Design of replacing both pessimistic and optimistic locking in JBoss Cache with a Java memory based implementation of MVCC.
JIRA - JBCACHE-1151
Background
This is about changing the current locking strategies with JBoss Cache. We currently support optimistic and pessimistic locking, but both these schemes have certain problems:
Pessimistic locking
Poor concurrency - writers block readers
Increased potential for deadlocks (TimeoutException)
Issues when readers upgrade to writers (JBCACHE-87)
Optimistic locking
High memory overhead and low scalability since each reader and writer transaction copies data to a workspace.
Expensive post-transaction comparison phase
Can only implement 1 isolation mode
Overall
Too many configuration/tuning options makes things confusing
Lots of unnecessary code complexity
What is MVCC?
Multi-Version Concurrency Control is a generic term for versioning data to allow for non-blocking reads. RDMBSs often implement some
form of MVCC to achieve high concurrency. Our proposed implementation of MVCC takes advantage of Java memory semantics.
About JBossCache MVCC
Readers all read the node directly
When writing, the node is copied and writes made to the copy.
Exclusive lock obtained on copy.
Only 1 writable copy is maintained per node
Readers aren't blocked during writes
Only 1 writer allowed
(R-R only) When writing (before tx commits, even), the writer compares versions with the underlying node
Either throws an exception (default) or overwrites the node anyway (accept-write-skew option)
Repeatable-Read Example
Cache starts at N(1)
Tx1 reads: has a ref to N(1)
Tx2 reads: has a ref to N(1)
Tx2 writes: has a ref to N(1)'
Tx2 commits: cache is N(2)
Tx1 reads: still sees N(1)
Benefits over optimistic locking
Low memory footprint - only 1 copy per write!
Allows for all isolation modes
More flexible handling of version mismatches (overwrites can optionally be allowed)
Fail-fast when version checking is enabled (failure occurs on write, not commit)
Able to provide forceWriteLock (SELECT FOR UPDATE) semantics, which O/L does not do
Benefits over pessimistic locking
No upgrade exceptions
Better concurrency
Non-blocking reads
No dirty read race in READ_COMMITTED
Other benefits
Much simpler code base to maintain, debug
Single set of interceptors
Locks much simpler, no upgrades
Standard Java references and garbage collection to take care of thread/tx isolation (see implementation design below)
Simpler configuration
Isolation level : READ_UNCOMMITTED, READ_COMMITTED (default), REPEATABLE_READ, SERIALIZABLE
Write-skew handling : Reject (default), Accept
Locking scheme : striped (default), one-to-one
Supported isolation levels
We're considering only supporting READ_COMMITTED, REPEATABLE_READ and SERIALIZABLE. We feel that lower isolation levels are pretty much academic and don't really have much real world use. We're also considering using READ_COMMITTED as a default - this is what most database implementation use to achieve high concurrency.
If lower isolation levels are specified, should we allow this, but substitute for a higher isolation level?
Implementation Design
Errata
The following points have been added to the design after review of the diagrams that follow. Note that some concepts represented in the diagrams may conflict with the errata that follow; the errata will take precedence.
Versioning, along with a write skew check, is not necessary in READ_COMMITTED since doing a write at any time means the exclusive writer would be expected to update the last committed version. As such, READ_COMMITTED would delegate to an UnversionedNode instead of a VersionedNode, and the write skew check would be skipped.
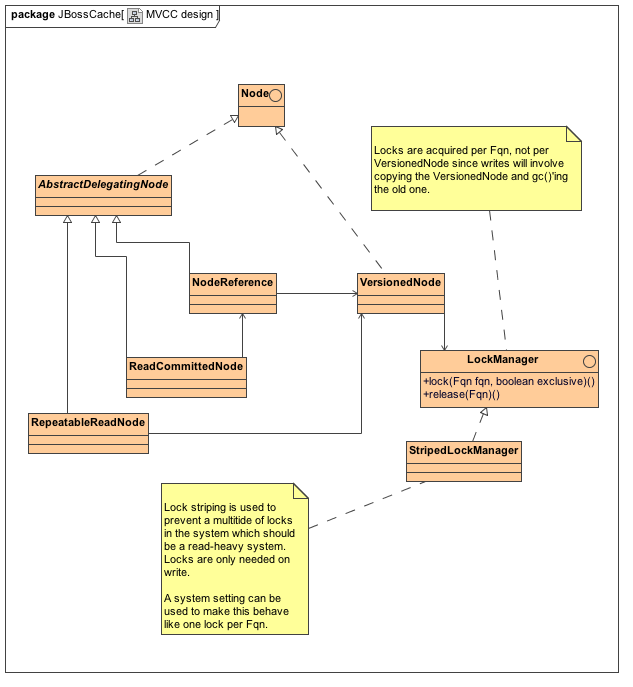
Locks should be acquired directly by querying a LockManager implementation (either StripedLockManager or PerNodeLockManager, or maybe even in future DistributedLockManager) rather than making lock() and unlock() calls on the node directly. While doing this on a node is cleaner in an "OO" purist view, it does bring up problems seen with the current pessimistic locking approach where, for example, attempting a delete on a node that does not exist entails creating the node just so the lock can be obtained and then deleting it again.
