This content has been marked as final.
Show 7 replies
-
1. Re: jBPM 6 and Quartz timer : Cron/Cycle Timer jobs fails in Cluster
swiderski.maciej Sep 9, 2013 11:21 AM (in response to anindyas79)
for a quartz based timer service there is a additional check to avoid these sort of issues so it should not happen as quartz should return already registered JobDetail object. What could happen is sort of race condition that both checks that there are no jobs scheduled yet and tries to schedule it. Since that is done at pretty much same time it could fail. Could you please start servers in sequence so you know that first is already up and running and then start the second server to see if that is the cause?
Cheers
-
2. Re: jBPM 6 and Quartz timer : Cron/Cycle Timer jobs fails in Cluster
anindyas79 Sep 11, 2013 2:53 PM (in response to swiderski.maciej)
Yes Maciej, that's indeed the case. When I start the two servers simultaneously then a race condition develops and which leads to that error. However, when I start them sequentially with a certain gap between them then it works fine. But when we deploy in a domain (cluster) we usually deploy it from the management console and that time we can't really control the deployment sequence, so a race condition can likely occur.
What I was thinking can we deploy the scheduler as a shared service e.g. register it as an mbean when the application server starts up or deploy it as a HAClusterSingleton bean cross the cluster and then we delegate the call to the scheduler to this mbean or the HASingletonCluster Scheduler service from our application. In that case we can have one Quartz scheduler across the domain(cluster) and there will be no race condition. Also the shared Quartz scheduler needs to have access to the RuntimeManager in that case.
Your thoughts on this please.
-
3. Re: jBPM 6 and Quartz timer : Cron/Cycle Timer jobs fails in Cluster
swiderski.maciej Sep 12, 2013 1:17 AM (in response to anindyas79)
alright, good that this was confirmed as well. I made some changes to prevent of failing in case it has already been found in db store. Could you give a try with latest master to see if that resolves the issue?
About having quartz as a shared service that might be bit tricker then it looks at first. Especially that there can be multiple RuntimeManagers running and they are dynamic by nature - can be deployed and undeployed at any time. Using HAClusterSingleton (which I am not sure still exists in AS7 - haven't checked) will be JBoss AS specific and we try to avoid anything that constraints us to a given application server as jBPM in general has no dependencies to application server at all.
I have been testing that in JBoss EAP domain as well and could not reproduce that behavior at all, it always get's properly recognized on schedule method level so in case a already existing job is available it does not go into internalSchedule method. What's your environment configuration? Do you have multiple physical machines involved? Is db on same host as application servers?
HTH
-
4. Re: Re: jBPM 6 and Quartz timer : Cron/Cycle Timer jobs fails in Cluster
anindyas79 Sep 12, 2013 11:50 AM (in response to swiderski.maciej)
Hello Maciej
I am testing in my laptop. I have two jBoss EAP 6.1 instances of same configuration and the Oracle database is also running in the same machine. I have placed the same war application in the standalone/deployments folder of each JBoss instances. Now I started the two machines with port offset as follows as I don't have two physical machines.
