
This content has been marked as final.
Show 3 replies
-
1. Re: Distribute consumers between hornetq nodes in a symmetric cluster with discovery
evidence01 Jan 30, 2014 2:42 PM (in response to lifeonatrip)
Yes it is possible via cluster config doing server side JMS load-balancing and/or client side load-balancing.It can be done with Queues or topics. What do you want to know specifically?
-J
-
2. Re: Distribute consumers between hornetq nodes in a symmetric cluster with discovery
lifeonatrip Jan 30, 2014 9:15 PM (in response to evidence01)
Hi Jacek,
I just want a real load based balancing policy.
I tried various configurations but the consumers are always connecting at startup to the 2 servers in a random fashion. This basically means that there is a high chance that the consumers are all connected to one queue server rather than both.
I would like to know if there is a way to load balance these consumers based on the actual queue server load and not randomly. All the hornetq load balancing classes are basically random, I tried to implement my own but I can't read from inside the topology UDP broadcast, I had to modify the client to read the UDP broadcast informations but there is no load related informations that I could use in order to balance my consumers, it's just a bunch of ip addresses.
Whether a semi-random policy for a producer is fine in most cases, a consumer should be able to connect where there is more load. Redistribute the messages across servers should not be necessary in that case.
Is there a way to do it?
If not, as far as you know, Is there a plan to implement this feature ?
Thanks for the answer.
-- lifeonatrip
-
3. Re: Distribute consumers between hornetq nodes in a symmetric cluster with discovery
evidence01 Jan 31, 2014 8:56 PM (in response to lifeonatrip)
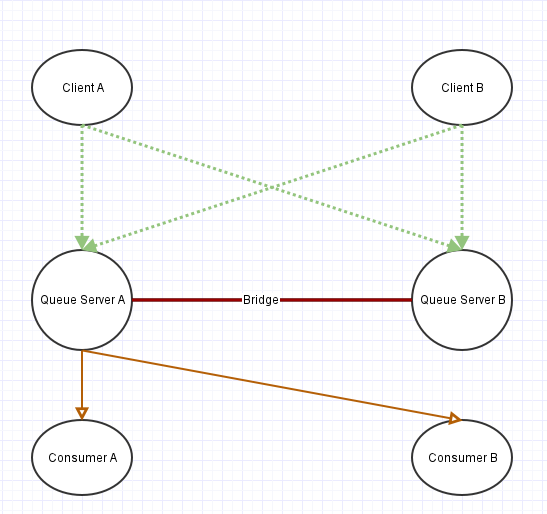
1 of 1 people found this helpfulWhat you seek is outside the messaging layer. The client side LB strategies where designed with publishers in mind. Typically to control consumers like that you would have the consumer not use a discovery group but define a static binding where you have a primary and secondary IP that the client always connects to. More specifically, the LB on the consumer side is a function of the application/consumer design. In you example you would have consumer A have queue server A, B and client B have the opposite.
To complement use JMSXGroupID to sticky "Application" data to one consumer versus another in a symmetric cluster. In that sense you could always ensure that one consumer processes data tagged with that GroupID (while they are available of coarse). For example, if you have an Event/Event Collection with a unique ID, each Event/Collection would go to and stick to a random consumer, in your case N/2 would go to A versus B.
This is the architecture we have in our stack.