With the changes in Teiid 8.x coming on-line and the use of Dynamic VDB's in Openshift becoming more visible, it's apparent that Teiid's primary tooling (Teiid Designer) should investigate embracing these concepts and adapt accordingly.
Over the past couple of weeks, the Teiid Designer and Teiid team have collaborated to understand their direction for 8.x and develop a plan take advantage of it in our Tooling/UI. At the heart of this new direction is the adaptation of a common Teiid DDL dialect for relational data definition.
Options for incorporating elements of Teiid's new direction could be accomplished through drastically modifying/removing Designer's current underlying EMF framework or developing anew from a fresh perspective. Because of the size and inertia of Designer's current code-base, we deemed it beneficial to choose the latter approach.
So over the next few months, the Teiid Designer community will spend some time and effort developing and prototyping a framework and initial UI dedicated to providing a compact/simplified DDL-based design tool. This framework and prototype will be referred to as "Komodo" (a type of lizard akin to Teiid, the whip-tail lizard). Komodo, based on it's maturity and applicability, could eventually replace Teiid Designer at some point in the future.
 Links....
Links....
General Meeting Notes: http://community.jboss.org/wiki/KomodoDevelopmentMeetingNotes
- See attachment (Designer Overview.pdf) for general summary of Komodo initiative
UI Prototyping: https://issues.jboss.org/browse/TEIIDDES-1535
CLI Concept: https://community.jboss.org/docs/DOC-52699
Data Source Definition in Komodo
Procedure and Function definition
Komodo > Polyglotter Integration
Roadmap
June - September 2014
- Initial migration of code from Designer, including teiid client, teiid SPI and relational models
- Remove unnecessary Eclipse dependencies from migrated codebase
- Provide initial modeshape library plugin
- Implement initial prototype for a komodo CLI using the S-Ramp shell.
- Create a modeshape sequencer for Teiid SQL using the Teiid javacc template
- Generate a CND file describing the typing information of the SQL, eg. Select, From, Symbol etc...
- Generate an SQL Lexicon that references all CND types and their attributes for use in the Sequencer.
October - November 2014
- Prototype of the KEngine base classes and repository support
- Create a CND for the relational schema (DDL) in order to store modelling artifacts in repository
- Relational model objects delegates to JCR nodes so former do not retain any state, only latter
- Sequencer to store relational schema (DDL) objects in the repository
- Desequencer to restore relational schema (DDL) objects from the repository into memory
- Further integrate KEngine and modelling objects into CLI
- Create a file importer to import a DDL model into the repository
- Question of Modeshape handing off Teiid SQL from the DDL Sequencer to the TSQL Sequencer?
- Construct API and framework for deployment of a simple VDB through the CLI
December 2014 - February 2015
- MILESTONE 1 : Headless End-to-End with CLI?I (1/22/2015)
- Fire up Komodo for the first time
- Specify a name and location for the KSpace (workspace)
- Define a VDB
- Import DDL (Source Model)
- Display/list Tables and columns for a table
- Change a Table name
- Add a column
- Export the DDL (Source Only)
- Create a View Model
- Add a View
- Add column(s)
- Define SQL for view
- Export the View Model DDL
- Export a VDB.xml (dynamic VDB)
- Fire up Komodo for the first time
- MILESTONE 2 : Publish Tech Preview of Komodo CLI (2/31/2015)
- Eclipse and WEB applications
- Create/Select and open new Workspace
- Define a VDB using UI actions/dialogs/panels to accomplish same steps as in Milestone 1
- Eclipse and WEB applications
March 2015
- Define and deploy datasources
- Data Source Definition structure (CND)
- First step Generic JDBC connection properties (URL, uname, pwd, jar/driver)
- Data Source Definition structure (CND)
April 2015
- Initial integration of Modeling Engine
- Define resolving and validation framework - use of Teiid's or complete rolling of our own?
- Define DDL/Relational editing requirments and API
- Define and refine initial modeling scope and behavior
- Single-VDB perspective?
- Multiple VDBs?
March - April 2015
- Initial Eclipse-UI integration
- Read/Write DDL
- Tree display of VDB's and contents (models, etc...)
