Suppose you have a data store that is not modifiable, or not meeting your needs in terms of query performance, and you know that if you can index few more fields of the data structure you can improve the performance, then read on. In this article, I show an example, as how you can use Apache SOLR as index store in conjunction with MariaDB.
Objective:
This article purpose is to use Apache SOLR as index store, that fronts for any other relational or key based stores. For example, you have vast amounts of data in RDBMS or any other key based stores like JDG, Apache, MongoDb etc, and you need to index the data on fields other than PRIMARY KEY or KEY fields (if it is on directly on primary key, then source system will be able get it much faster) and get faster query response times that can avoid table scan kind of queries in the source system. This technique is not useful for sources like CSV or XML files as the data is not stored by key in source to begin with, so there is no good way currently to speed those up, but would work excellent with JDG, MongoDB, Accumulo etc.
Setup:
For this usecase I am going to use MariaDB as one source (this can be replaced with your choice of data source, I choose this for expediency of article) and my index store going to be Apache SOLR. The sample database I am going to use in MariaDB is sample Empoyees database, which can be download from https://dev.mysql.com/doc/employee/en/employees-installation.html download file called https://launchpad.net/test-db/employees-db-1/1.0.6/+download/employees_db-full-1.0.6.tar.bz2 then follow the instructions to install the database.
Now that database is installed, make sure you can access it and study to figure out which fields that you want to index into Apache SOLR for tables of interest. In this case based on the schema defined for Employees database https://dev.mysql.com/doc/employee/en/sakila-structure.html. Typically you ONLY want to store index information on VIEW that is created in the Teiid, even there you want to create index on a column that is computed form (which takes time to evaluate in real time) in Apache SOLR. There are no restrictions as to you can not create indexes in Apache SOLR based on the source table's columns, you can but that may be served best by the source system. That is your choice as to what you want to index, in this example I am going to show a view column to index. Before we set up Apache SOLR, let's build a VDB with views we want. Ignore that you need indexing for a moment.
Building a VDB
Here is a Dynamic VDB, that exposes the "Employees" database and creates a Simple View called "HighlyPaidEmployees"
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<vdb name="solrindexing" version="1">
<model name="employees">
<source name="mariadb" translator-name="mysql" connection-jndi-name="java:/employeesDS"/>
</model>
<model name = "view" visible = "true" type = "VIRTUAL" >
<metadata type = "DDL"><![CDATA[
CREATE VIEW HighlyPaidEmployees (
id long,
name varchar,
department varchar,
title varchar,
salary long
) AS
SELECT e.emp_no as id, concat(e.last_name, concat(',' , first_name)) as name, d.dept_name as department, t.title title, s.salary as salary
FROM employees.employees e
JOIN employees.salaries s on e.emp_no = s.emp_no
JOIN employees.dept_emp de ON e.emp_no = de.emp_no
JOIN employees.departments d ON de.dept_no = d.dept_no
JOIN employees.titles t ON e.emp_no = t.emp_no
WHERE s.salary > 100000;
]]>
</metadata>
</model>
</vdb>
In this example, I would like to index the column "name" into Apache SOLR. Once I index this column, I need to tie this "name" back to employees, so I would also need "id" aka "emp_no". Based on this information now, I can create a index fields in Apache SOLR as below section.
Setup Apache SOLR
Using Step 1 of this article as base, install Apache SOLR Integrate Apache Solr with Teiid, however the indexed fields going to be ones from below.
Delete all fields except _version_ and _root_ and add below ones.
<field name="id" type="long" indexed="true" stored="true" required="true" multiValued="false" /> <field name="name" type="string" indexed="true" stored="true"/>
- Once the Solr is started, using a web browser go to address "http://localhost:8983/solr"
- On Left hand side navigation go to "Core Admin", if you see "unload" button click it
- Now click "Add Core", and "teiidindex" as core name and "teiidindex" as directory name as shown below.
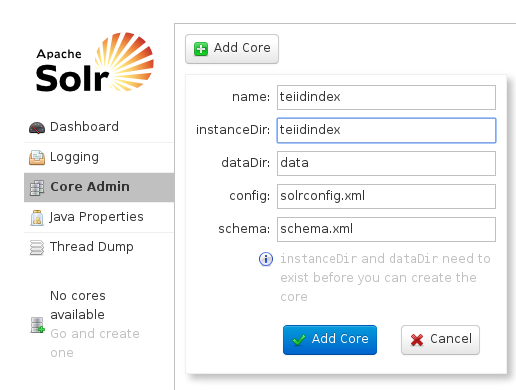
Make sure there were no errors during these steps. That finishes the configuration of SOLR.
Now we need to create data sources for MariaDB and SOLR in JBoss EAP, so that Teiid VDB can make use of them.