standalone.bat -Dorg.quartz.properties=resources/quartz-db.properties -Djboss.socket.binding.port-offset=100
standalone.bat -Dorg.quartz.properties=resources/quartz-db.properties -Djboss.socket.binding.port-offset=200
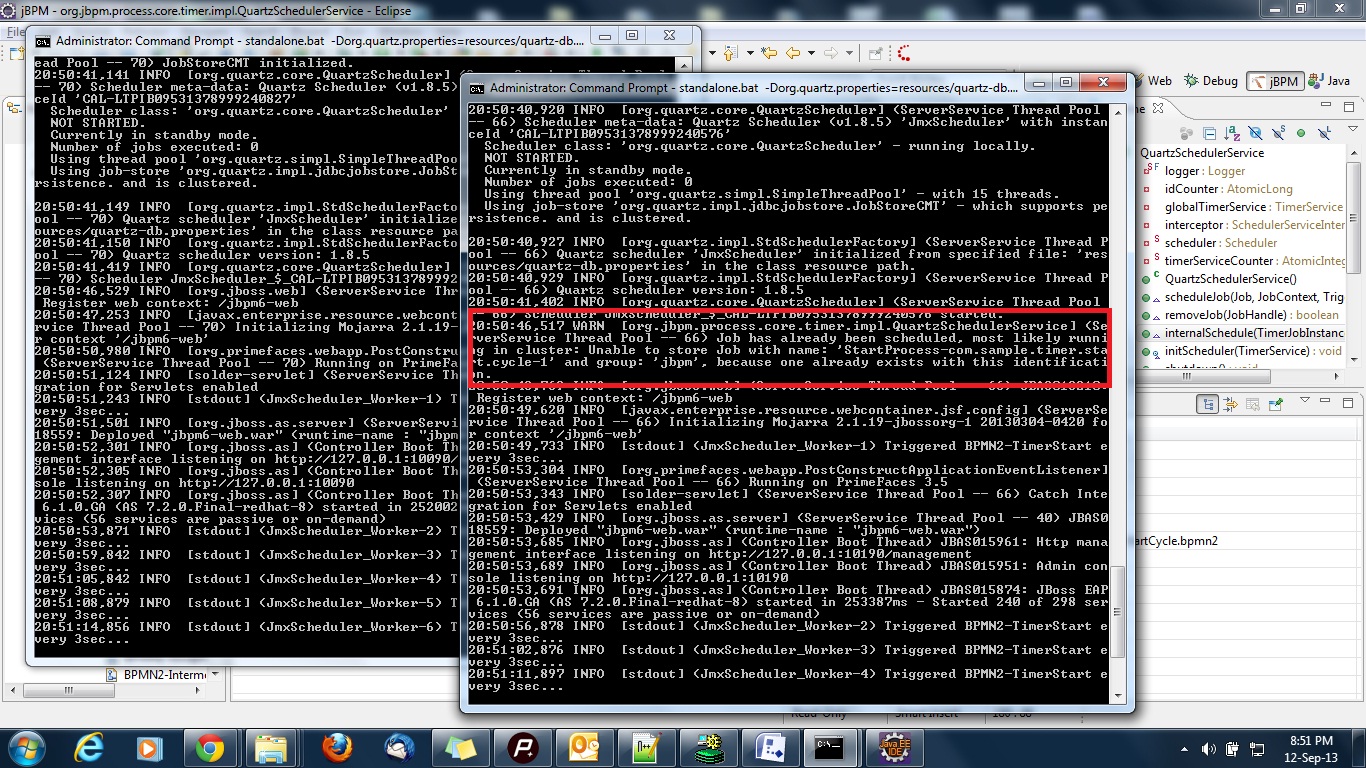
I have deliberately started them in this fashion and not in domain mode to check the race condition, and yes I was able to reproduce the problem, screenshot is attached. But, the good news is with your latest fix of checking the ObjectAlreadyExistsException from the master this race situation is now handled gracefully.
Since it works this way I am pretty sure it will work in domain mode too, I will test the domain mode though also and let you know.
Are these fixes going to be incorporated into jbpm 6 GA release?
-
race_quartz.jpg 604.3 KB
-
-
5. Re: jBPM 6 and Quartz timer : Cron/Cycle Timer jobs fails in Cluster
swiderski.maciej Sep 12, 2013 12:54 PM (in response to anindyas79)
nice, so the fix did what it's expected. I am testing in domain mode as well and that works all ok. but additional verification tests are more than welcome.
Yes, it will be included in 6.0. Big thanks for testing this and reporting back! Looking forward to more of these
Cheers
-
6. Re: jBPM 6 and Quartz timer : Cron/Cycle Timer jobs fails in Cluster
bpm77 Nov 19, 2013 3:42 PM (in response to anindyas79)
Hi Maciej,
I was trying to evaluate Quartz Timer Service in jbpm6.