- May be add-on to Designer to share Server view/framework?
- MILESTONE 2 : Eclipse Komodo perspective (30/04/2015)
- Design and prototype VDB/Model Editor
- Utilize Polyglotter/Modeshape Modeler?
The following outlines the major conceptual changes envisioned for Komodo:
- DDL (Data Definition Language)
- DDL statements, fragments, etc.. (reusable components)
- TEIID DDL Dialect is the de facto DDL Dialect
- DDL files (models/schema) may contain UI/user/workspace specific info (i.e. diagram info?) that is NOT Teiid DDL
- How will Komodo handle this info?
- Will Teiid DDLParser be able to ignore Statements and/or info that's Not in their expected Statement types?
- Connection Profiles
- Contains similar properties/info as Eclipse DataTools profiles
- Would also be customized for certain DB types to include MORE info
- Example: Flat File source would be expanded to determine column names and datatypes
- DDL (Data Definition Language)
- Remove the need to manage multiple model types (i.e. Relational, Source, View, Web Services, XML Documents, Function and Extension)
- INDEX (source)
- Utilize legacy Dimension Designer's "VDB Explorer"
- VDB is primary deployable artifact
- Komodo exclusively implements Teiid's Dynamic VDB functionality
- one or more local "K-Spaces"? D-Space?
- zero or more "remote/shared" K-Spaces
- Be able to browse and search any K-Space based on permissions
- Copy/paste nodes
- Delete (local)
6) Adapt a new Global Workspace location concept
- The basic Eclipse framework provides a standard workspace paradigm which allows switching between workspaces.
- One of the drawbacks to switching workspaces is a that any data or info that's persisted in the ".metadata/plugins" folders will not get transferred and readily available in the new workspace.
- One example is DTP connection profiles. In order to transfer the CP's, users need to "export" the profiles and re-import them in the DTP Data Source Explorer.
- By defining a Global Workspace Location on a user's file system, Komodo can take advantage of persisting common data outside of Eclipse
- Komodo will include a feature to define a current "Default Global Workspace Location".
- At launch time, this cached location will import/load all pertinent data into the current workspace
- Resuable components or data may include
- Data Source Definitions
- Server configurations
- Komodo Repositories (i.e. sandbox, development, production, etc....)
- By keeping common data in a GWL, when user add/removes/edits this data and switches Eclipse workspaces, then the modified data will automatically be available in that new workspace.
Editor Engine Development
Komodo's modeling framework will be designed to be tested headless so it can be accessed via multiple/different CLI or UI design tools.
This "Editor Engine" will allow performing the many create, edit, cut, copy, paste operations on any applicable object or artifact accessable in a Komodo (Designer) Modeshape repository.
Editable artifacts
- VDB
- Schema
- Table
- Columns (datatypes)
- Constraints (FK, PK, UC)
- Index
- View
- Columns
- SQL
- Column
- Procedure
- Parameter (datatypes)
- Result Set
- Function
- Parameter
- ResultSet
- Connection
- Data Source
Maybe an EditorFactory that can provide an "Editor" object for each object type??
- VDBEditor
- SchemaEditor
- TableEditor
- addColumn(Column col)
- createColumn(String name, String dType,....) etc..
- setNameInSource(), setXXXXX()
- ColumnEditor
- ....
Adapting ModeShape Technology:
With the direction of moving to a simpler, DDL-based VDB definition, it's even more apparent that ModeShape could handle our business model needs.
Summary/Vision
- JCR workspaces allow definition of nodes, properties and references.
- MS already has a DDL Sequencer containing a handful of different dialects on top of SQL-92
- Teiid Dialect would have to be added
- And possibly we'd create our own sequencer CND (compact node definition) which would meet the exact needs of TDK
- The full business object model for a user's workspace ((parsing/ seqencing DDL + VDBs + TDK-specific data) would be loaded into a local MS repository including references (i.e. links)
- Refactoring (rename/move/delete) framework would likely be greatly improved over current Designer
- VDB's (defined only by their vdb.xml) would also be sequenced and in-memory and refactorable (not in current Designer)
- MS already has 2 available full repository file-persistence options (read/write)
- VDB seqencing is in the works and is close to being available for the "vdb.xml"
- ModeShape has support for querying content, and this could be leveraged for internal features (e.g., rename, resolution, etc.) or even to expose to users (e.g., a "search" area on an editor.
