This content has been marked as final.
Show 9 replies
-
1. Clustering in JBoss AS 6
meetoblivion Jan 18, 2011 2:14 PM (in response to meetoblivion)
Here's a similar example
In my case, i'm using ports-02.
2011-01-18 14:05:24,336 WARN [org.jgroups.protocols.pbcast.NAKACK] (Incoming-1,null) 172.17.12.21:1299: dropped message from 172.17.12.20:1299 (not in table [172.17.12.21:1299]), view=[172.17.12.21:1299|0] [172.17.12.21:1299]
2011-01-18 14:05:24,337 WARN [org.jgroups.protocols.pbcast.NAKACK] (OOB-19,null) 172.17.12.21:1299: dropped message from 172.17.12.20:1299 (not in table [172.17.12.21:1299]), view=[172.17.12.21:1299|0] [172.17.12.21:1299]
So even when it identifies its partner on the other machine, it gets rejected.
-
2. Clustering in JBoss AS 6
pferraro Jan 18, 2011 2:33 PM (in response to meetoblivion)
Individual members of the cluster must have unique bind addresses, that is, a combination of the network address and port. The easiest way to achieve this is to start each instance using a different port set.
http://community.jboss.org/wiki/ConfiguringMultipleJBossInstancesOnOneMachine
e.g.
$JBOSS_HOME/bin/run.sh -Djboss.service.binding.set=ports-default
$JBOSS_HOME/bin/run.sh -Djboss.service.binding.set=ports-01
$JBOSS_HOME/bin/run.sh -Djboss.service.binding.set=ports-02
$JBOSS_HOME/bin/run.sh -Djboss.service.binding.set=ports-03
This should allow the cluster members on a single machine to be able to see each other, while still being uniquely identifiable.
If you want all 8 instances to participate in the same "cluster", then you'll want them all to use the same "partition" (i.e. the -g argument).
Are you having problem clustering across machines as well? If you run just one instance on each machine, do they cluster properly?
-
3. Re: Clustering in JBoss AS 6
meetoblivion Jan 18, 2011 2:37 PM (in response to pferraro)
In my case, i am starting each with its own port base. i'm using all configuration as well. In all cases, I'm using -g lclapp when starting. It appears that across machines, they talk to one another, but they are colliding on:
2011-01-18 14:05:25,574 WARN [org.hornetq.core.cluster.impl.DiscoveryGroupImpl] (hornetq-discovery-group-thread-dg-group1) There are more than one servers on the network broadcasting the same node id. You will see this message exactly once (per node) if a node is restarted, in which case it can be safely ignored. But if it is logged continuously it means you really do have more than one node on the same network active concurrently with the same node id. This could occur if you have a backup node active at the same time as its live node.
which means i need to set a node id somewhere, right? this only happens when I bring up the second set of instances.
-
4. Re: Clustering in JBoss AS 6
pferraro Jan 18, 2011 2:58 PM (in response to meetoblivion)
This is a product of your 4 instances per machine running off the same profile and sharing the same data directory. So a couple options:
- Delete the contents of $JBOSS_HOME/server/all
- Create 3 copies of $JBOSS_HOME/server/all (e.g. all-1, all-2, all-3)
- Start your instances using the separate profiles, that way each gets its own data directory.
or
- Create 3 new data directories within $JBOSS_HOME/server/all (e.g. data-01, data-02, data-03)
- Start your instances using unique data directories (e.g. run.sh -Djboss.service.binding.set=ports-01 -Djboss.server.data.dir=$JBOSS_HOME/deploy/all/data-01)
- Consider doing something similar for temp and log directories.
-
5. Re: Clustering in JBoss AS 6
meetoblivion Jan 18, 2011 3:02 PM (in response to pferraro)
Paul, in my case, each instance has its own install base. JBOSS_HOME is different for each instance.
-
6. Re: Clustering in JBoss AS 6
pferraro Jan 18, 2011 4:04 PM (in response to meetoblivion)
I'm no expert on hornetq, but I was under the impression that it used a UUID for the server ID, so server identity uniqueness shouldn't be issue. Can you create a thread on the hornetq forums about this? Are you still seeing NAKACK-related WARN logs from jgroups?
-
7. Clustering in JBoss AS 6
meetoblivion Jan 20, 2011 8:12 AM (in response to pferraro)
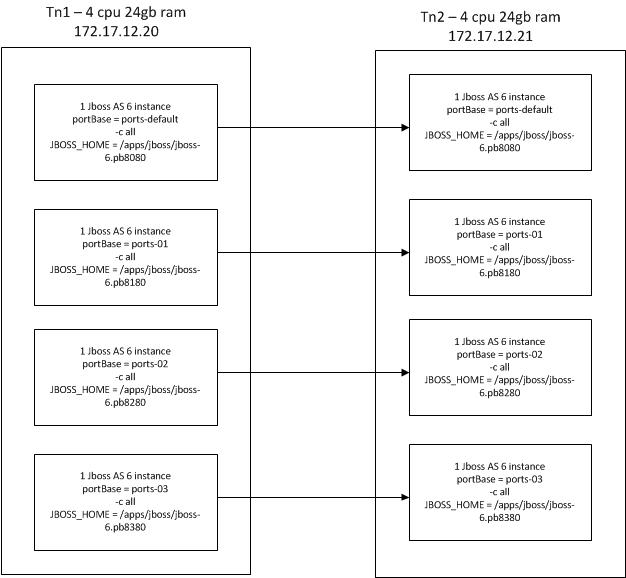
I added an attachment to my original post. So ignoring the NAKACK from HornetQ for a moment, what I'm seeing is a bit more concerning. I believe I previously saw an issue where ReplicationTimeout was occurring across nodes. In the attachment, I document what my environment looks like right now. I see the ReplicationTimeout occur, but I need to follow up on https://issues.jboss.org/browse/ISPN-835 to get that working.
The main issue I'm seeing is that vertical replication is not occuring. On tn1, I expect replication to occur between the various port bases. Maybe I'm just not following your description, but I can't seem to make that happen (though I suspect when I do, I'll run in to ISPN-835 again).
-
8. Clustering in JBoss AS 6
harish.beniwal123 May 9, 2011 4:32 AM (in response to meetoblivion)
hello i am new in jboss6. and i want to implement jboss clustering in my porject. so please help me and give me some documatation of clustering, so i can implement on my project.
please give me step wise documentation if possible
-
9. Clustering in JBoss AS 6
wdfink May 9, 2011 6:12 AM (in response to harish.beniwal123)
Hi Harish,
you should use a new thread for this, because you ask something different.
In general you have nothing to do to implement a cluster, but ...
You have to think about what you try to, loadbalance web or EJB application, what about failure ...
A stateless EJB is simple add @Clusterd to your @Stateless and JBoss (use all configuration) will do the rest
If you have more questions feel free to ask, but I recommend to use a new thread and please provide a bit about your application requirements.