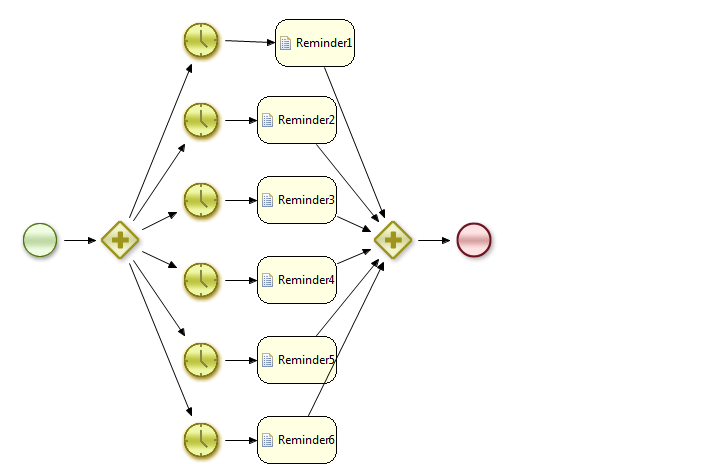
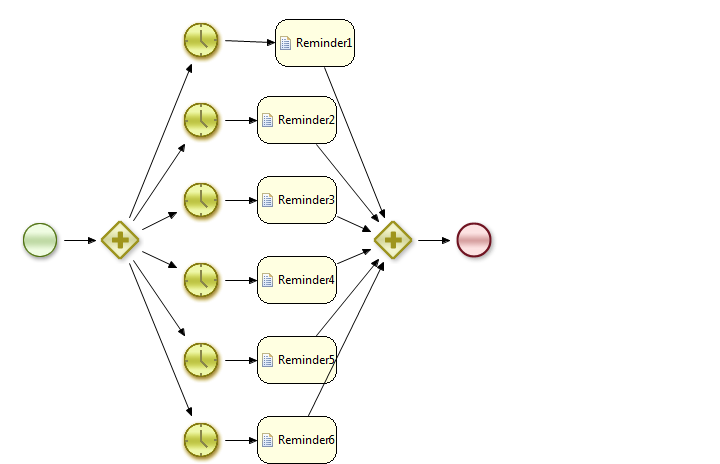
I tried to make reminder service process like below image and executed in H2 server mode DB in java embedded mode.(Using BTMTrx Manager).Timer Event has delay of 15s and Timer Period is 1m.
Each Timer delay increments by 5s.
When I created process instance and allowed to run for long time. behavior of process flow was perfect.
I stopped the process and executed after 1 minute. I can see exception happened and many triggers got deleted from Trigger table of Quartz
even I put long value of quartz property of org.quartz.jobStore.misfireThreshold = 60000000000.
For me this process never got success for all three RuntimeManagerFactory Policy.
I was getting error like below :
- jbpm.66-99-3 threw a JobExecutionException:
- org.quartz.JobExecutionException: Exception when executing scheduled job
at org.jbpm.process.core.timer.impl.QuartzSchedulerService$QuartzJob.execute(QuartzSchedulerService.java:274) ~[jbpm-flow-6.0.0.CR2.jar:6.0.0.CR2]
at org.quartz.core.JobRunShell.run(JobRunShell.java:216) ~[quartz-1.8.5.jar:na]
at org.quartz.simpl.SimpleThreadPool$WorkerThread.run(SimpleThreadPool.java:549) [quartz-1.8.5.jar:na]
Caused by: java.lang.NullPointerException: null
Same Process I tried to execute in Cluster environment ,Getting exception Caused by: org.hibernate.StaleObjectStateException: Row was updated or deleted by another transaction (or unsaved-value mapping was incorrect): [org.drools.persistence.info.SessionInfo#3857]
and All triggers were deleting.
Seems like even exception there is no rollback happening.
-
7. Re: jBPM 6 and Quartz timer : Cron/Cycle Timer jobs fails in Cluster
swiderski.maciej Nov 20, 2013 2:00 AM (in response to bpm77)
first of all, please start new threads for new questions, especially when the current one is already answered.
Looks like you use CR2 which have had number of issues in this area. Please try with newer version, like CR5 or wait for 6.0.0.Final is is about to be released.
HTH