- If the ModeShape repository persisted content locally to the file system (e.g., within ".metadata"), then the "saving" of the editor (e.g., writing out a file to the Eclipse workspace) can be decoupled from the "saving" of the model content in the repository. The latter can be done very frequently, while the former can happen only when the user wishes to save their editor and would involve only exporting/writing the content to the file system.
- Komodo codebase could easily use the JCR API (perhaps with some decorator objects, functions, or other patterns to encapsulate the JCR API usage) and take advantage of the nodes being able to store any properties. The JCR node types aren't required (i.e., the node structures aren't constrained by a "schema"), or they can be used to have the repository validate the structures. (Note that repository validation is not akin to model validation; the repository will never allow storing a node that is invalid.) In short, there's a lot of flexibility here. And it's extremely extensible and can evolve over time.
- The repository can also be used for "importing" and creating the transient representation of the metadata loaded from an external system. For example, "importing DDL" could consist of loading the DDL file into an area of the repository, running the DDL sequencer to extract nodes and properties that represent each of the statements (e.g., a node-based AST of the DDL statements), and then having the importer simply navigate and use those extracted/derived nodes. ModeShape 3.1 will also have a JDBC Metadata connector, which connects to a data source, reads the database metadata, and constructs nodes representing the tables, views, procedures, etc. (I'm not sure whether JDBC import will be a feature of Komodo, or whether it will all be DDL-oriented.)
- The large model behavior is accomplished because ModeShape can persist content to disk, yet materialize into memory each of the nodes that are needed by the JCR client (the TDK in this case).
- If the core modeling functionality of TDK is written without dependencies to Eclipse (e.g., just a regular Java library with POJO APIs), then it's possible to create a web-based version of the TDK that can be deployed on JBoss AS7, where ModeShape runs as a service.
BO's/business model will be drastically easier to test than in EMF Teiid Designer
// PROBABLE VDB.XML target structure
<?xml version="1.0" encoding="UTF-8" standalone="yes"?><vdb name="twitter" version="1">
<description>Shows how to call Web Services</description>
<property name="UseConnectorMetadata" value="cached" />
<model name="twitter">
<source name="twitter" translator-name="rest" connection-jndi-name="java:/twitterDS"/>
</model>
<model name="twitterview" type="VIRTUAL">
<metadata type="DDL"><![CDATA[
CREATE VIRTUAL PROCEDURE getTweets(query varchar) RETURNS (created_on varchar(25), from_user varchar(25), to_user varchar(25),
profile_image_url varchar(25), source varchar(25), text varchar(140)) AS
select tweet.* from
(call twitter.invokeHTTP(action => 'GET', endpoint =>querystring('',query as "q"))) w,
XMLTABLE('results' passing JSONTOXML('myxml', w.result) columns
created_on string PATH 'created_at',
from_user string PATH 'from_user',
to_user string PATH 'to_user',
profile_image_url string PATH 'profile_image_url',
source string PATH 'source',
text string PATH 'text') tweet;
CREATE VIEW Tweet AS select * FROM twitterview.getTweets;
]]> </metadata>
</model>
<translator name="rest" type="ws">
<property name="DefaultBinding" value="HTTP"/>
