-
15. Re: Out of memory on 2.2.11
craigm123 Jun 21, 2012 3:19 PM (in response to ataylor)
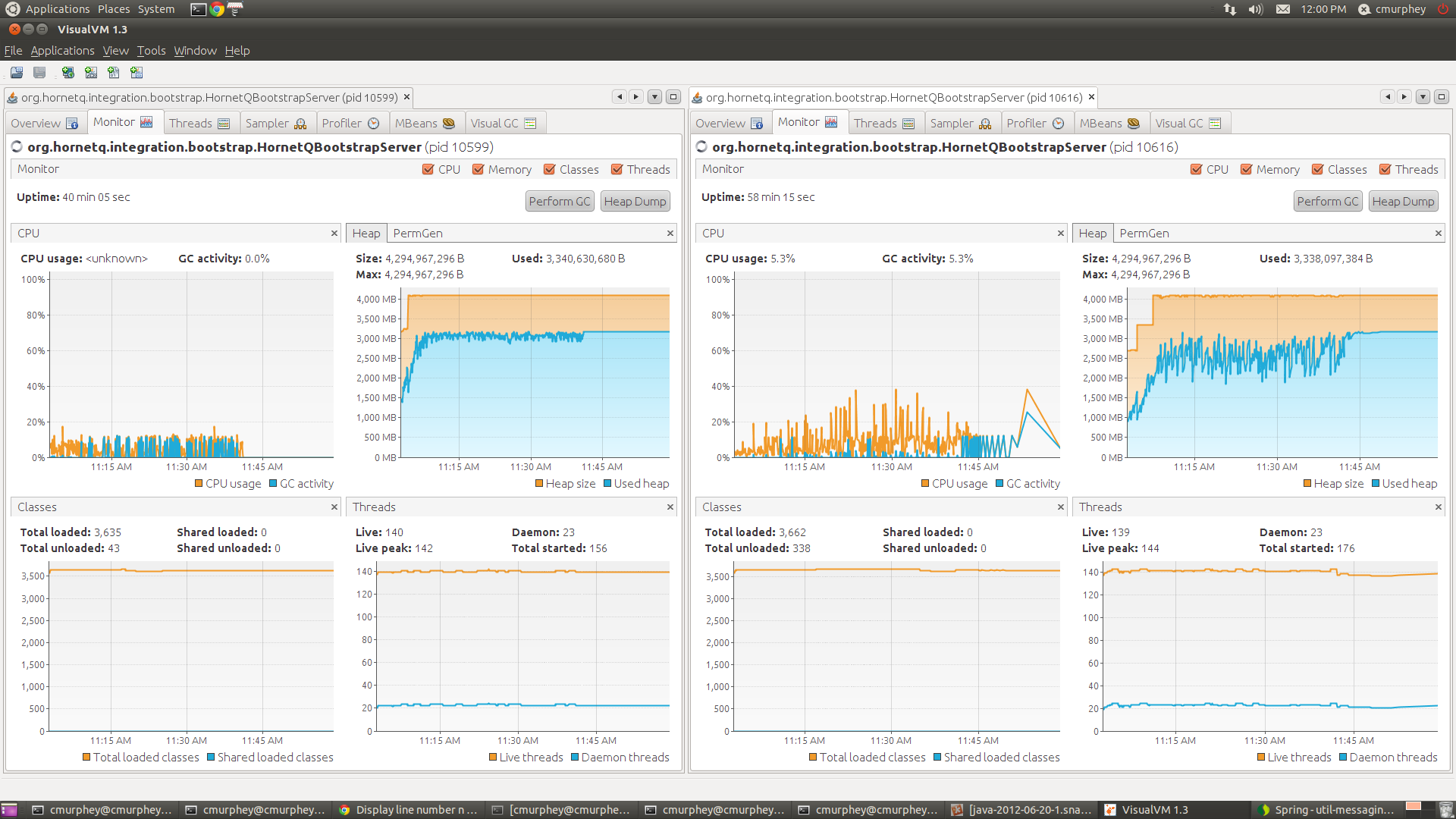
Hmm, perhaps I was only able to reproduce the OOM by killing one of the brokers during the same test. I made an assumption that the broker would eventually OOM because it had the same memory behavior (ie. filling up the old gen and constantly gc'ing the eden). I've attached a screen shot of visual vm with both nodes in it. The one on the left I killed after it was running for 40 mintues. The second node eventually OOM'ed after another 20 minutes.