RepeatableReadNode doesn't need to hold a reference to the original node (repeatable read sequence diagram, step 26) since this can be peeked afresh.
For the sake of transactions, all "updated" node copies made (when attempting a write) should have their references placed in the TransactionEntry. Future reads in the same transaction (such as repeatable read sequence diagram step 6) should first consult the TransactionEntry in case a reference to the copy should be used before doing a peek.
Overview
Basic class diagram of relevant bits
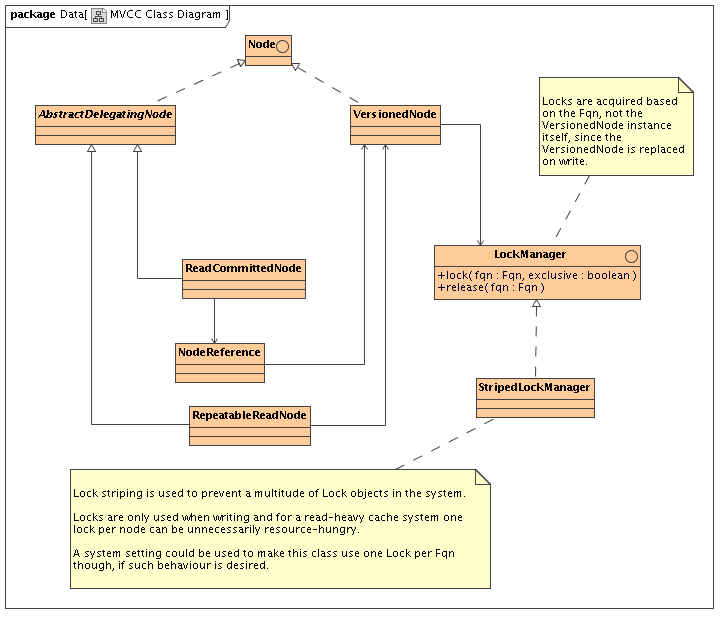
Description
When a user gets a hold of a Node using Cache.getRoot().getChild() we will return a new instance of ReadCommittedNode or RepeatableReadNode every time.
AbstractDelegatingNode subclasses are very lightweight objects that just hold a reference, and cheap to construct
RepeatableReadNode holds a reference to VersionedNode in the cache and delegates calls to it
ReadCommittedNode holds a reference to a NodeReference, which holds a volatile reference to a VersionedNode and delegates calls to it
REPEATABLE_READ
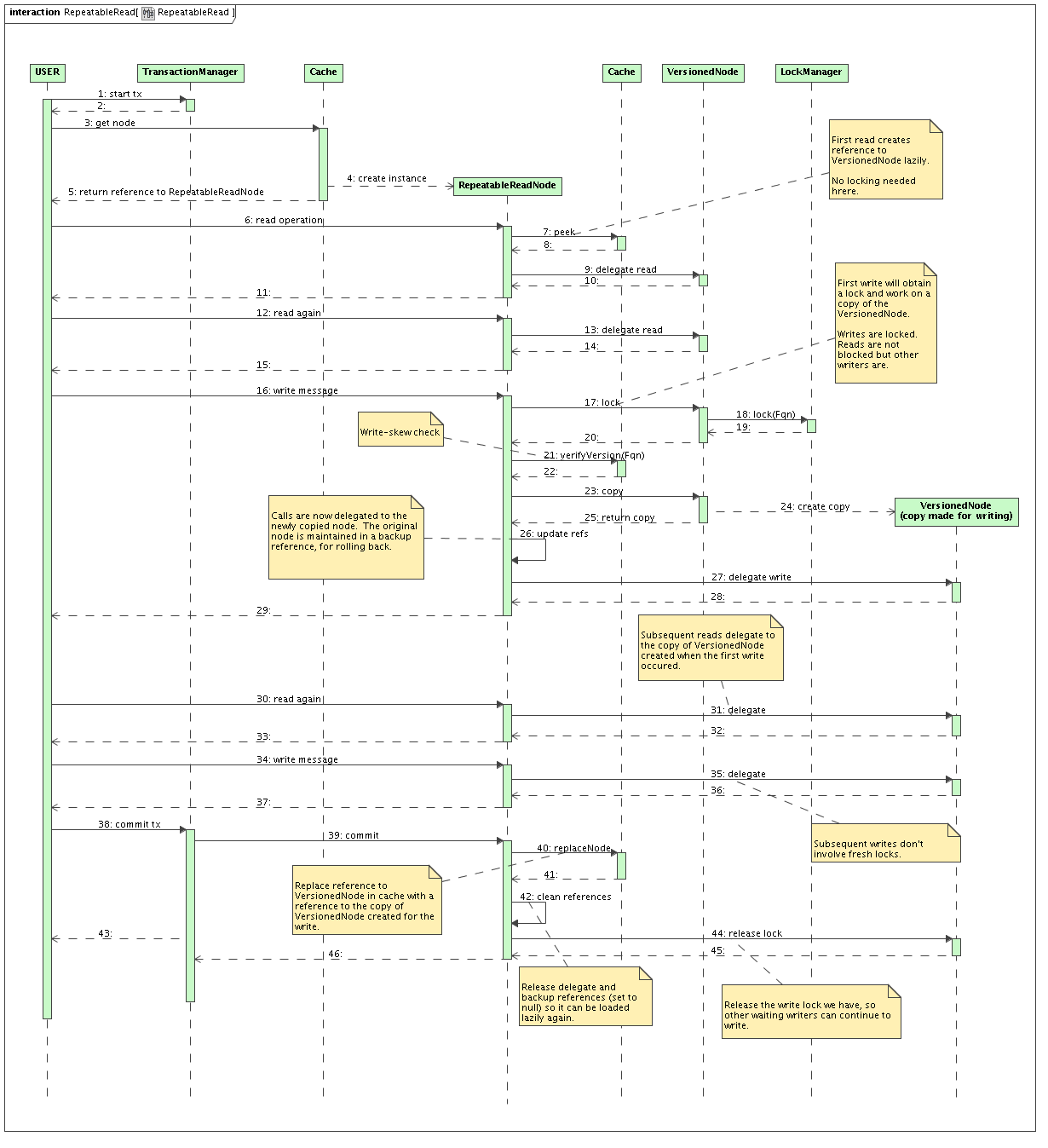
Readers all end up delegating calls to the VersionedNode.
Reference to VersionedNode created lazily on first invocation.
When writing,
Acquire exclusive Fqn lock (see section on locking below)
The version of the reference held in RepeatableReadNode is checked against version in the cache (to detect write skew)
copies the VersionedNode
since exclusive lock is held, only one write-copy per node will ever exist
increments it's version
backs up it's original VersionedNode reference
and updates it's delegate reference to the newly copied VersionedNode
When committing
Replaces the original VersionedNode in the cache with the write copy