<property name="DefaultServiceMode" value="MESSAGE"/>
</translator>
</vdb>
// Pontential VDB.XML target structure based on where Teiid ends up for their 9.x/10.x release
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<vdb name="twitter" version="1">
<description>Shows how to call Web Services</description>
<property name="UseConnectorMetadata" value="cached" />
<model>
<metadata import-type = "DDL"><![CDATA[
CREATE FOREIGN SCHEMA TWITTER (connection-jndi-name="java:/twitterDS":translator-name="rest")
CREATE VIRTUAL PROCEDURE getTweets(query varchar) RETURNS (created_on varchar(25), from_user varchar(25), to_user varchar(25),
profile_image_url varchar(25), source varchar(25), text varchar(140)) AS
select tweet.* from
(call twitter.invokeHTTP(action => 'GET', endpoint =>querystring('',query as "q"))) w,
XMLTABLE('results' passing JSONTOXML('myxml', w.result) columns
created_on string PATH 'created_at',
from_user string PATH 'from_user',
to_user string PATH 'to_user',
profile_image_url string PATH 'profile_image_url',
source string PATH 'source',
text string PATH 'text') tweet;
CREATE VIEW Tweet AS select * FROM twitterview.getTweets;
CREATE FOREIGN SCHEMA PARTSSUPPLIER (connection-jndi-name="parts-oracle":translator-name="jdbc");
CREATE FOREIGN TABLE PARTSSUPPLIER.PART (id integer PRIMARY KEY, name varchar(25), color varchar(25), weight integer);
CREATE VIRTUAL SCHEMA PARTS_VIEWS;
CREATE VIEW PARTS_VIEWS.PARTS (
PART_ID integer PRIMARY KEY,
PART_NAME varchar(255),
PART_COLOR varchar(30),
PART_WEIGHT varchar(255)
) AS
SELECT
a.id as PART_ID,
a.name as PART_NAME,
b.color as PART_COLOR,
b.weight as PART_WEIGHT
FROM PARTSSUPPLIER.part a, PARTSSUPPLIER.part b WHERE a.id = b.id;
CREATE FOREIGN SCHEMA PRODUCT (connection-jndi-name="product-oracle":translator-name="jdbc");
CREATE FOREIGN TABLE PRODUCT.Customer (
id integer PRIMARY KEY,
firstname varchar(25),
lastname varchar(25),
dob timestamp);
CREATE FOREIGN TABLE PRODUCT.Order (
id integer PRIMARY KEY,
customerid integer,
saledate date,
amount decimal(25,4) CONSTRAINT FOREIGN KEY(customerid) REFERENCES Customer(id));
CREATE VIRTUAL SCHEMA PRODUCT_VIEWS;
CREATE VIEW PRODUCT_VIEWS.CustomerOrders (
name varchar(50),
saledate date,
amount decimal) OPTIONS (CARDINALITY 100, ANNOTATION 'Example')
AS
SELECT
concat(c.firstname, c.lastname) as name,
o.saledate as saledate,
o.amount as amount
FROM Customer C JOIN Order o ON c.id = o.customerid;
]]>
<metadata>
</model>
<translator name="rest" type="ws">
<property name="DefaultBinding" value="HTTP"/>
<property name="DefaultServiceMode" value="MESSAGE"/>
</translator>
</vdb>
BASIC TEIID DDL DEFINITIONS:
Source Function ("CREATE FOREIGN FUNCTION") - A function that is supported by the source, where Teiid will pushdown to source instead of evaluating in Teiid engine. (AKA Pushdown Function)
CREATE FOREIGN FUNCTION SCORE (val integer) RETURNS integer;
Source Procedure ("CREATE FOREIGN PROCEDURE") - a stored procedure in source
CREATE FOREIGN PROCEDURE proc (x integer, VARIADIC z integer) returns (x string);
Function/UDF ("CREATE VIRTUAL FUNCTION") - A user defined function, where user can define the calling semantics using below, however the function implementation is defined using a JAVA Class.1
CREATE VIRTUAL FUNCTION celsiusToFahrenheit(celsius decimal) RETURNS decimal OPTIONS (JAVA_CLASS 'org.something.TempConv', JAVA_METHOD 'celsiusToFahrenheit');
Virtual Procedure ("CREATE VIRTUAL PROCEDURE") - Similar to stored procedure, however this is defined using the Teiid's Procedure language and evaluated in the Teiid's engine.