My thought is that the second broker should never OOM, regardless of what happens to the first one.
I did look into the errors you mentiond. There are definitely no other nodes but these two, so I'm not sure how exactly there could be duplicate nodeID creation. Is it possible the bindings weren't cleared up after a node disconnected, then re-connected right away with the same node-id? Later on when we see the "Cannot find binding" message, it looks like the bindings were removed but not created, which looks to be a consequence of the first log message indicating the new binding is being ignored.
I'm not sure why dead connections would force an OOM. Do the objects in the jmap -histo dump relate to the dead connections? If the OOM is caused by dead connections, then I should easily be able to reproduce the same situation on a standalone node, right? I have tried just that and have not seen a huge jump in memory consumption.
-
OOMAfterKillingABroker.png 165.0 KB
-
-
16. Re: Out of memory on 2.2.11
craigm123 Jun 21, 2012 8:19 PM (in response to craigm123)
Here's the log from the node after the OOM.
I don't see any messages in the log about duplicate node IDs or other bindings already existing, so the OOM doesn't look to be related to the exception.
-
messagebroker.log.zip 5.2 KB
-
-
17. Re: Out of memory on 2.2.11
ataylor Jun 22, 2012 11:00 AM (in response to craigm123)
I have run the scenario you specified and did not get the OOM, however i used visualvm and did notice that the memory levels did start to rise and also GC happened on a smaller and smaller frequency, however on my machine it would probably take a long time before I had an issue. It happens on your machine probably because of your env, however saying that this is probably an issue we need to look at.
What we think is happening is this, when a node goes down the clustered bridge will keep trying to reconnect, at this point it depages messages, if it fails then these are repaged, so you get into an cycle where depending on processor speed and disc speed the garbage collector can't keep up, look at the following piece of code:
while(true)
{
String s = "a big string";
s = null;
}
If the objects are created faster than the GC can collect them you may have issues.
We will keep investigating but for now a few points:
There are 2 things you can do, firstly bring the other node backup or configure a backup server, this will stop the bridge trying to reconnect. Alternatively, set reconnectAttempts on the cluster connection to something other than -1, this will also stop the bridge from trying to reconnect by closing it )detaching it from the cluster).
One last thing, although its great that you gave us an easy reproducable (we wish all people would do this) I see it uses spring. From experience this usually muddies the water, for instance i'm assuming from the senderContect xml that there are 100 connection shared between the 2 nodes? What Is uncertain is how Spring handles things when 50 of these are disconnected, are they recreated to the other node, closed etc etc, any chance if you still have issues you could give us a pure JMS client?
-
18. Re: Out of memory on 2.2.11
craigm123 Jun 22, 2012 5:44 PM (in response to ataylor)
Thanks again for the response.
I tried out two things - first I created a pure JMS client as you suggested, then re-ran the same test. Again saw the OOM after letting both hornetq nodes run for some time, then killing the node not receiving traffic. Like Spring's CachingConnectionFactory, my pure JMS client creates only one connection with many sessions and producers off that connection. The attachment I've attached this time has both the Spring producer client, as well as the pure JMS producer client. It currently only has the pure JMS producer client wired in.
