Design change?
Hello,
RHQ-metrics works quite nicely so far and the REST-interface has become powerful with e.g. the Influx handler and all the capabilities to retrieve data points and series in batches and so on. Unfortunately this has caused a bit of a mismatch between REST-api and Java api (and yes I am guilty here). The following picture shows the situation:

The Java and the REST api exist next to each other.
While this is probably no real big issue in standalone situations where the REST api is the genuine go-to point, it becomes an issue where RHQ-metrics should be embedded in a larger scenario like e.g. the next RHQ version where RHQ-metrics is possibly co-located with other services and direct Java communication is much faster then first marshalling objects into JSON to go over a REST-interface to be unmarshalled again.
Also right now, all functionality is pretty much hard-coded and it is not possible to extend the functionality of the core (e.g. different data mangling) in a user serviceable way.
InfluxDB has a sql-like query language that allows to say something like "select min(x) .. group by 30s" to only return the minimum value of all values that were stored within a 30s bucket. As such a language is dynamically parsed on the server, adding more aggregate functions in a pluggable way could be possible by having plugin-methods implementing functions like "matches(name)" and "compute(param, timeseries)" (this is only for explanation and no real interface).
The other point is that in a scenario like RHQ, where a client would push metrics to RHQ-metrics via Java or REST-interface, the data would also need to be forwarded to other subsystems like alerting (in fact even in RHQ-metrics it could make sense to directly push those new data points or aggregates thereof to the UI via Errai or Websocket, so that the UI updates dynamically instead of having it to poll constantly).
With those comments in mind I would propose to change the architecture to follow more this picture:
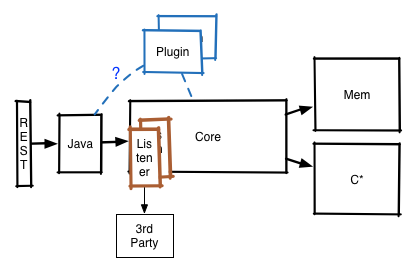
Here the REST-api is really only a very thin layer, translating the internal domain objects into their external representations and having the JAVA-api define the real API, that is then available in Java and REST.
All incoming data would be passed to listeners if present that can then do additional forwarding to 3rd party systems (I guess such listeners should also be pluggable).
The aggregation / computation plugins would probably work on the Java-Api level, working on data that has already been retrieved from the core.
In the longer term we may want to have additional plugins that e.g. do hourly / nightly batch processing as pre-computing time series that take too long to do it on the fly.