Hi Clebert,
Thanks for your reply. I tested the structure again and found out the clustering did distrute the message now. I might by accident use the wrong way to send message with our software yesterday.
But at this moment, I have met another problem. After I killed the Live server, the backup server successfully annouced itself to be alive, as shown below:
[Thread-1] 14:00:24,720 INFO [org.hornetq.core.server.impl.HornetQServerImpl] Backup Server is now live
[Thread-6 (group:HornetQ-server-threads1762702912-750922299)] 14:00:24,891 INFO [org.hornetq.core.server.cluster.impl.BridgeImpl] Connecting bridge sf.my-cluster.fa8a6b0a-095d-11e2-a8d2-000c2986119a to its destination [f88154cf-095d-11e2-92c9-000c299c9d74]
[Thread-6 (group:HornetQ-server-threads1762702912-750922299)] 14:00:24,957 INFO [org.hornetq.core.server.cluster.impl.BridgeImpl] Bridge sf.my-cluster.fa8a6b0a-095d-11e2-a8d2-000c2986119a is connected [f88154cf-095d-11e2-92c9-000c299c9d74-> sf.my-cluster.fa8a6b0a-095d-11e2-a8d2-000c2986119a]
But the message stored in the journal is not treated at all by the backup machine.
In the logs of another Live machine, I have seen the following sentences. It seems, the other Live machine did recognized the failedOver, but due to some reason, the channel is disconnected. Do you know why it happened? Thanks!
2012-09-28 14:00:23,862 WARN [org.hornetq.core.server.cluster.impl.BridgeImpl] (Thread-0 (group:HornetQ-client-global-threads-561276172)) sf.my-cluster.f88154cf-095d-11e2-92c9-000c299c9d74::Connection failed before reconnect : HornetQException[errorCode=2 message=Channel disconnected]
at org.hornetq.core.client.impl.ClientSessionFactoryImpl.connectionDestroyed(ClientSessionFactoryImpl.java:363)
at org.hornetq.core.remoting.impl.netty.NettyConnector$Listener$1.run(NettyConnector.java:687)
at org.hornetq.utils.OrderedExecutorFactory$OrderedExecutor$1.run(OrderedExecutorFactory.java:100)