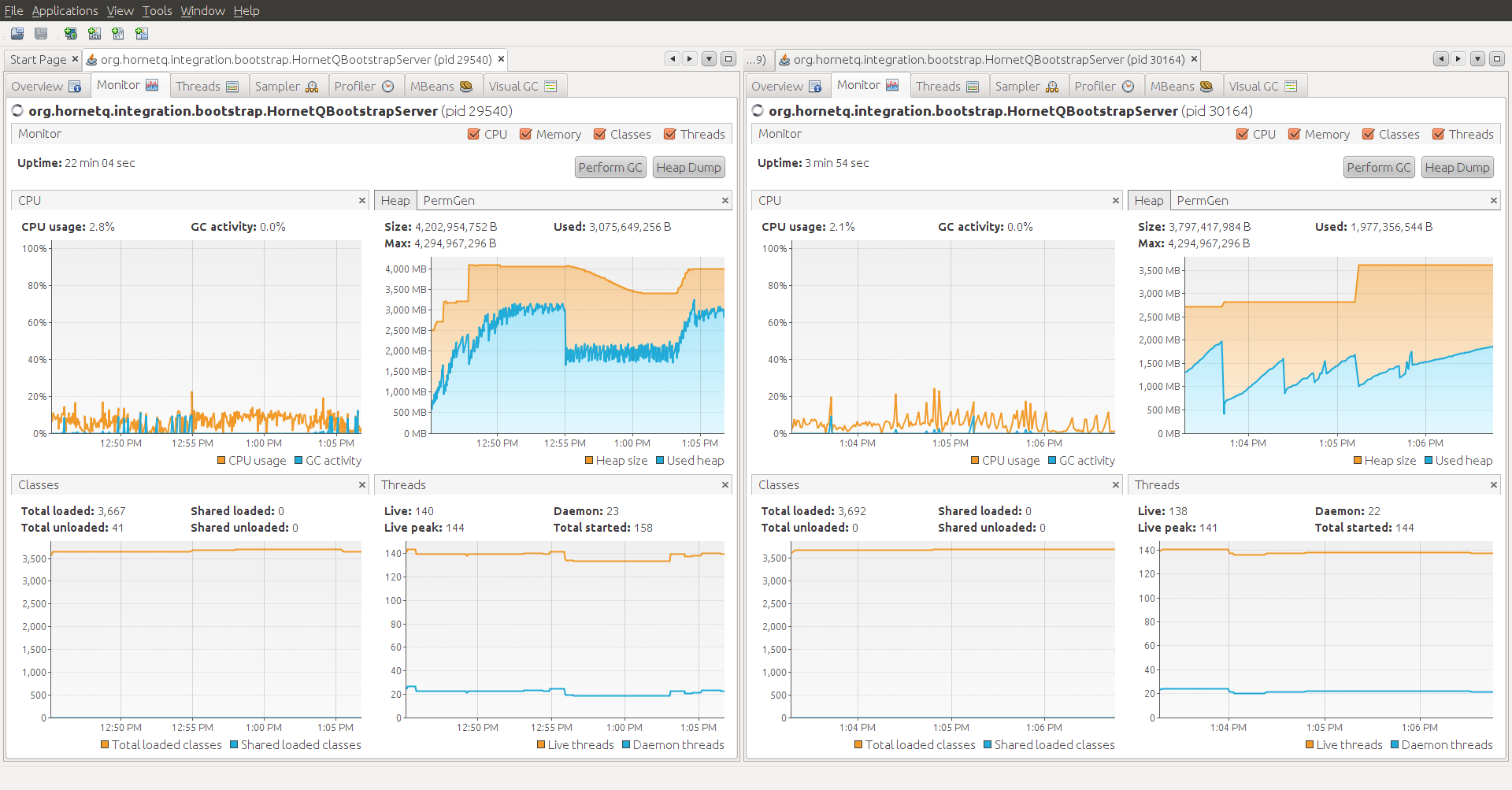
The second thing I tried was to add in the reconnect-attempts to the hornetq-configuration. After the same experiment, I did not see an OOM! Cool! Memory still grew to the point where old gen was completely full and GC was happening frequently while the two were still connected, but after I killed it, I see a large drop in heap usage. Attaching the visualvm screen shot of the act (WithReconnectAttempts.png).
