Configuriung some replication caches are coordinators, and others as read only slaves
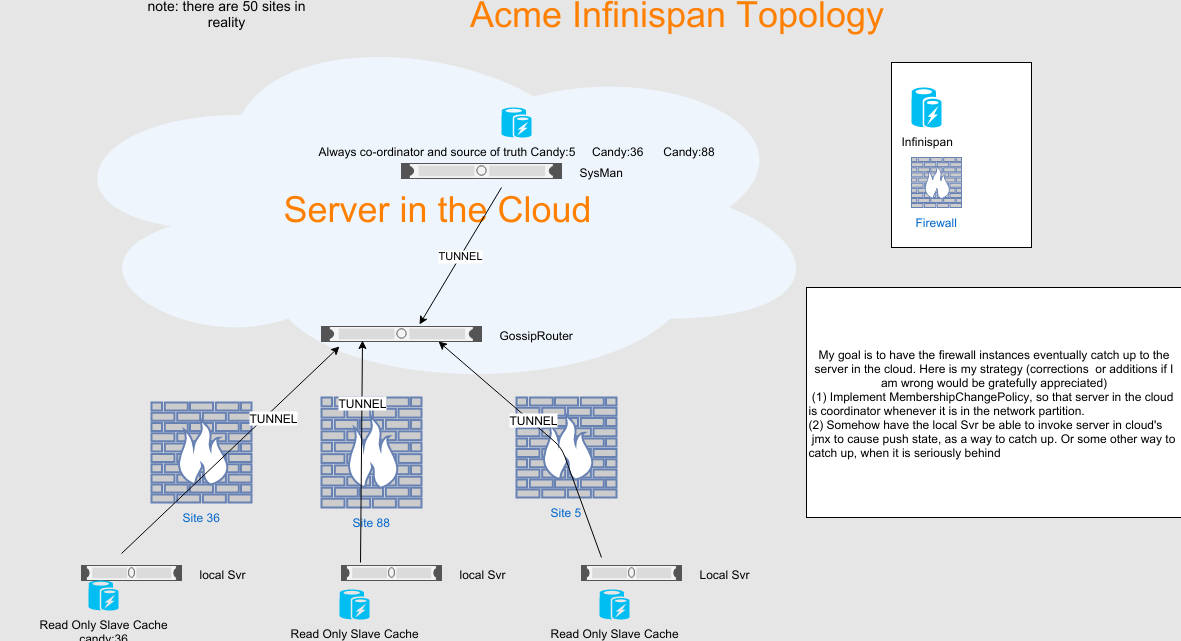
Now that I have Infinispan working, I want to optimize Infinispan so that each site specific read only slave replication cache behind a customer firewall can stay up to date with a source of truth read write master replication cache in the cloud. So any time after network connectivity goes down and then comes back up, I want the slave cache to quickly catch up with the master cache, but the master cache never learns about data from the slave cache.
Below is an image showing the topology. Note all Infinispan instances are embedded in Java webapps. In detail, for each customer site, we have a service running inside the customer's building, behind a customer firewall. Each such site has a replication read only cache for only that single site. So customer site 36 only has an instance of candy:36.
Further below are the jgroups config XML, and the infinispan settings I have set up. Please note that I am using TUNNEL as transport (the firewall allows outgoing port to 12001) . Based on Jgroups documentation here Chapter 7. List of Protocols My idea is to (1) make sure that the cloud server is always the coordinator in MERGE3 algorithm when it is in the partition. (2) I also want to be able for the local server behind the firewall to request (perhaps via JMX) that the cloud server "pushstate" to it if certain conditions are met making it think that its state is stale (is that a good idea?)