at java.util.concurrent.ThreadPoolExecutor$Worker.runTask(ThreadPoolExecutor.java:886)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:908)
at java.lang.Thread.run(Thread.java:619)
2012-09-28 14:00:24,934 WARN [org.hornetq.core.server.cluster.impl.BridgeImpl] (Thread-0 (group:HornetQ-client-global-threads-561276172)) sf.my-cluster.f88154cf-095d-11e2-92c9-000c299c9d74::Connection failed with failedOver=true: HornetQException[errorCode=2 message=Channel disconnected]
at org.hornetq.core.client.impl.ClientSessionFactoryImpl.connectionDestroyed(ClientSessionFactoryImpl.java:363)
at org.hornetq.core.remoting.impl.netty.NettyConnector$Listener$1.run(NettyConnector.java:687)
at org.hornetq.utils.OrderedExecutorFactory$OrderedExecutor$1.run(OrderedExecutorFactory.java:100)
at java.util.concurrent.ThreadPoolExecutor$Worker.runTask(ThreadPoolExecutor.java:886)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:908)
at java.lang.Thread.run(Thread.java:619)
2012-09-28 14:00:24,948 WARN [org.hornetq.core.protocol.core.impl.ChannelImpl] (Old I/O client worker (channelId: 635122141, /127.0.0.1:54161 => localhost/127.0.0.1:5446)) Can't find packet to clear: last received command id 3 first stored command id 3
2012-09-28 14:00:24,951 WARN [org.hornetq.core.protocol.core.impl.ChannelImpl] (Old I/O client worker (channelId: 635122141, /127.0.0.1:54161 => localhost/127.0.0.1:5446)) Can't find packet to clear: last received command id 4 first stored command id 4
2012-09-28 14:00:24,951 WARN [org.hornetq.core.protocol.core.impl.ChannelImpl] (Old I/O client worker (channelId: 635122141, /127.0.0.1:54161 => localhost/127.0.0.1:5446)) Can't find packet to clear: last received command id 5 first stored command id 5
2012-09-28 14:00:24,953 WARN [org.hornetq.core.protocol.core.impl.ChannelImpl] (Old I/O client worker (channelId: 635122141, /127.0.0.1:54161 => localhost/127.0.0.1:5446)) Can't find packet to clear: last received command id 6 first stored command id 6
