local machine and it worked very well. When a new day came, the server.log was renamed to server.log.<date> and the logging to server.log started from the current day. Exactly as it should have been. But alas! You could see something like that on the staging:
......
2012-08-30 17:32:51,130 INFO [info.magnolia.cms.beans.config.PropertiesInitializer] Loading configuration at .................
2012-08-31 11:19:35,610 INFO [com.arjuna.ats.jbossatx.jta.TransactionManagerService] JBossTS Transaction Service (JTA version) - JBoss Inc.
......
So no roll over at all. What could possibly be wrong? Why on one machine it does work and on the other does not? A different version of log4j? Perhaps. A different locale and thus date-time format? Also possible. Thanks God log4j is the open source and thus the source code is available for everyone. I.e. here. If you check the code, you can find, that the content of the log is irrelevant. The only thing that matters is the modification date and time of the log file. It still does not answer why the roll over does not happen.
Unless you check the way, how the JBoss is started. We use a script for it, that has something like that inside:
for logfile in boot.log cluster.log console.log server.log; do
if [ -f /var/log/$NAME/$JBOSSCONF/$logfile ]; then
if [ "$JBOSSUS" != "RUNASIS" ]; then
$SU $JBOSSUS -s /bin/sh -c "touch /var/log/$NAME/$JBOSSCONF/$logfile >/dev/null 2>&1"
if [ ! $? -eq 0 ]; then
failure $"${NAME} startup"
echo -n -e "\nLogfile /var/log/$NAME/$JBOSSCONF/$logfile exists but not writable by $JBOSSUS."
echo -n -e "\n"
return 4
fi
else
if [ ! -w /var/log/$NAME/$JBOSSCONF/$logfile ]; then
failure $"${NAME} startup"
echo -n -e "\nLogfile /var/log/$NAME/$JBOSSCONF/$logfile exists but not writable."
echo -n -e "\n"
return 4
fi
fi
fi
done
And this is it. Touch changes the time, whe the server starts. And because there are logs to be written just when the application server starts, the date of the log file is always the current date and the roll over never happen.