CREATE VIRTUAL PROCEDURE getTweets(query varchar) RETURNS (created_on varchar(25), from_user varchar(25), to_user varchar(25),
profile_image_url varchar(25), source varchar(25), text varchar(140)) AS
select tweet.* from
(call twitter.invokeHTTP(action => 'GET', endpoint =>querystring('',query as "q"))) w,
XMLTABLE('results' passing JSONTOXML('myxml', w.result) columns
created_on string PATH 'created_at',
from_user string PATH 'from_user',
to_user string PATH 'to_user',
profile_image_url string PATH 'profile_image_url',
source string PATH 'source',
text string PATH 'text') tweet;
A FOREIGN TABLE is table that is defined on PHYSICAL model that represents a real relational table in source databases like Oracle, SQLServer etc. For relational databases, Teiid has capability to automatically retrieve the database schema information upon the deployment of the VDB, if one like to auto import the existing schema. However, user can use below FOREIGN table semantics, when they would like to explicitly define tables on PHYSICAL models or represent non-relational data as relational in custom translators.
CREATE FOREIGN TABLE Customer (id integer PRIMARY KEY, firstname varchar(25), lastname varchar(25), dob timestamp);
A VIEW is a virtual table. A view contains rows and columns,like a real table. The fields in a view are fields from one or more real tables from the source or other view models. They can also be expressions made up multiple columns, or aggregated columns. When column definitions are not defined on the view table, they will be derived from the projected columns of the view's select transformation that is defined after the AS keyword.
CREATE VIEW MyView (...) OPTIONS ("foo:mycustom-prop" 'anyvalue');
Is the catalogue / editor paradigm the most appropriate?
The standard Eclipse (and many other tools) windowing system tends towards the pattern of a tree view down the left side of the screen (the catalogue) that contains the data nodes of the tool, eg. projects. By interacting with a data node (clicking / menu action), an editor can be displayed in the centre of the screen allowing the node's data to be modified. Is this paradigm the most appropriate for the workflows required for creation of a VDB.
- + Simple and familiar
- + In-line with the Eclipse windowing system
- - Can quickly become cluttered if too much detail is displayed (and maybe slow)
- - Can distort the workflow in that the user does not know what to click on next
- - Other views / tools have to be introduced to guide the user through the application
What is the purpose of the application?
Designer's aim, and Komodo's, is the configuration of a VDB from a set of data sources. Thus, my inputs of the task are data sources while the output is a VDB file (and maybe accompanying ancillary resources). Thus, maybe the application should start with a blank VDB and target the user towards 'filling' in the blank bits, eg. creating a blank word processing document. This would put the VDB front-and-centre in the mind of the user. Also, it would have the potential for providing templated VDBs, ie. pre-filled-in VDBs that are tailored towards particular data sources. This would be different from Designer as its workflow is to start from the modelling of the data sources and only reaches the defining of the VDB as the 4/5th step in the process. Consequently, it is easy for the user to become 'bogged down' in the modelling of the data sources with no clear direction towards where the modelling is getting them to.
Data sources created from the context of a VDB definition could be tagged at creation time to be added to a local (or remote) library of data source definitions for re-use.
Creating Eclipse plugins implies the Eclipse API but does it imply the Eclipse design?
Eclipse is an IDE for programmers. Tailoring the tool into an application for users (in this case middleware administrators / developers) is a necessity. Concepts like context menus tend to confuse users and the right-click is not always obvious and the popup menu is not intuitive (Context menus are also slow because of the right-click, select action and left-click). Designer is already moving away from such concepts with the introduction of the guides view. Can we go further in coming up with our own UI concepts / widgets that would better fit the tool's workflow.The use of Eclipse views can make an application dynamic but can also lead to confusion. Opening the Teiid-Designer perspective, the user is presented with 7-8 different Eclipse views:
- Model Explorer - the catalogue holding the projects and sub-project data nodes;
- Properties - displaying the properties of selected data nodes;
- Description - displaying of selected data node's description property;
- Guides - step-by-step actions for common functionality;
- Status - console for the status of data nodes in the active project;
- Problems - console for the display of compilation / validation problems in all open projects;
- Error Log - console for the display of underlying system errors in the application instance;
- Teiid - display of all configured teiid server instances.
For the first-time user, this could be considered too many views.
- The Properties and Description views are only useful if populated and if the user wishes to see them;
- The Status and Problems views are performing very similar functions and would be better combined?
- The Error Log is not a useful view for most users and is probably only displayed due to Eclipse displaying it to start with?