2012-09-28 14:00:25,357 INFO [org.jboss.ha.framework.server.ClusterPartition.Partition1] (VERIFY_SUSPECT.TimerThread,Partition1-HAPartition,192.168.134.128:1099) Suspected member: 192.168.134.130:1099
2012-09-28 14:00:25,488 INFO [org.jboss.ha.framework.server.ClusterPartition.lifecycle.Partition1] (Incoming-4,null) New cluster view for partition Partition1 (id: 2, delta: -1, merge: false) : [192.168.134.128:1099]
2012-09-28 14:00:25,488 INFO [org.infinispan.remoting.transport.jgroups.JGroupsTransport] (Incoming-4,null) Received new cluster view: [192.168.134.128:1099|2] [192.168.134.128:1099]
2012-09-28 14:00:25,491 INFO [org.jboss.ha.core.framework.server.DistributedReplicantManagerImpl.Partition1] (AsynchViewChangeHandler Thread) I am (192.168.134.128:1099) received membershipChanged event:
2012-09-28 14:00:25,492 INFO [org.jboss.ha.core.framework.server.DistributedReplicantManagerImpl.Partition1] (AsynchViewChangeHandler Thread) Dead members: 1 ([192.168.134.130:1099])
2012-09-28 14:00:25,492 INFO [org.jboss.ha.core.framework.server.DistributedReplicantManagerImpl.Partition1] (AsynchViewChangeHandler Thread) New Members : 0 ([])
2012-09-28 14:00:25,492 INFO [org.jboss.ha.core.framework.server.DistributedReplicantManagerImpl.Partition1] (AsynchViewChangeHandler Thread) All Members : 1 ([192.168.134.128:1099])
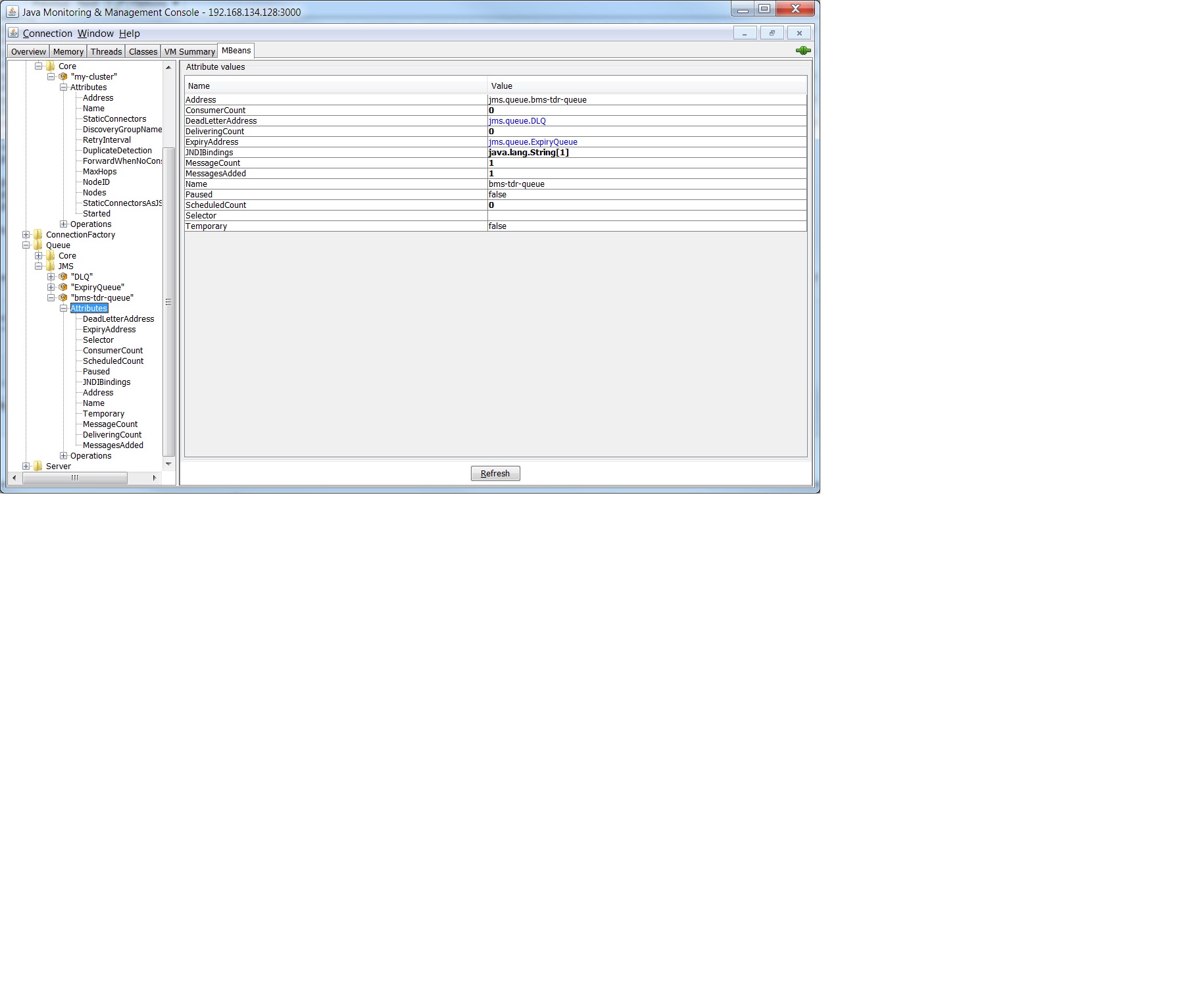
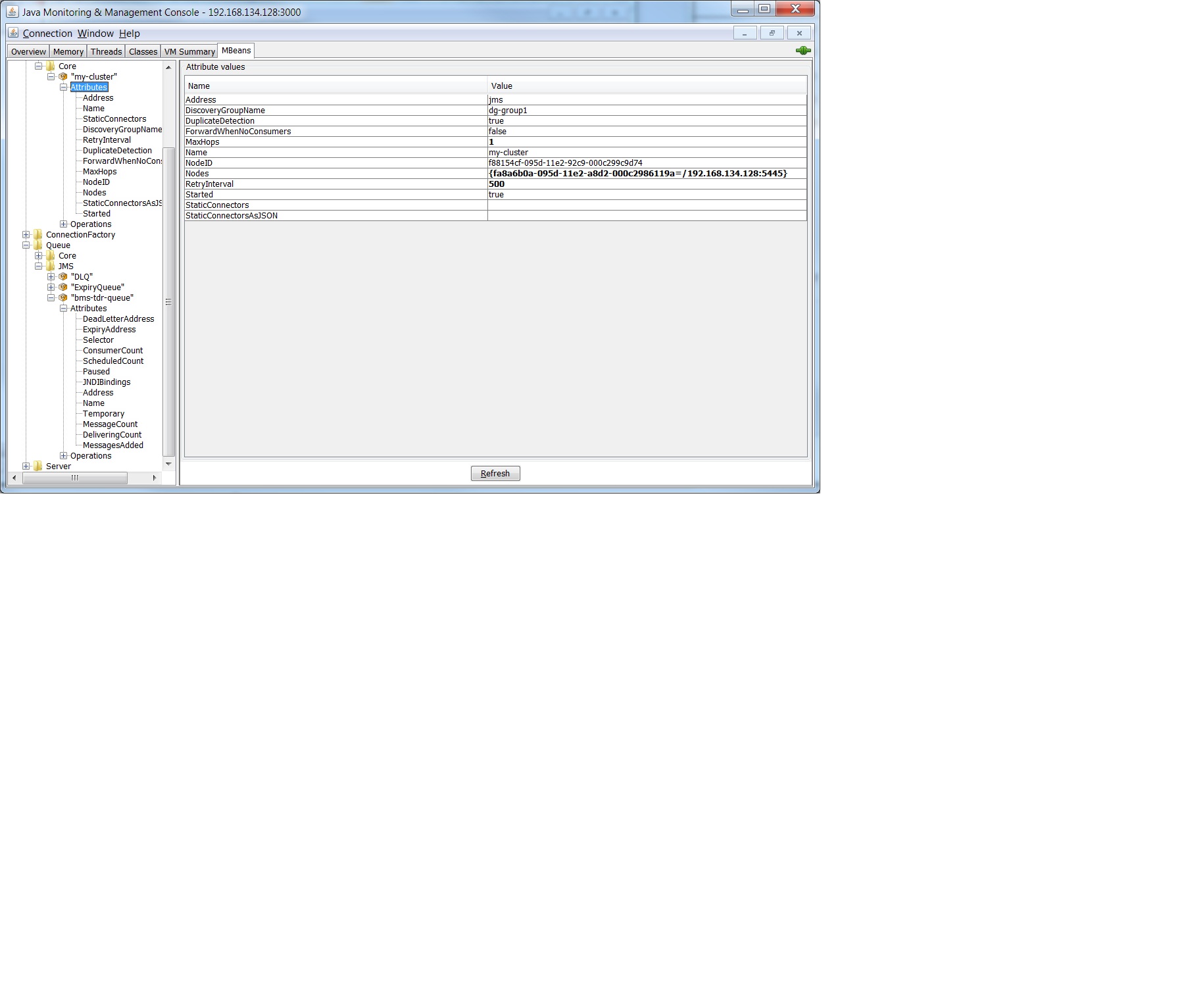
I have checked the Standalone Hornetq with Jconsole and it seems the Backup machine had formed the cluster with the other Live machine. The Queue were also created successfully at the backup server, but there's no consumer to consume the info.
PS: The reason I didn't use the latest version is because our software used the version 2.2.5 Final already in the past, when first using the Hornetq. I recently worked on it again, just to adding the backup servers, so I used the same version as before.