Based on the jgroups user guide http://www.jgroups.org/manual/html/user-advanced.html#MembershipChangePolicy I wrote a class that implements MembershipChangePolicy, so that an address of type ExtendedUUID goes to the front of the membership list. The idea is I would only assign that for the cloud instance of infinispan. I also assigned that class in the jgroups config via membership_change_policy="com....LeadershipMembershipChangePolicy. However, I don't understand how I can set an addressGenerator for the channel associated with (some) Infinispan nodes
Thanks in advance, Eliot
<config xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="urn:org:jgroups"
xsi:schemaLocation="urn:org:jgroups http://www.jgroups.org/schema/jgroups.xsd">
<!-- ***Transport Section*** -->
<!-- TUNNEL supports tunneling through a firewall, by having the node open tcp duplex communications to a "gossip router" outside the firewall see http://jgroups.org/manual/index.html#TUNNEL_Advanced
gossip_router_hosts: to the right of : is the default host IPv4 address with port specified inside square brackets.
When the JVM argument '-Djgroups.tunnel.gossip_router_hosts=10.22.0.56[12001],10.44.0.56[12001] is passed at runtime, those hosts will be used instead of the default
The JVM argument should be set to a comma separated list of IPv4 hosts with ports, this default override will be needed by appliance instances (expect for developer workstations because they are colocated with the NOC)
Note: Keeping the port at 12001 is advisable, given that most PAAS senders will expect the Gossip Router to be there
bind_addr: The bind address which should be used by this transport ( I don't understand what that means, see http://jgroups.org/manual/index.html#Transport )
enable_diagnostics: Switch to enable diagnostic probing. Default is true -->
<TUNNEL
gossip_router_hosts="${jgroups.tunnel.gossip_router_hosts:127.0.0.1[12001]}"
bind_addr="GLOBAL"
enable_diagnostics="true" />
<!-- ***Initial Membership discovery*** -->
<!-- Ping based discovery see http://jgroups.org/manual/index.html#PING Note that PING is preferred discovery for TUNNEL -->
<PING/>
<!-- ***Merging after Network Partition*** see http://jgroups.org/manual/index.html#_merging_after_a_network_partition -->
<!-- Merge inconsistent state see http://jgroups.org/manual/index.html#MERGE2
The noc must be the merge leader, never an appliance (we will give the NOC a low UUID address)
max/min_interval controls the ms time interval between member broadcasts... higher numbers cause less chattiness at the cost of slower state merging -->
<MERGE3
max_interval="30000"
min_interval="10000"/>
<!-- ***Failure Detection section*** -->
<!-- Ring based detection see http://jgroups.org/manual/index.html#FD_SOCK -->
<FD_SOCK/>
<!-- Simple heartbeat based detection
timeout: interval after heartbeat after which no response will cause a SUSPECT message
interval: heartbeat broadcast frequency, -->
<FD_ALL
timeout="15000"
interval="3000"/>
<!-- Verifies that a suspected member is really dead by pinging that member one last time see http://jgroups.org/manual/index.html#_verify_suspect
timeout: millisecs to wait for a response from a suspected member -->
<VERIFY_SUSPECT timeout="5000"/>
<!-- ***ReliableMessageTransmission section*** see http://jgroups.org/manual/index.html#ReliableMessageTransmission -->
<!-- NAKACK2 provides provides reliable delivery and FIFO for messages sent to all nodes in a cluster. see http://jgroups.org/manual/index.html#NAKACK
xmit_interval: interval at which missing messages are retransmitted,
xmit_table_num_rows:Number of rows of the matrix in the retransmission table,
xmit_table_msgs_per_row:Number of elements of a row of the matrix in the retransmission table
xmit_table_max_compaction_time:Number of milliseconds after which the matrix in the retransmission table is compacted
discard_delivered_msgs:Should messages delivered to application be discarded -->
<pbcast.NAKACK2
xmit_interval="1000"
xmit_table_num_rows="400"
xmit_table_msgs_per_row="8000"
xmit_table_max_compaction_time="30000"
discard_delivered_msgs="true"/>
