Use case for Modeshape
Hi there,
i have been reading about modeshape and checking the documentation and, at least about functionality, it seems to be what i am looking for. Nevertheless, since i read some use case assessment in this forum i find interesting presenting mine to finally make my opinion about what would take to build the system i need.
Let's take it in parts. About data structures, file sizes and user volumes i present the following requisites:
- store files that will range from 1 KByte to 30 MBytes.
- store metadata for each file, about 10 properties each file
- very high users volume ranging from 10K - 1M users
- some workspaces (not a clear idea yet, but at least to of them)
- automatic metadata extraction
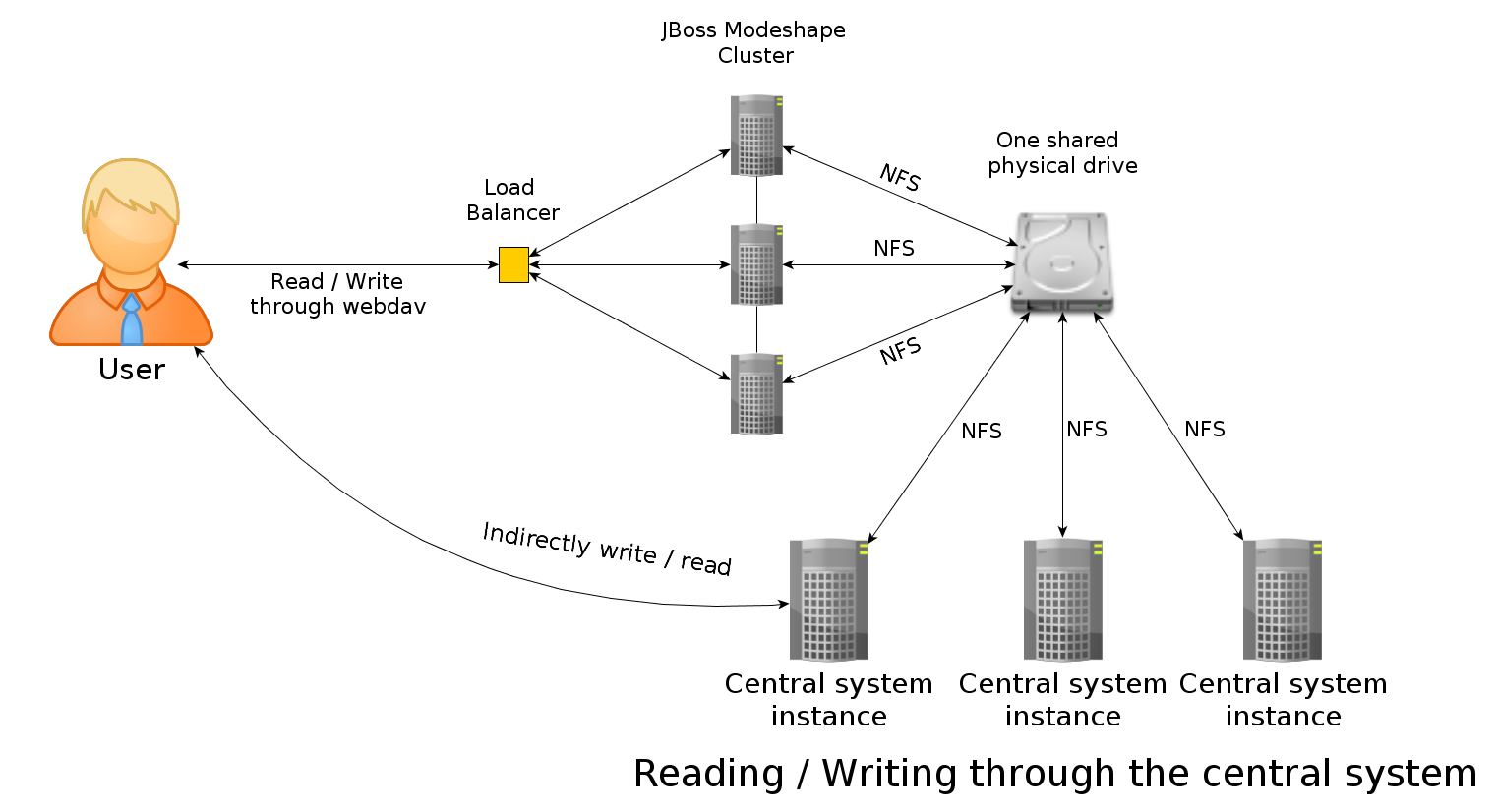
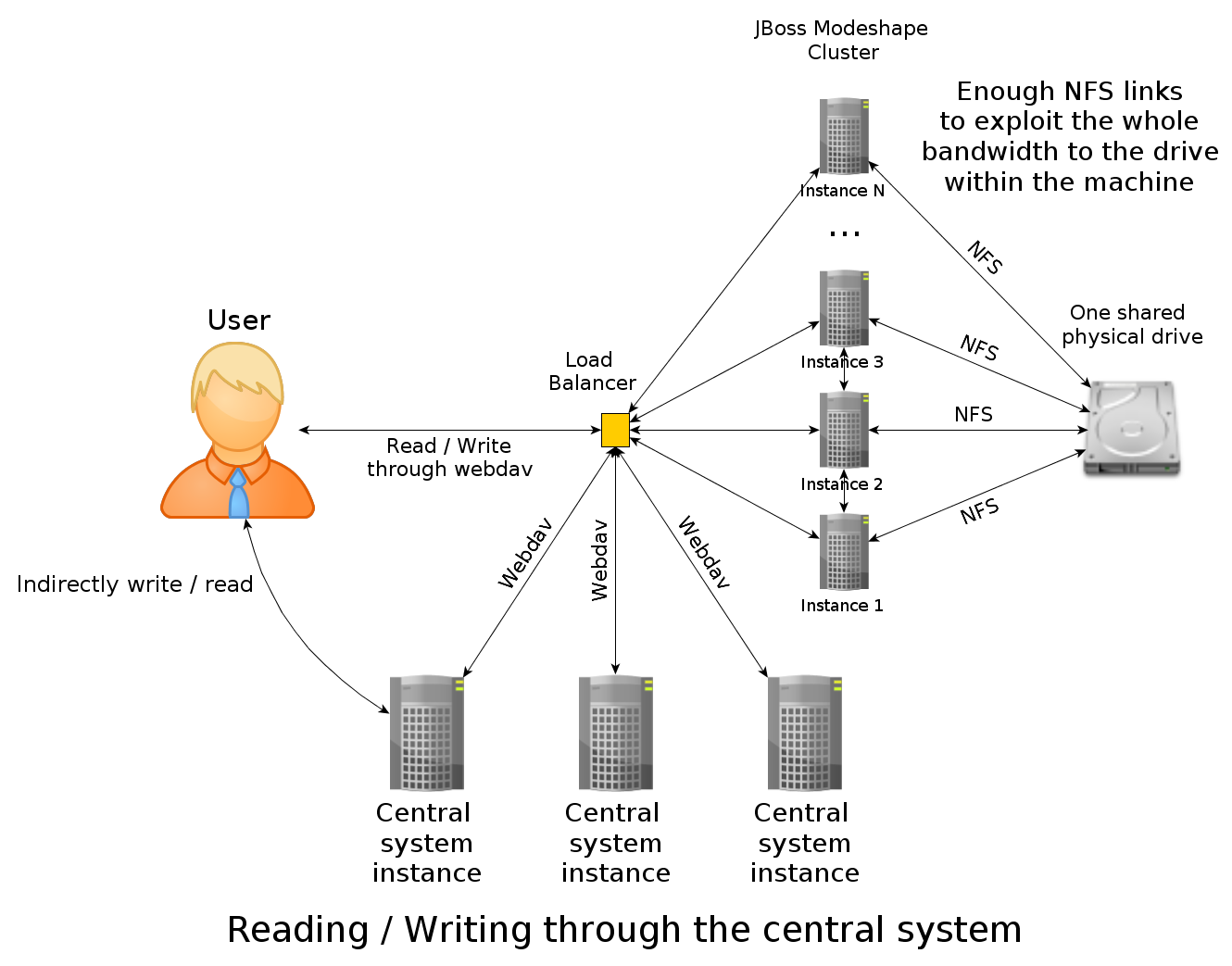
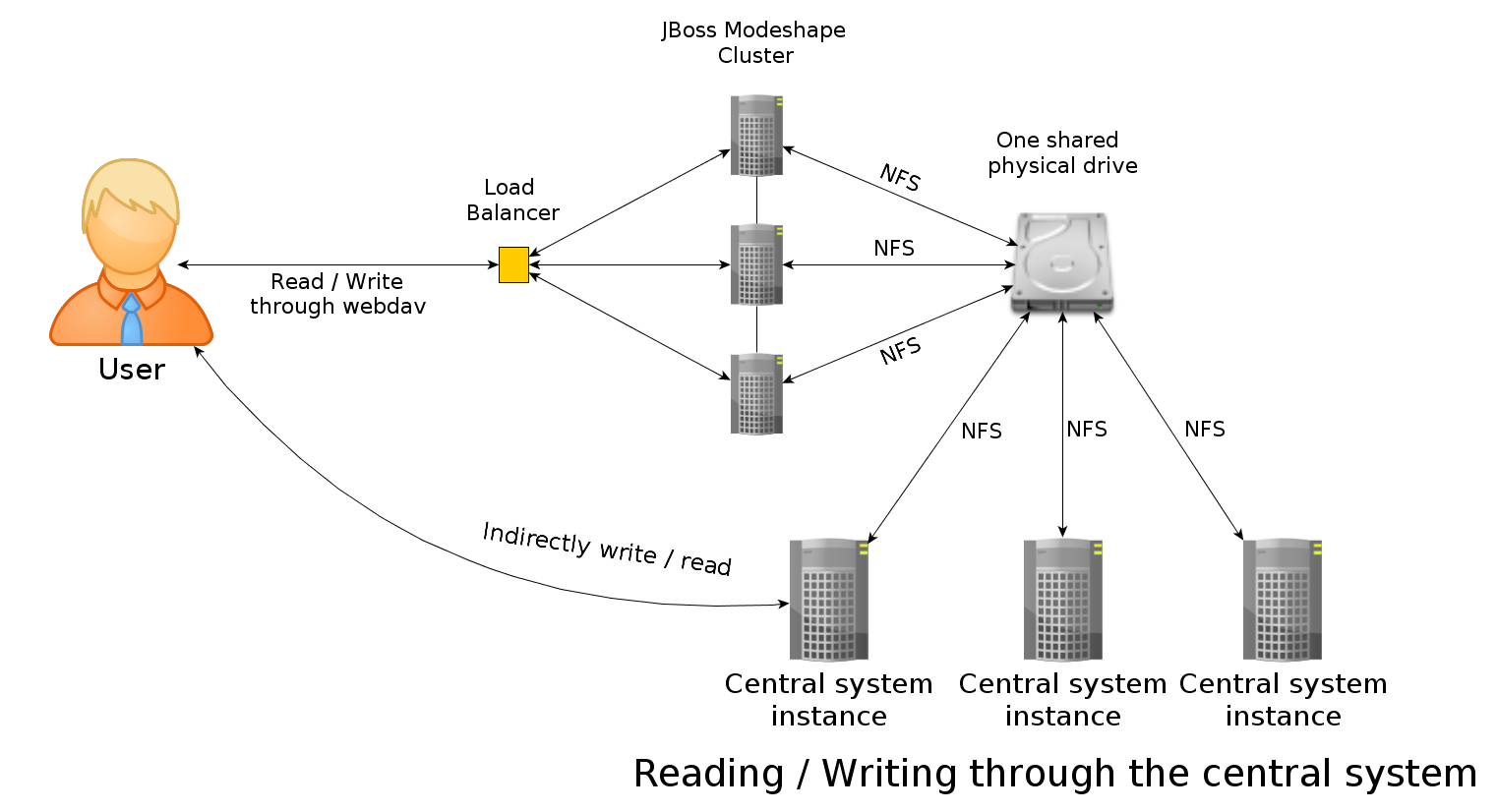
About the architecture, i would like to achieve a physically distributed repository working as follows:
