Yesterday I blogged about RHQ-Alerts aka Alerts 2.0 (and who got the Wintermute in the subject?), we have RHQ-Metrics and Mazz wrote about RHQ-Audit and messaging. So let me show you a bigger picture that I have in mind and open it up for discussion.
But before I do this, let me first explain some motivation:
- RHQ has some pretty good pieces that we want to open up for more general consumption by other projects. The current incarnation of RHQ itself is pretty monolithic and does not easily allow for separation.
- Functionality is very synchronous - this is often not that visible because the GWT-UI has all those async callbacks. This synchronicity often makes clients wait on e.g database work and thus consuming resources that can otherwise be used differently (An agent delivering metrics only needs to know that the server has received the data and will process it. It has no advantages from waiting until they are finally stored).
- With all those new components all bringing new apis (REST, Java), how do we wire them together? And how can we make sure that data that is e.g. fed into RHQ-Metrics will also be available for alerting?
- How can we (especially for testing purposes) reduce the system complexity and

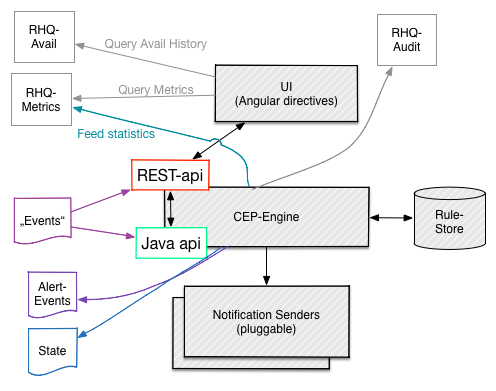
The approach that I am depicting here loosely adheres to the reactive manifesto. It has a central message bus as the backbone and then a set of (remote) APIs feeding into this bus. In above illustration, the dashed box depicts the "server" as opposed to more external things like UI, agents or 3rd-party apps talking to the server.
On the bus we can have several queues and topics for various tasks. The individual components would connect to the bus "via their Java api" (*) to receive messages for processing but also to submit messages on their own for further processing.
- Incoming metrics need to be processed by rhq-metrics for storage and rhq-alerts for alerting
- RHQ-metrics could compute aggregates at regular points in time and for one store them and also put them on the bus for further consumption by rhq-alerts
- Audit messages would be stored away by RHQ-Audit
- Alerts could be pushed via Websockets or Errai directly into the UI without the need for polling
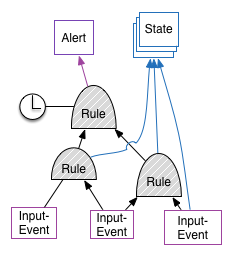
- As written in the RHQ-Alerts post, the CEP engine could create computed availability which is then put on the bus for further processing by a possible RHQ-Availability component
Also for scalability a messaging bus allows to e.g. have multiple consumers on a Queue that then process messages in turn. Those consumers can then live on different hosts and thus spreading the load. With multiple consumers on different hosts (and a HA message broker) a certain resilience can be achieved, as if one consumer fails, the other consumers can take over (at reduced speed). This implies that there will be no need to run all the components (rhq-metrics, ... ) in the same VM, but they still can do so in smaller setups.
Using a message bus also allows like REST-apis to also use other languages than Java for clients, which is good for further adoption and integration.
I briefly mentioned the UI already. For the normal display things each component will provide AngularJS widgets that will need to be combined. Those widgets can still talk to their respective Rest-Endpoints.
As you can see this is so far only a very rough design - the box labelled "inventory" is not connected to any of those other boxes and we certainly need to think hard how to connect it and how a future inventory should look like ( for example we need relations between resources that go beyond parent-child, also we should probably introduce the notion of "Application" as a set of such related resources; this would also play into alerting and SLAs).
*) What is meant here is that there will be tiny adapters from the bus to the respective java-api of the component in order to make the java api the "standard". I've written about this a few days ago in the light of rhq-metrics.