- The Teiid view is always hidden by the Problems and Error Log views whilst realistically it is more important than both of them.
The Model Explorer and Teiid views represent the core purpose of the application, ie. create VDB in project -> add it to teiid instance. Thus, these concepts should be bound closer together rather than separated in different views. The Guides view is performing the binding but its priority could be emphasized by something more than a view.
- Maybe a 'Welcome Page' style view that sits on top of all the views?
- Single VDB editor, displaying a network style graph with the VDB at the centre.
- Drag-n-drop data sources (add from toolbar button) onto the network graph that automatically become 'data source' nodes with arrows pointing at the VDB node
- Toolbar buttons for preview and deploy VDB (maybe preview could run a simulation and animate / annotate the network graph)
- VDBs could be deployed directly from the graph and be decorated as "Deployed" with access to where/what server(s)
- Data sources that are deployed to server(s) would also be decorated to indicated "Deployed"
- Users could "Add Data Source to VDB" but action, pulling/importing data source from connected "server".
- This DS could be from an existing deployed VDB (import VDB use-case)
- Begin with a PDF-style template for the VDB
- Click on a block in the template and a new view / wizard is displaying allowing for configuration of data sources
- Wysiwyg and source tabbed editor so manual creation of VDB could be constructed?
To be continued ...
Primary Design Areas
- Business Model Develoment
- ModeShape Integration
- Teiid Integration
- UI Re-design
The following is a list of editable objects and their relevant edit actions.
Relational Objects
All
- Set Name
- Set Name In Source
- Set Description (Annotation)
- Create
- Rename
- Delete
- Set Property
Schema
== CHILDREN ==
- Add Table(s)
- Remove Table(s)
- Add View(s)
- Remove View(s)
- Add Index(s)
- Remove Indexe(s)
- Add Function(s)
- Remove Function(s)
- Add Procedure(s)
- Remove Procedure(s)
Table
== CHILDREN ==
- Add Column(s)
- Remove Column(s)
- Move Column(s)
- Add Foreign Key(s)
- Remove Foreign Key(s)
- Add Access Pattern(s)
- Remove Access Pattern(s)
- Add Unique Constraint(s)
- Remove Unique Constraint(s)
- Add Primary Key
- Remove Primary Key
Column
- Set Datatype
- Set Datatype property (length, precision, etc....)
== CHILDREN == (none)
Primary Key
- Set Column Reference(s)
Access Pattern
- Add/Remove Column Reference(s)
Unique Constraint
- Add/Remove Column Reference(s)
Foreign Key
- Add/Remove Column Reference(s)
- Unique Key Reference
Procedure/Function
== CHILDREN ==
- Add Parameter(s)
- Remove Parameter(s)
- Move Parameter(s)
- Add/Remove/Edit Result Set
- Add/Remove/Edit Column(s)
- Set Column datatype
Security/Governance
Visibility
- Currently Visibility is defined at the Model level in a VDB
- Should we provide Visibility to be defined at each level?
- Schema, Table/View/Procedure, Column/Parameter etc...
Data Roles
- Currently Data Roles and data access restructions are performed within a given VDB.
- These roles and restrictions are not transportable
- Would be nice to allow creating multiple/reusable Data Roles for Models or sets of models?
- Involves Create, Read, Update, Delete, Execute, Alter booleans for Tables, Views, Columns, Parameters, etc....
Translator Overrides
- Currently Translator overrides are performed within a given VDB
- These overrides are not transportable
- Would be nice to allow creating multiple/reusable
VDB
- Add/Remove Model
- Connection Info (JNDI Name, Translator, etc...)
- Set Property (Query Timeout, Description, etc....)
- Add/Remove Table, View, Procedure, Function
- Add/Remove VDB Import reference
VDB User Files
- Currently added to VDB zip file
- Investigate how/where these should/could be deployed into a server location to be accessed by user
Access Pattern
- access pattern columns must be in the same table as the access pattern
Datatype rules
- Character datatype length == 1
- String length > 0
- if NUMERIC type, precision > 0
column datatype rules
- type can't be null or empty
- type must match one of the teiid-supported types
FK
- #columns referenced has to equal #columns referenced on the Unique Key/PK
- All datatypes must match for each column
- (NOTE COLUMNS MUST BE ORDERED)
UC/PK
1) Warning if a proimary key references a nullable column
2) Error if unique key references columns from differrent tables.