Edit "standalone-teiid.xml", under "resource-adapter" section add the XML for creation of data sources.
Create Data Source for SOLR
<resource-adapter id="solr-ds"> <module slot="main" id="org.jboss.teiid.resource-adapter.solr"/> <transaction-support>NoTransaction</transaction-support> <connection-definitions> <connection-definition class-name="org.teiid.resource.adapter.solr.SolrManagedConnectionFactory" jndi-name="java:/solr-ds" enabled="true" pool-name="solr-ds"> <config-property name="CoreName">teiidindex</config-property> <config-property name="url">http://localhost:8983/solr/teiidindex</config-property> </connection-definition> </connection-definitions> </resource-adapter>
If you configured Apache SOLR on a different machine, make sure above configuration reflects that, and have access to the URL.
Data Source for MariaDB
Install JDBC driver of MariaDB, See Data Source Configuration in AS 7 if you not sure how to deploy a JDBC jar file for MariaDB.
<datasource jndi-name="java:/employeesDS" pool-name="employees-ds" enabled="true">
<connection-url>jdbc:mysql://{host}:3306/employees</connection-url>
<driver>mysql-connector-java-5.1.5.jar</driver>
<security>
<user-name>{user-name}</user-name>
<password>{password}</password>
</security>
</datasource>
save standalone-teiid.xml file, and start the JBoss EAP and make sure there are no errors. Now lets rewrite the VDB to make use of the Apache SOLR index store.
Modified VDB to use Index Store
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<vdb name="solrintegration" version="1">
<model name="solr">
<source name="solr" translator-name="solr" connection-jndi-name="java:/solr-ds"/>
</model>
<model name="employees">
<source name="mariadb" translator-name="mysql" connection-jndi-name="java:/employeesDS"/>
</model>
<model name = "view" visible = "true" type = "VIRTUAL" >
<metadata type = "DDL"><![CDATA[
CREATE VIEW HighlyPaidEmployees (
id long,
name varchar,
department varchar,
title varchar,
salary long
) AS
SELECT e.emp_no as id, concat(e.last_name, concat(',' , first_name)) as name,
d.dept_name as department, t.title title, s.salary as salary
FROM employees.employees e
JOIN employees.salaries s on e.emp_no = s.emp_no
JOIN employees.dept_emp de ON e.emp_no = de.emp_no
JOIN employees.departments d ON de.dept_no = d.dept_no
JOIN employees.titles t ON e.emp_no = t.emp_no
WHERE s.salary > 100000;
CREATE VIEW IndexedHighlyPaidEmployees (
id long,
name varchar,
department varchar,
title varchar,
salary long
) AS
SELECT e.id, i.name, e.department, e.title, e.salary FROM HighlyPaidEmployees e JOIN /*+ MAKEIND OPTIONAL */ solr.teiidindex i ON i.id = e.id;
]]>
</metadata>
</model>
</vdb>
Now deploy the VDB into Teiid server, and using JDBC client program populate the Apache SOLR index by executing the following query
insert into solr.teiidindex (id, name) select id, name from view.HighlyPaidEmployees;
Index is populated and now you can issue queries that can use Index information as filter, for example
select * from view.HighlyPaidEmployees where name = 'Muntz,Bernice'
Does not use Index, where as below does use index in Apache SOLR
select * from view.IndexedHighlyPaidEmployees where name = 'Muntz,Bernice'
Did you see this query executed much faster than original? if yes, job well done, if not trace your steps back, there are some hints in Gotchas section at the bottom of the article.
Note that the optimization only makes sense when filter on "name" column is being used, if "name" column is being omitted then JOIN condition will perform purely as before. The big issue I see is, how can one keep up with the indexes to keep them fresh
Feeling more Adventurous? Want to push this little further? Read on
We should be able to improve upon the above design to keep up with the updates. What other feature needs constant updates?
I could think of two ways one can achieve this.
1) View needs to be updatable. i.e. provide insert/update/delete INSTEAD OF TRIGGERS for these and also update the SOLR index table in the context to keep it up to date. This assumes that all the updates are going through Teiid for the sources involved. If the sources are being updated independent of Teiid, this option does not work. So, I am going to leave this as exercise you can do
2) If you guessed materialization as second option, Right!!! it is materialization. We can make Apache SOLR as external materialization target. Then updating of the index can be scheduled periodically. I give a pretty damn good example here External Materialization You can follow that and create external materialization. Let me see if I can rewrite above example VDB using external materialization below.