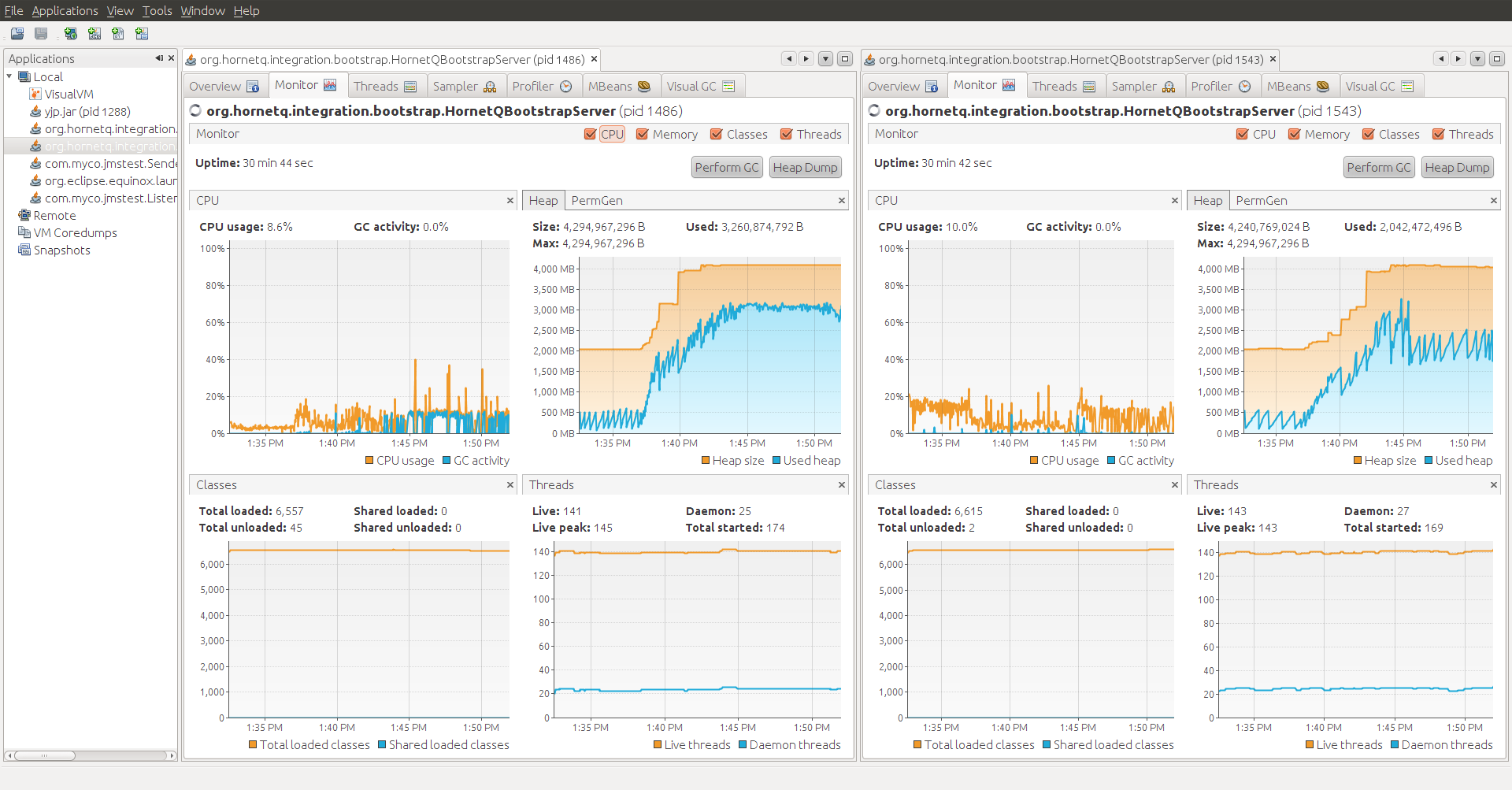
I then restarted the broker I had killed and it re-connected just fine. Memory, again, increased and filled up old gen (see visualvm screenshot AfterRestartingSecondBroker.png). Everything continues to function fine after this point.