<!-- UNICAST2 provides lossless, ordered, communication between 2 members see http://jgroups.org/manual/index.html#UNICAST2
stable_interval: Max number of milliseconds before a stability message is sent to the sender(s)
xmit_interval: Interval at which missing messages are retransmitted
max_bytes: Max number of bytes before a stability message is sent to the sender
xmit_table_num_rows: Number of rows of the matrix in the retransmission table
xmit_table_msgs_per_row: Number of elements of a row of the matrix in the retransmission table
xmit_table_max_compaction_time: Number of milliseconds after which the matrix in the retransmission table is compacted
max_msg_batch_size: Max number of messages to be removed from a RingBuffer
conn_expiry_timeout: Time after which an idle connection is closed -->
<UNICAST2
stable_interval="5000"
xmit_interval="500"
max_bytes="10m"
xmit_table_num_rows="200"
xmit_table_msgs_per_row="10000"
xmit_table_max_compaction_time="10000"
max_msg_batch_size="1000"
conn_expiry_timeout="0"/>
<!-- Message Stability, STABLE garbage collects messages that have been seen by all members of a cluster see http://jgroups.org/manual/index.html#_stable
stability_delay: Delay before stability message is sent
desired_avg_gossip: Average time to send a STABLE message
max_bytes: Maximum number of bytes received in all messages before sending a STABLE message is triggered -->
<pbcast.STABLE
stability_delay="1000"
desired_avg_gossip="50000"
max_bytes="10M"/>
<!-- ***Group Membership section*** see http://jgroups.org/manual/index.html#_pbcast_gms
print_local_addr: print local address of this member after connect. Default is true
join_timeout: self explanatory
view_bundling: Not exactly sure, but true allows multiple views to be bundled whatever that means. ( a view is the
local representation of the current membership of a group see http://jgroups.org/javadoc/org/jgroups/View.html) -->
<pbcast.GMS
print_local_addr="true"
membership_change_policy="com.....LeadershipMembershipChangePolicy"
join_timeout="4000"
view_bundling="true"/>
<!-- ***Flow Control section*** see http://jgroups.org/manual/index.html#FlowControl -->
<!-- (Unicast|Multicast) Sender transmission speed (flow) control (throttling) see http://jgroups.org/manual/index.html#_mfc_and_ufc
max_credits: Max number of bytes to send per receiver until an ack must be received to proceed
min_threshold: The threshold (as a percentage of max_credits) at which a receiver sends more credits to a sender -->
<UFC
max_credits="200k"
min_threshold="0.20"/>
<MFC
max_credits="200k"
min_threshold="0.20"/>
<!-- ***Fragmentation section*** see http://jgroups.org/manual/index.html#_fragmentation -->
<!-- Large Message Fragmentation policy see http://jgroups.org/manual/index.html#_frag_and_frag2
frag_size: max bytes in a message -->
<FRAG2 frag_size="16000" />
<!-- Reliability Related: Augments reliable protocols such as NAKACK2 and UNICAST2 see http://jgroups.org/manual/index.html#RSVP
timeout: Max time to block for an RSVP’ed message
resend_interval:Interval at which we resend the RSVP request
ack_on_delivery: When true, we pass the message up to the application and only then send an ack -->
<RSVP
timeout="60000"
resend_interval="1000"
ack_on_delivery="true" />
</config>
manager = new DefaultCacheManager(GlobalConfigurationBuilder.
defaultClusteredBuilder().
transport().
nodeName("cache").
addProperty("configurationFile", jgroups.xml).
build(),
new ConfigurationBuilder().
persistence().
passivation(false).
addSingleFileStore().
location("/tmp").
eviction().
maxEntries(1000).
strategy(LIRS).
clustering().
// Each cluster will have full data, and a put will not block
cacheMode(CacheMode.REPL_ASYNC).
build());
public class LeadershipMembershipChangePolicy implements MembershipChangePolicy {
@Override
public List<Address> getNewMembership(final Collection<Address> current_members,
final Collection<Address> joiners,
final Collection<Address> leavers,
final Collection<Address> suspects) {
Membership retval = new Membership();
// add the beefy nodes from the current membership first
for (Address addr : current_members) {
if (addr instanceof ExtendedUUID)
retval.add(addr);
}
.....