jBoss 4.3 NAKACK sent_items explodes
Hi folks
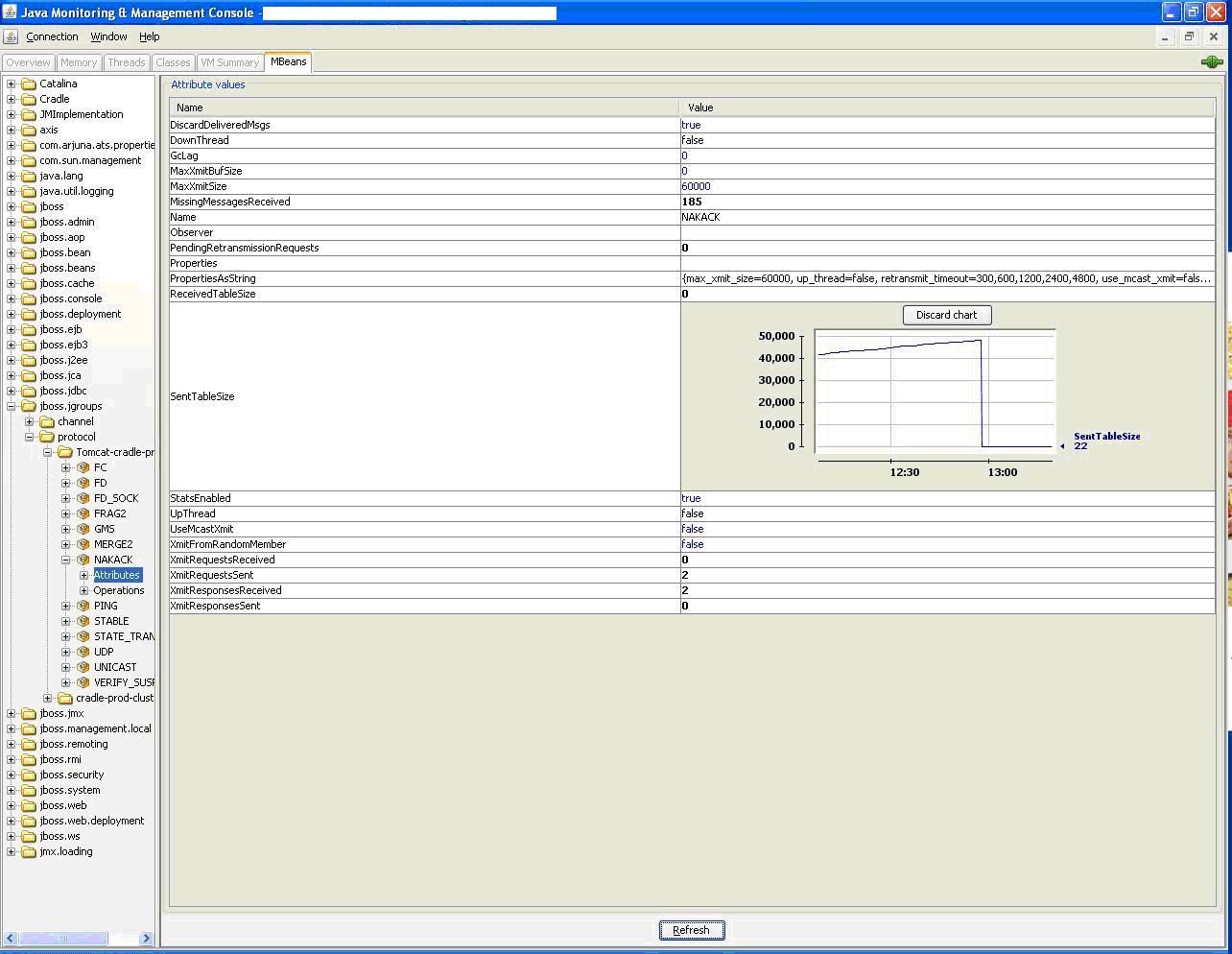
I'm facing a problem with our jBoss 4.3 cluster. 3 or 4 nodes. Occasionally, with no obvious trigger, the sent_items TreeMap in NAKACK grows uncontrollably in all nodes, and eventually a node will die with OutOfMemoryErrors. Normally watching it in jConsole sent_items bumps along at 5-20 items. Attached is a screenshot of it hitting 40,000. In this case we shot one of the nodes, and all other nodes immediately reclaimed everything in sent_items and things returned to normal.
