This content has been marked as final.
Show 8 replies
-
1. Re: Server group and Server node relation - removal - expected behavior
emuckenhuber Apr 8, 2014 6:17 AM (in response to vandamo)
Hmm, in general you should not be able to remove a server-group if there are still servers assigned to it. If this is the case it's a bug.
Can you describe your deployment use cases you are looking for in more detail? We do have something called rollout plans, where you can deploy a deployment to multiple server-groups.
-
2. Re: Server group and Server node relation - removal - expected behavior
jason.marley Apr 8, 2014 12:10 PM (in response to vandamo)
You may consider doing rolling deployments leveraging HTTPD and modcluster to ensure fail over; assuming this is run in domain mode, you could have to at least have each domain replicated. I don;'t see why you wouldn't be able to do this in standalone either, just would a bit more to manage.
-
3. Re: Server group and Server node relation - removal - expected behavior
vandamo Apr 9, 2014 6:32 AM (in response to vandamo)
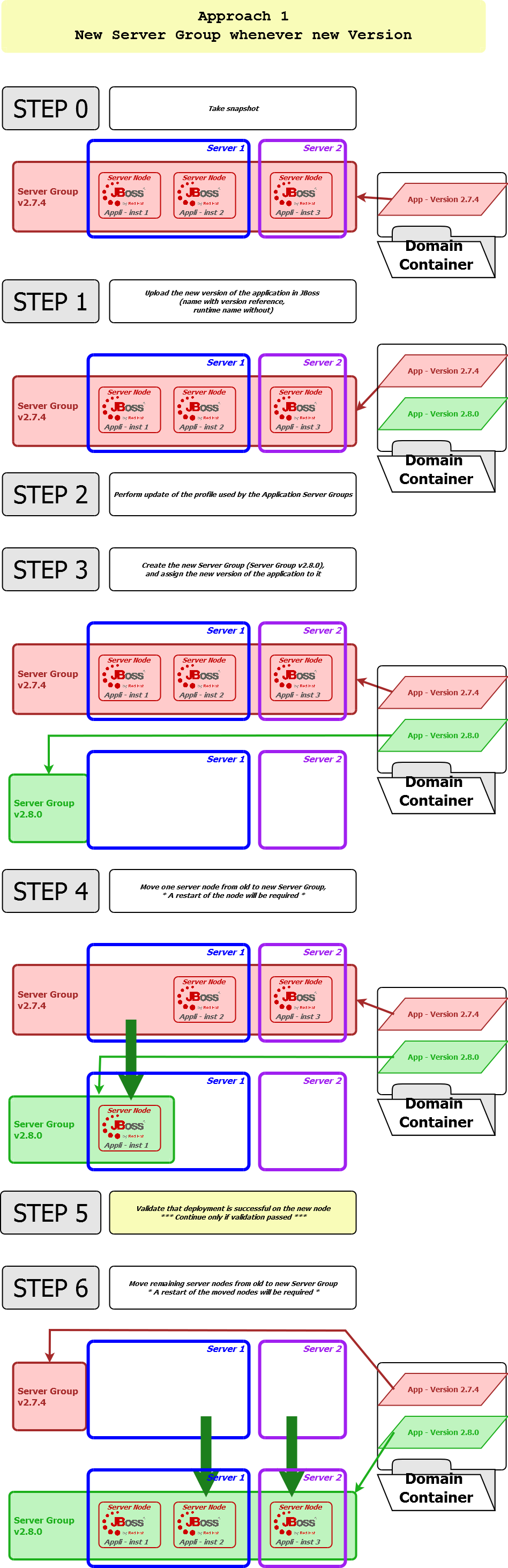
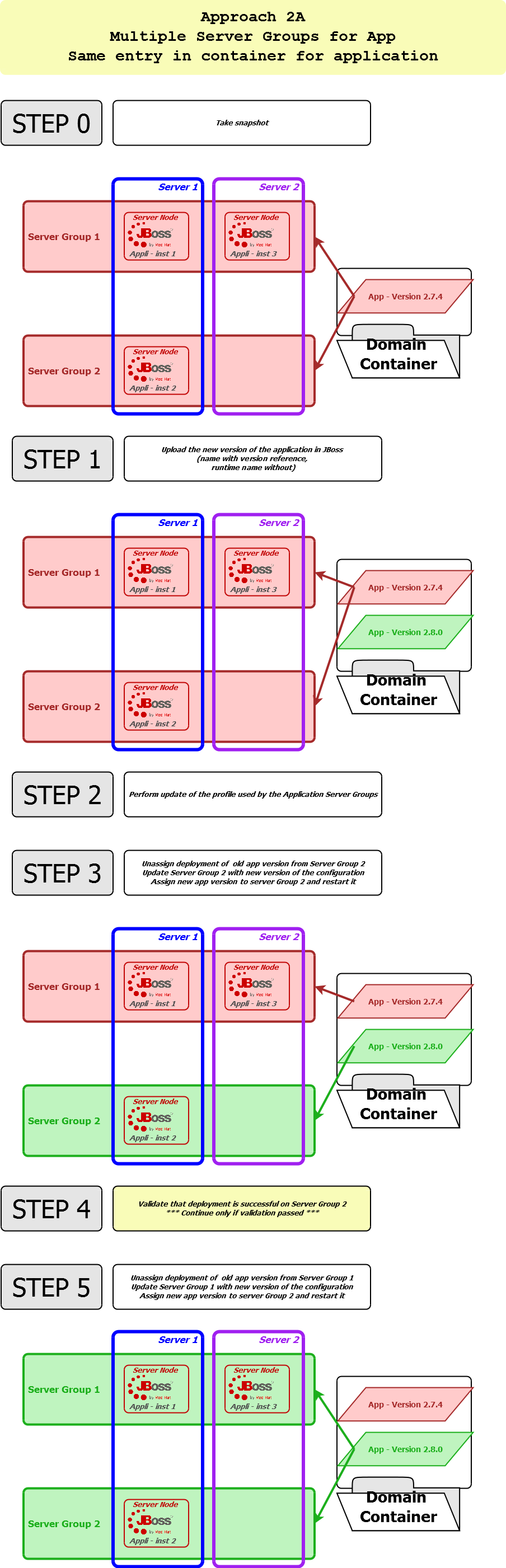
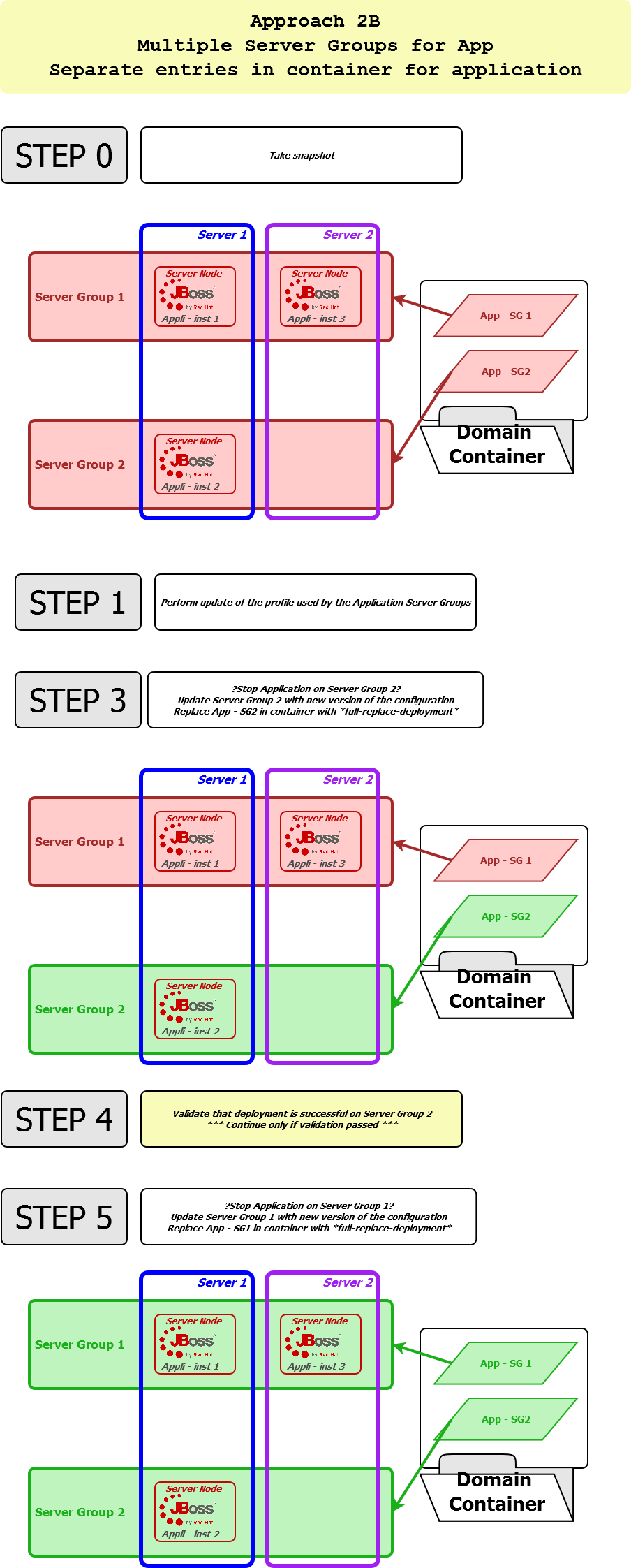
See in attachment some of the scenarios I've been considering to manage the releases (images didn't pass so well when inserted).