Discards backup pointer
Discards VersionedNode reference so this is fetched lazily when the next transaction starts, in case the RepeatableReadNode instance is reused.
Repeatable read is achieved since:
Readers all still point to their version of VersionedNode (reference still held by other RepeatableReadNode instances)
Writer works with it's copy of VersionedNode
READ_COMMITTED
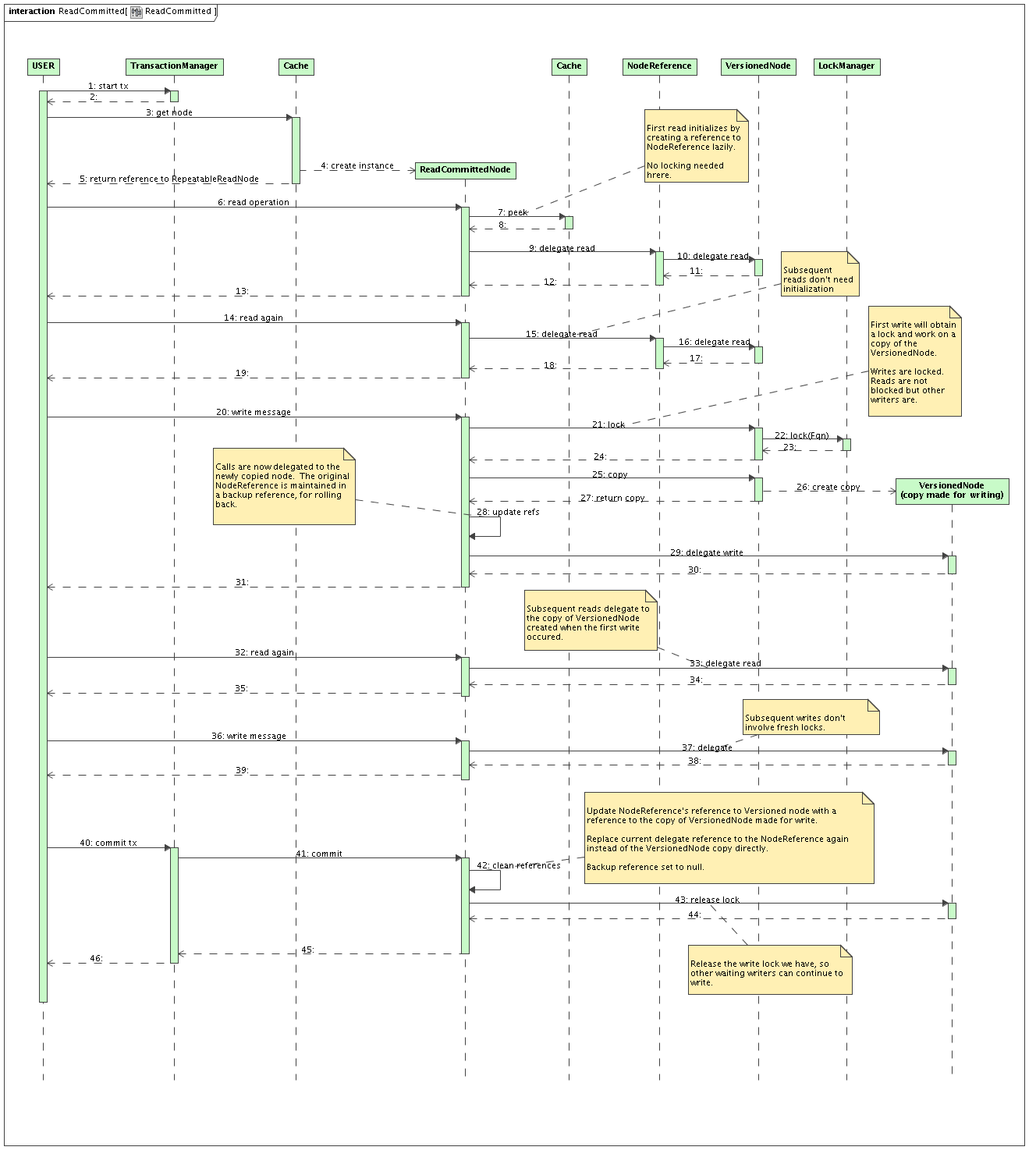
Exactly the same as REPEATABLE_READ, except that:
ReadCommittedNode has a reference to NodeReference rather than VersionedNode
No version check is done when a write starts (write skew is not a problem with READ_COMMITTED)
When committing
ReadCommittedNode reinstates the reference to the NodeReference
Updates the NodeReference to point to the copy of VersionedNode
Read committed achieved by:
Readers and writers working delegating to a VersionedNode via the NodeReference
NodeReference updated when a writer commits - and everyone sees this commit
Locking
Locks still needed for the duration on a write (exclusive write)
No locks needed when reading
All locks should be on the Fqn, not the VersionedNode itself since this is replaced
Implemented using lock striping to reduce the number of locks in the system if there are a large number of nodes.
VersionedNode still exposes lock() and release() methods
Delegates to LockManager.lock(Fqn) and release(Fqn)
LockManager is an interface, configurable.
StripedLockManager uses something similar to o.j.c.lock.StripedLock (used by cache loader implementations at the moment)
Implementation details
MVCC will be implemented using 3 interceptors: an MVCCLockingInterceptor, an MVCCNodeInterceptor, and an MVCCTransactionInterceptor, which would be responsible for acquiring the locks needed (in the case of a write), creating of a wrapper node for the invocation, and the switching of references at the end of a transaction respectively.