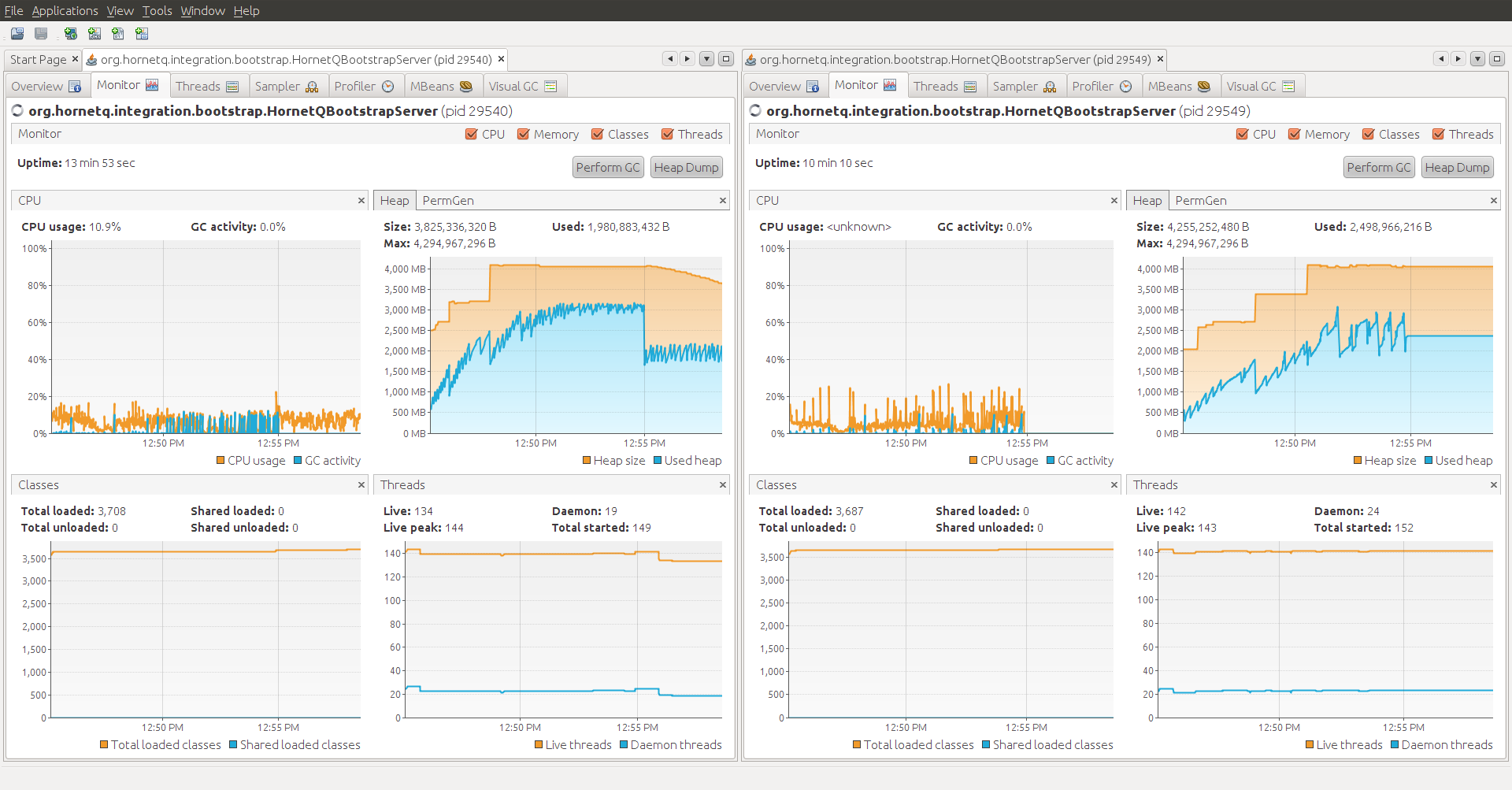
I ran one other test that I'd like to mention - I started both broker nodes and sender client that is only attached to the first node, let the nodes page, then attached a listener on the second node. In other words, I'm purposely forcing all traffic to get re-distributed from the first node to the second node where I have the listener. Nothing seems to break, but when de-paging is going on the sender's ability to send into the queue goes down drastically. During this time, there's a huge amount of GC going on on the first broker (see the visualvm screenshot SenderAndListener.png). I've attached the sender's log to show how the rate goes down drastically during de-paging (starting at about 700000 ms in). After de-paging finishs up, the rate allowed in seems to speed up to normal levels. The amount of GC'ing going on is very concerning. Is there any way to tune how much memory is held onto when sending messages across the core bridge?