First per article External Materialization I created the "status" table in "employees" database in MariaDB. Then I deployed following VDB into Teiid
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<vdb name="solrintegration" version="1">
<model name="solr">
<source name="solr" translator-name="solr" connection-jndi-name="java:/solr-ds"/>
</model>
<model name="employees">
<source name="mariadb" translator-name="mysql" connection-jndi-name="java:/employeesDS"/>
</model>
<model name = "view" visible = "true" type = "VIRTUAL" >
<metadata type = "DDL"><![CDATA[
CREATE VIEW IndexedHighlyPaidEmployees (
id long,
name varchar,
department varchar,
title varchar,
salary long
) AS
SELECT e.emp_no as id, ei.name as name,
d.dept_name as department, t.title title, s.salary as salary
FROM employees.employees e
JOIN employees.salaries s on e.emp_no = s.emp_no
JOIN employees.dept_emp de ON e.emp_no = de.emp_no
JOIN employees.departments d ON de.dept_no = d.dept_no
JOIN employees.titles t ON e.emp_no = t.emp_no
JOIN /*+ MAKEIND OPTIONAL */ EmployeeIndex ei ON ei.id = e.emp_no
WHERE s.salary > 100000;
CREATE VIEW EmployeeIndex (
id long,
name varchar
) OPTIONS (
MATERIALIZED 'TRUE',
UPDATABLE 'TRUE',
MATERIALIZED_TABLE 'solr.teiidindex',
"teiid_rel:MATERIALIZED_STAGE_TABLE" 'solr.teiidindex',
"teiid_rel:ALLOW_MATVIEW_MANAGEMENT" 'true',
"teiid_rel:MATVIEW_STATUS_TABLE" 'employees.status',
"teiid_rel:MATVIEW_BEFORE_LOAD_SCRIPT" 'delete from solr.teiidindex;',
"teiid_rel:MATVIEW_SHARE_SCOPE" 'SCHEMA',
"teiid_rel:MATVIEW_ONERROR_ACTION" 'THROW_EXCEPTION',
"teiid_rel:ON_VDB_DROP_SCRIPT" 'DELETE FROM employees.status WHERE Name=''EmployeeIndex'' AND schemaname = ''view''',
"teiid_rel:MATVIEW_TTL" 1800000
)AS
SELECT emp_no as id, concat(e.last_name, concat(',' , first_name)) as name FROM employees.employees e;
]]>
</metadata>
</model>
</vdb>
The approach I took here is, I created a separate view that contains all the required indexes, then I enabled external materialization. In Teiid 8.5, we have introduced management with External Materialization, I used those extension properties on the view as to how the materialization needs to be managed. Now once the VDB is deployed the index store is automatically loaded (it took me couple tries to get the status table and scripts right) and based on the MATVIEW_TTL defined they will be automatically refreshed. Now I can issue same query as before
With Not using index store
select * from view.IndexedHighlyPaidEmployees where name = 'Muntz,Bernice' OPTION NOCACHE
With using index store
select * from view.IndexedHighlyPaidEmployees where name = 'Muntz,Bernice'
Gotchas!!!
There are plenty. Let me see I can list them
- I fixed couple issues with SOLR translator. TEIID-3065, TEIID-3062 you need a version that has this fix.
- When creating index store in SOLR, try to create store (core in SOLR) for each view separately. Having one store to keep all the view indexes in your project will not work well, as it recommended to have a unique id with each store. Keep the unique name as "id" in SOLR, as SOLR translator does name match to create a primary key.
- Note that there can be one table in Teiid for each core in SOLR. You when you do create multiple cores, means you need multiple models, and multiple connection profiles. We need to investigate if there is a better way but this is what Teiid has right now.
- I had tough time using planner hints. I had lot of help from SteveH (many thanks!!!), still at the end the only one worked for me is MAKEIND. There are others like MAKEDEP but when they applied on View, and during the execution when view is flattened it looses the scope. So, my strong suggestion is use these hints as close to source table as possible. See in my usecase I used on "solr.teiidindex" which represents source table. But MAKEIND or MAKEDEP hints both should work.
- SteveH suggested to try NO_UNNEST in conjunction with MAKEDEP on view like . I tried my transformation like and that works
SELECT e.id, i.name, e.department, e.title, e.salary FROM /*+ NO_UNNEST MAKEDEP*/ HighlyPaidEmployees e JOIN /*+ OPTIONAL */ solr.teiidindex i ON i.id = e.id;
- BTW, the OPTIONAL hint is when you are not projecting the indexed column or not using in the filter criteria, then that side of the JOIN is useless, so OPTIONAL hint will ignore calling that branch.
- One useful tip is, when testing to see if the query using the index store or not, execute "SET SHOWPLAN DEBUG", then execute your query. In the generated plan that being executed, you should see a "Dependent Access Node" with one column saying ..IN (<dependent values>), that tells us that HINTS placed are in play.
That it my friends, I know I used simple stupid example, but my aim was to show you how these technologies can be put together now it is your job make it work for your complicated usecases. If you write one come back and share and write blog!
Thanks.
Ramesh..
Comments