Consequences of restarting one of participants in a distributed transaction
In short: my question is about the mechanism of committing changes in a distributed transaction. Distributed between two Wildfly server instances. What's important in my examples, is that one of servers is restarted before the transaction ends. Before I go into details, I will describe the run-time environment:
- application server: Wildfly 8.2;
- database server: "PostgreSQL 9.5.5 to x86_64-pc-linux-gnu"; in Wildfly as a XA Datasource with 'postgresql-9.1-903.jdbc4' driver;
- Wildfly configuration is slightly changed relative to base 'standalone.xml' file (not 'full-standalone'!); (the 'jboss.node.name' of each server is unique); each server is running in debug-mode; second server has 100-port-offset;
- I'm starting main method on first server with Eclipse NEON as a client; Eclipse has two 'remote java application' connection - one for each server - for debugging.
I'll describe two cases. First of them – A – involves one datasource in remote server S2 (insertion of simple entity). Second case – B – involves two datasources – one for each server.
Simplified diagram of case A: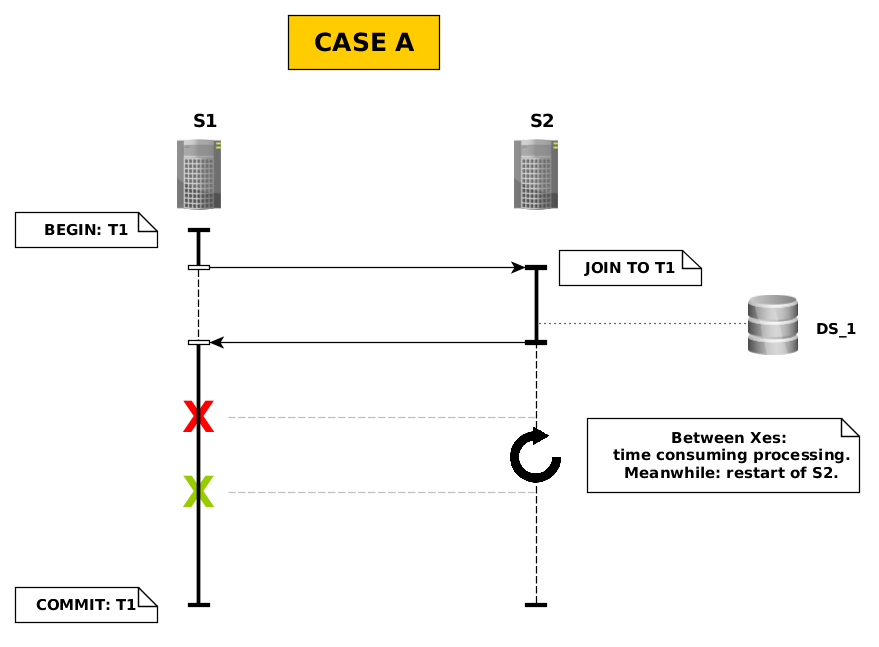
Description of case A:
The first server – S1 – starts main method (@TransactionAttribute = REQUIRED) and, in the same time begins transaction – T1.
First part of mentioned method invokes remote method on the second server; remote method joins to propagated transaction – T1 (@TransactionAttribute = REQUIRED). There's database involved within that method – simple 'INSERT' via XA Datasource – DS_1. After that, control returns to main method on S1.
Imagine that along with first X (the red one) time consuming operation starts within main method on S1. It ends “after” second X (the green one). I've simulated time consuming processing with breakpoint during debugging. What's important – S2 has restarted “between” those X'es (i.e. S2 starts again before "green X").
On S1, within server logs there's INFO message: “EJBCLIENT000016: Channel Channel ID b6b41d02 (outbound) of Remoting connection 438a2403 to /12.3.45.678:4447 can no longer process messages”.
Main method on S1 ends; T1 also. Debugging on 'org.postgresql.xa.PGXAConnection' shows `commit(Xid xid, boolean onePhase)` invocation with 'onePhase = true'.
The point is that after exiting from main method there's no changes in database of datasource DS_1! What's bothers me even more is that there's no ERRORS or EXCEPTIONS - neither on S1 nor S2 logs!
Without restarting S2 – everything works as expected – there's new tuple in database inserted by S2.
Simplified diagram of case B:
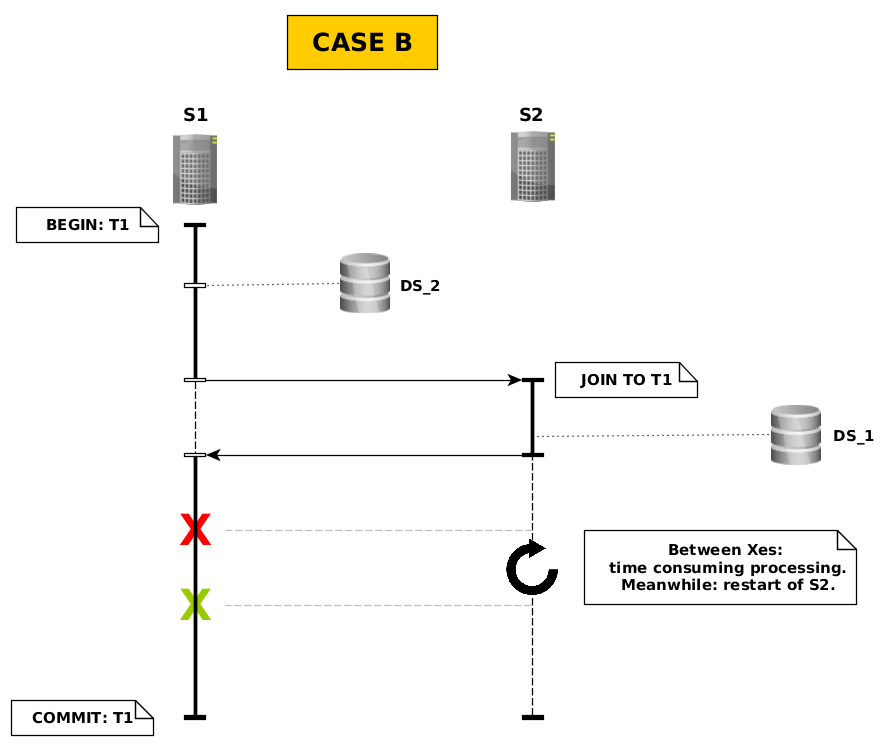
Description of case B:
Invocation sequence is almost the same as in case A – with a additional step in main method on S1. There's simple 'INSERT' that involves database via datasource DS_2.
Again – during restart of S2 – I'v found similar INFO message on S1. At the end of T1 – during commit phase debugging on 'org.postgresql.xa.PGXAConnection' shows `commit(Xid xid, boolean onePhase)` invocation with 'onePhase = false'. I'm assuming that two phase commit took place.
Again: the point is that after exiting from main method there's no changes in database of datasource DS_1; again without any ERRORS or EXCEPTIONS in both servers logs! To make it more interesting change in DS_2 database – 'INSERT' by S1 – was successfully committed!
Let me ensure you that:
- both cases works as expected without restarting participant server;
- I don't want to find solution – I know that “REQUIRES_NEW” is one of them; I want to understand described behavior.
Final questions:
- Is that expected behavior of commit phase at the end of transaction which is spread across two servers? I would rather be expecting EXCEPTIONS during commit phase (even in second phase in 2PC which is “void” one)
- Is there way to configure transactions or datasources to achieve expecting behavior (exceptions during commit)?