Documentation
TODO: Illustrate MVCC behaviour visually, during concurrent writes, creates, deletes, create + delete.
Tombstones
When a node is deleted, a tombstone will need to be maintained to ensure version numbers are maintained for a while.
Drawbacks
Creation of a RepeatableReadNode or ReadCommittedNode with every call to Cache.getRoot().getChild()
Efficient if this is cached and reused all the time
cache.put(Fqn, Key, Value) will probably call getRoot().getChild(Fqn).put(Key, Value)
This may be less efficient since doing something like for (int i=0; i<100; i+) cache.put(fqn, keyi, value+i) will result in 100 AbstractDelegatingNode instances created.
This can be minimised by optimisations such that a peek() for nodes happens only once per call, and put it in the InvocationContext. All interceptors look first in IC for the node - if null, peek() and set in IC. If transactional, IC mapped to TxCtx. (Necessary for calls directly to Cache.get(), Cache.put() in MVCC to maintain refs to the same RRNode/RCNode for the duration of a Tx)
Always does a copy on write. Could be expensive.
But caches are meant to be optimised for reading anyway.
Timescales
The plan is for this to be in JBoss Cache 3.0.0. JBoss Cache 2.0.0 is close to release now, and the next major release will be JBoss Cache 2.1.0, which will make use of JBoss AOP and JBoss Microcontainer. The original plan was to create JBoss Cache 2.2.0 with partitioning, but MVCC (and regions as a top level construct) may be higher priority features that may warrant 3.0.0 to be elevated in importance and partitioning to be pushed to 3.1.0.





Comments