It looks like the jGroups version is 2.4.5GA.
We don't think it's hardware related, it happens on multiple nodes, and restarting jBoss stops the problems - we might not see it again for a couple of weeks (with jBoss being bounced twice weekly).
Any ideas? A configuration problem?
Thanks
Guy
Here's (what I hope is) the basic clustering config
<mbean code="org.jboss.ha.framework.server.ClusterPartition"
name="jboss:service=${jboss.cluster.partitionname}">
<!-- Name of the partition being built -->
<attribute name="PartitionName">${jboss.cluster.partitionname}</attribute>
<!-- The address used to determine the node name -->
<attribute name="NodeAddress">${jboss.bind.address}</attribute>
<!-- Determine if deadlock detection is enabled -->
<attribute name="DeadlockDetection">False</attribute>
<!-- Max time (in ms) to wait for state transfer to complete. Increase for large states -->
<attribute name="StateTransferTimeout">30000</attribute>
<!-- The JGroups protocol configuration -->
<attribute name="PartitionConfig">
<!--
The default UDP stack:
- If you have a multihomed machine, set the UDP protocol's bind_addr attribute to the
appropriate NIC IP address, e.g bind_addr="192.168.0.2".
- On Windows machines, because of the media sense feature being broken with multicast
(even after disabling media sense) set the UDP protocol's loopback attribute to true
-->
<Config>
<UDP mcast_addr="${jboss.cluster.multicastaddress}"
mcast_port="${jboss.cluster.multicastport}"
tos="8"
ucast_recv_buf_size="20000000"
ucast_send_buf_size="640000"
mcast_recv_buf_size="25000000"
mcast_send_buf_size="640000"
loopback="false"
discard_incompatible_packets="true"
enable_bundling="false"
max_bundle_size="64000"
max_bundle_timeout="30"
use_incoming_packet_handler="true"
use_outgoing_packet_handler="false"
ip_ttl="${jgroups.udp.ip_ttl:10}"
down_thread="false" up_thread="false"/>
<PING timeout="2000"
down_thread="false" up_thread="false" num_initial_members="3"/>
<MERGE2 max_interval="100000"
down_thread="false" up_thread="false" min_interval="20000"/>
<FD_SOCK down_thread="false" up_thread="false"/>
<FD timeout="10000" max_tries="5" down_thread="false" up_thread="false" shun="true"/>
<VERIFY_SUSPECT timeout="1500" down_thread="false" up_thread="false"/>
<pbcast.NAKACK max_xmit_size="60000"
use_mcast_xmit="false" gc_lag="0"
retransmit_timeout="300,600,1200,2400,4800"
down_thread="false" up_thread="false"
discard_delivered_msgs="true"/>
<UNICAST timeout="300,600,1200,2400,3600"
down_thread="false" up_thread="false"/>
<pbcast.STABLE stability_delay="1000" desired_avg_gossip="50000"
down_thread="false" up_thread="false"
max_bytes="400000"/>
<pbcast.GMS print_local_addr="true" join_timeout="3000"
down_thread="false" up_thread="false"
join_retry_timeout="2000" shun="true"
view_bundling="true"/>
<FRAG2 frag_size="60000" down_thread="false" up_thread="false"/>
<pbcast.STATE_TRANSFER down_thread="false" up_thread="false" use_flush="false"/>
</Config>
</attribute>
<depends>jboss:service=Naming</depends>
</mbean>