Regarding my environment - I'm running the hornetq nodes (journals and pages) on a SSD and my box has 8 processors. I would imagine if the journals are on a HDD, you may not see the same thing.
-
sendinglog.txt.zip 2.6 KB
-
hornetq-test.tgz 11.6 MB
-
AfterRestartingSecondBroker.png 136.9 KB
-
SenderAndListener.png 152.5 KB
-
WithReconnectAttempts.png 130.5 KB
-
-
19. Re: Out of memory on 2.2.11
smswamy Aug 24, 2012 6:40 AM (in response to ataylor)
Hi, I am also seeing the same Illegal State Exception messages in my log. I have already posted this in disucssion https://community.jboss.org/message/755529. We are using hornetq(JMS) using JBOSS AS 7.1.1. We are not using MDB. When we try to start our jboss servers in multiple physical systems, we get this. The last system that starts gets this message. I even tried this in the configuration, still facing the same issue,...we dont need to deploy any application, jsut starting the server itself I am getting this.
<connection-factory name="InVmConnectionFactory">
<connectors>
<connector-ref connector-name="in-vm"/>
</connectors>
<entries>
<entry name="java:/ConnectionFactory"/>
</entries>
<connection-ttl>-1</connection-ttl>
<retry-interval>1000</retry-interval>
<retry-interval-multiplier>1.5</retry-interval-multiplier>
<max-retry-interval>60</max-retry-interval>
<reconnect-attempts>100</reconnect-attempts>
</connection-factory>
<connection-factory name="RemoteConnectionFactory">
<connectors>
<connector-ref connector-name="netty"/>
</connectors>
<entries>
<entry name="RemoteConnectionFactory"/>
<entry name="java:jboss/exported/jms/RemoteConnectionFactory"/>
</entries>
<connection-ttl>-1</connection-ttl>
<retry-interval>1000</retry-interval>
<retry-interval-multiplier>1.5</retry-interval-multiplier>
<max-retry-interval>60000</max-retry-interval>
<reconnect-attempts>1000</reconnect-attempts>
</connection-factory>
Can you please help me on this. It says the Remote queue is already bound. For all the queue and topic we are using it is saying the same message,
[server=HornetQServerImpl::serverUUID=a2faeb49-edcc-11e1-a95d-45205e0dc74b]]@16a4847b, isClosed=false, firstReset=true]::Remote queue binding jms.queue.expiryQueuea2faeb49-edcc-11e1-a95d-45205e0dc74b has already been bound in the post office. Most likely cause for this is you have a loop in your cluster due to cluster max-hops being too large or you have multiple cluster connections to the same nodes using overlapping addresses
Aftet this whatever ERROR message you have put up here is coming up.
org.hornetq.core.server.cluster.impl.ClusterConnectionImpl - Failed to handle message
java.lang.IllegalStateException: Cannot find binding for jms.queue
Will you please help me fixing this. If it is something environment, what it can be ?