- clusterized modeshape working on JBoss AS server instances, preferrably providing fault tolerance and sticky sessions
- a load balancer for the users to HTTP GET their files (maybe put them through Webdav too, but i found some issues working with Nginx when writing, don't know if any other load balancer works well with webdav methods used by modeshape)
- a central system that will read / write the same files described above (locking will be useful), through the same load balancer using Webdav
- a shared disk drive accessed through NFS for the file repository (the main idea is to provide enough network interfaces to the machine containing the drive to exploit the entire bandwitdh of the drive in the internal bus of the machine)
- a shared database for the metadata repository
About security:
- both authentication and authorization for the volume of users i described (for example ACL managing is not implemented through Webdav in other JCR 2.0 implementations such as Jackrabbit)
Further questions:
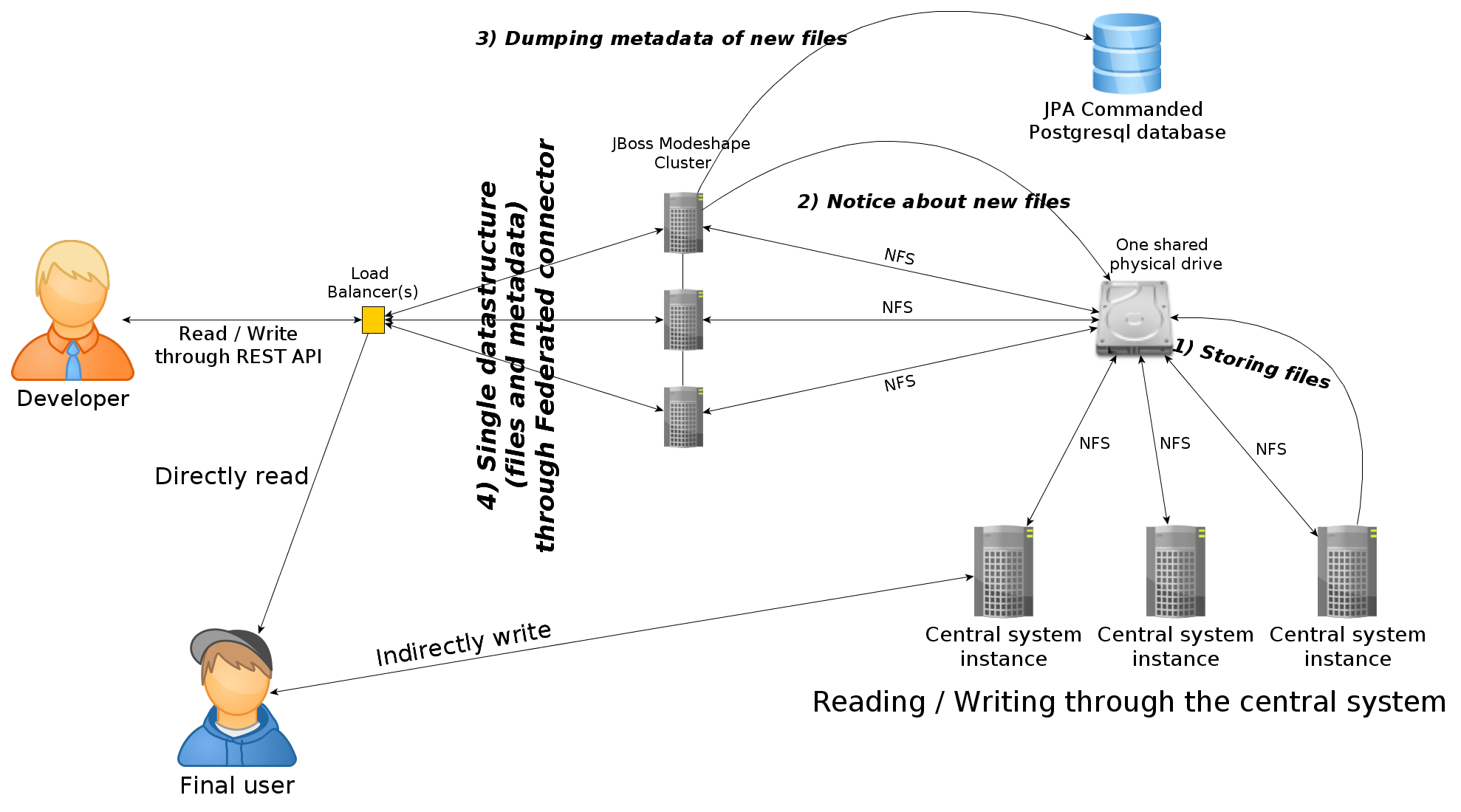
- i find pretty interesting for my scenario not copying a file twice (SHA-1 hash based), to save bandwidth in some determined situations, how does it work? the webdav client should calculate the hash, query the repository to know if it is already present and, in case it is, do not transfer the file and just create another "link" for the existing one? would correctly work with the federated connector joining the database and file system connectors?
- garbage collection, is a file actually deleted from disk when it is deleted from the repository (no references to it) by running a garbage collector?
- could the write / read methods performed by the central system be done directly to the shared drive and then Modeshape take care of completing the metadata work alone? synchronization issues?
- so far, i have read about the database connector (appropriate for the metadata i guess), the filesystem connector (appropriate for files i guess) and the federated connector (to join the two prior connectors and offer a single repository interface to the logic layer on top of Modeshape, the "magic" that achieves the transparency for the developers is right here, isn't it? synchronization issues here?)
- monitoring facilities throgh the JBoss console, that i find pretty interesting as well, would work fine in the described clustered scenario too?
First of all, if you reached this point within the post, thank you very much!!!
Please find attached some images to support the explanations i wrote above.
Thanks in advance for your responses, every contribution is explicitly welcome!!!
-
ModeshapeDirectFSNFS.png 111.8 KB
-
ModeshapeFSNFS.png 126.1 KB
{kind=link}