Benefit of approach 2B is to not have to manage an application version (read name in container), or alter its assignation to a server group.
Would be happy to hear your views on the recommended approaches, definitely.
As mentioned earlier, another request I got was for the deployment script to be "rerunnable" so that if it was to fail during run, you could just rerun it without having to dig too much. I haven't checked yet how this impacts the viability of each approach currently considered.
-
JBoss_ServerGroup_MigSteps_v1.png 200.6 KB
-
JBoss_ServerGroup_MigSteps_v2.png 180.7 KB
-
JBoss_ServerGroup_MigSteps_v3.png 137.0 KB
-
-
4. Re: Server group and Server node relation - removal - expected behavior
vandamo Apr 11, 2014 2:57 AM (in response to emuckenhuber)
Thanks for the note on server-group removal,
I'll reprocude and enter it as bug unless I find some reference by then explaining the logic of what I've seen.
I've added the deployment options I'm currently considering (separate reply to the main thread), could you let me know your thoughts or indicate some reference to the rollout plans?
Thanks in advance.
-
5. Re: Server group and Server node relation - removal - expected behavior
emuckenhuber Apr 11, 2014 6:58 AM (in response to vandamo)
1 of 1 people found this helpfulThe problem i see with those scenarios is that it seem to contain mandatory? configuration updates, which may result that you have to restart servers. Where just replacing a deployment would not require that. Also if you update a configuration in a profile those changes would get pushed to all servers referencing that profile as part of the server group. So this could potentially affect currently deployed applications.
Basically rollout plans define the way deployments (or operations) are pushed to servers and groups. For example when updating a deployment you can say that this should be rolled out in sequence to server-group-one, after this is complete move on to server-group-two. It also allows you to define whether those deployments should pushed concurrently within a server group or not. Here is a link to the WildFly documentation with a simple example: The native management API - WildFly 8 - Project Documentation Editor
Additionally we support "composite" operations, where you could potentially send configuration updates and the deployment as a single operation. However this would just leave servers in a restart-required state, if configuration changes could not be applied to the runtime directly.
-
6. Re: Server group and Server node relation - removal - expected behavior
vandamo Apr 14, 2014 2:38 AM (in response to emuckenhuber)
Thanks, indeed it is what I was looking for.
From your comment it seems that the rollout-plan approach allows for changes done at profile and server group level to impact the related servers one at a time, is that correct?
If indeed this works like that, I'm not sure I fully grasp how to manage any kind of failure properly, short of a full rollback.
Regarding the composite operations, I had tried out the batch approach during some of my tryouts, but ended with failures when the batch covered the whole update process.
I intended to check further, attempting to identify which specific operation shouldn't be included in the batch, but haven't delved back into that yet.
Currently I'd guess the upload of the application into the JBoss container would be a likely culprit, but haven't tested this assumption yet.
-
7. Re: Server group and Server node relation - removal - expected behavior
vandamo Apr 14, 2014 5:05 AM (in response to vandamo)
Further investigation points more to something related to the scripting interface (scripts in jython), and how the cli.cmd() method works.
Will update this thread once I confirm this.
-
8. Re: Server group and Server node relation - removal - expected behavior
vandamo May 26, 2014 10:56 AM (in response to vandamo)
After reviewing the rollout-plan features, it does not appear I can use it in my current context for the following reasons:
- need to validate deployment on a subset of the nodes (server group or server node) before pushing it completely
- using the rollout-plan would require a batch approach, while this means no try / catch or if / else logic can be implemented as far as I've seen
Indeed in the current scripts I've setup, there is some additional logic around the requests, so that if the configuration file I receive indicates an "add" operation, the deployment script will first check if the element is already present and remove it if need be.
Similarly an "update" operation will test for the element existence and add it if necessary. Otherwise, the deployment script will iterate through the parameters to be updated and use the write-attribute method if available.
Implementing such logic directly in CLI would not be possible in a batch structure from what I've seen
I do take note of your comment and agree that profile changes can be dangerous (although hopefully not very common beyond the original application setup), so will pay particular attention to it.
Regarding the possible need to restart the nodes, I intend to check the server-state attribute to identify if it is needed or not