Source model TABLES
1) warning if Name In Source == NULL or empty
FUNCTION
- UDF requires java class, java method, function category
- For workspace the jar path is required to auto-deploy the jar or add it to a VDB along with the model
- UDF requires a RETURN parameter
PROCEDURES
// get the procedure parameters, check the direction on the
// parameter
// 1) Warn if the parameter direction is not set.
// 2) Warn if the parameter direction is 'UNKNOWN".
// 3) Error if more than one paramter is of 'RETURN' direction.
// Need to validate for Pushdown Functions if "FUNCTION = TRUE" property set
// 1) Can have multiple input parameters
// 2) Requires "Output Parameter" and CANNOT have multiple
NAMING
- Siblings cannot have the same name
TABLE
- If TABLE is updatable, then at least 1 column must also be updatable
- if table is MATERIALIZED (TRUE), then materialized TABLE reference cannot be NULL
- MATERIALIZED TABLE cannot have columns with datatypea: CLOB, BLOB or Object
- Unique Constraints/Keys cannot reference the same columns
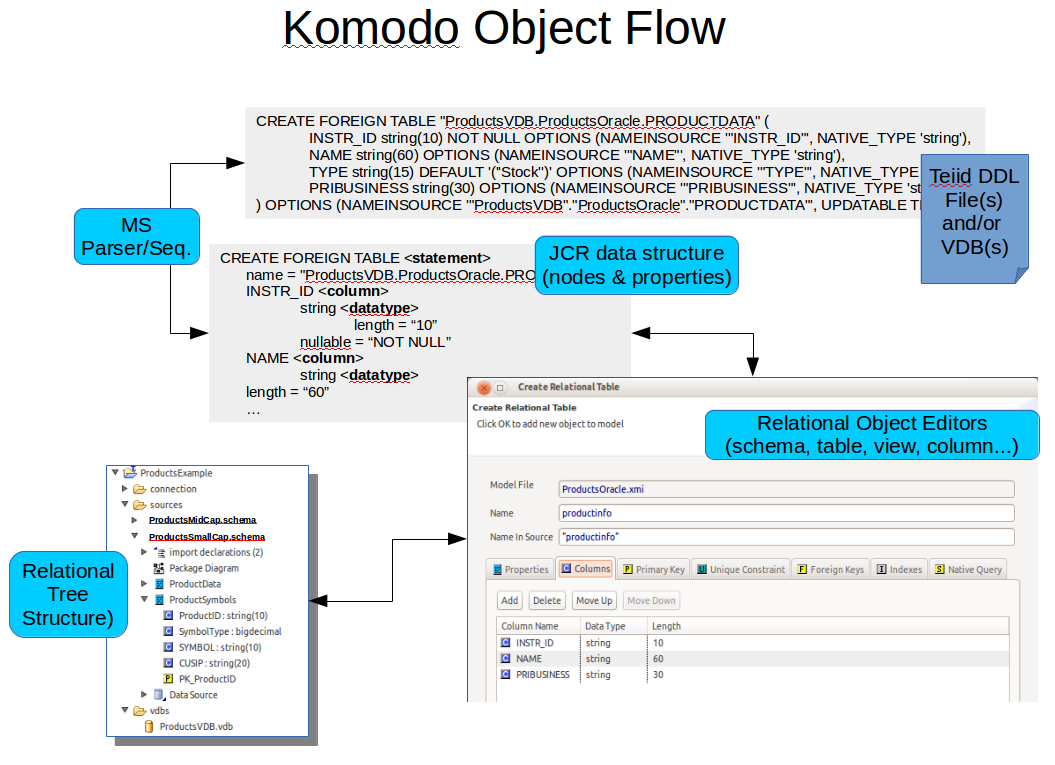
The following figure illustrates the relational/DDL object flow from DDL-based definition through Modeshape/JCR node/properties to UI relational schema constructs.
VDB Artifact Definition
Comments