This content has been marked as final.
Show 8 replies
-
1. Re: Large messages lost between cluster nodes after failover
clebert.suconic Aug 7, 2014 2:20 PM (in response to shainsky)
It depends if the message was acknowledged or not. you ack the message while receiving the message.. if you did it so you won't receive the message after a crash (as you already acked it)
You can use the print-data to debug this. What version are you using?
-
2. Re: Large messages lost between cluster nodes after failover
shainsky Aug 7, 2014 4:06 PM (in response to clebert.suconic)
Sorry, but what do you mean by "you ack the message"? The consumer doesn't acknowledge it because it didn't start receiveing it yet - message still transferring from Node1-backup to Node2-live.
My version is 2.4.1 from GitHub repo.
-
3. Re: Large messages lost between cluster nodes after failover
shainsky Aug 7, 2014 5:07 PM (in response to clebert.suconic)
I will try to explain in other words.
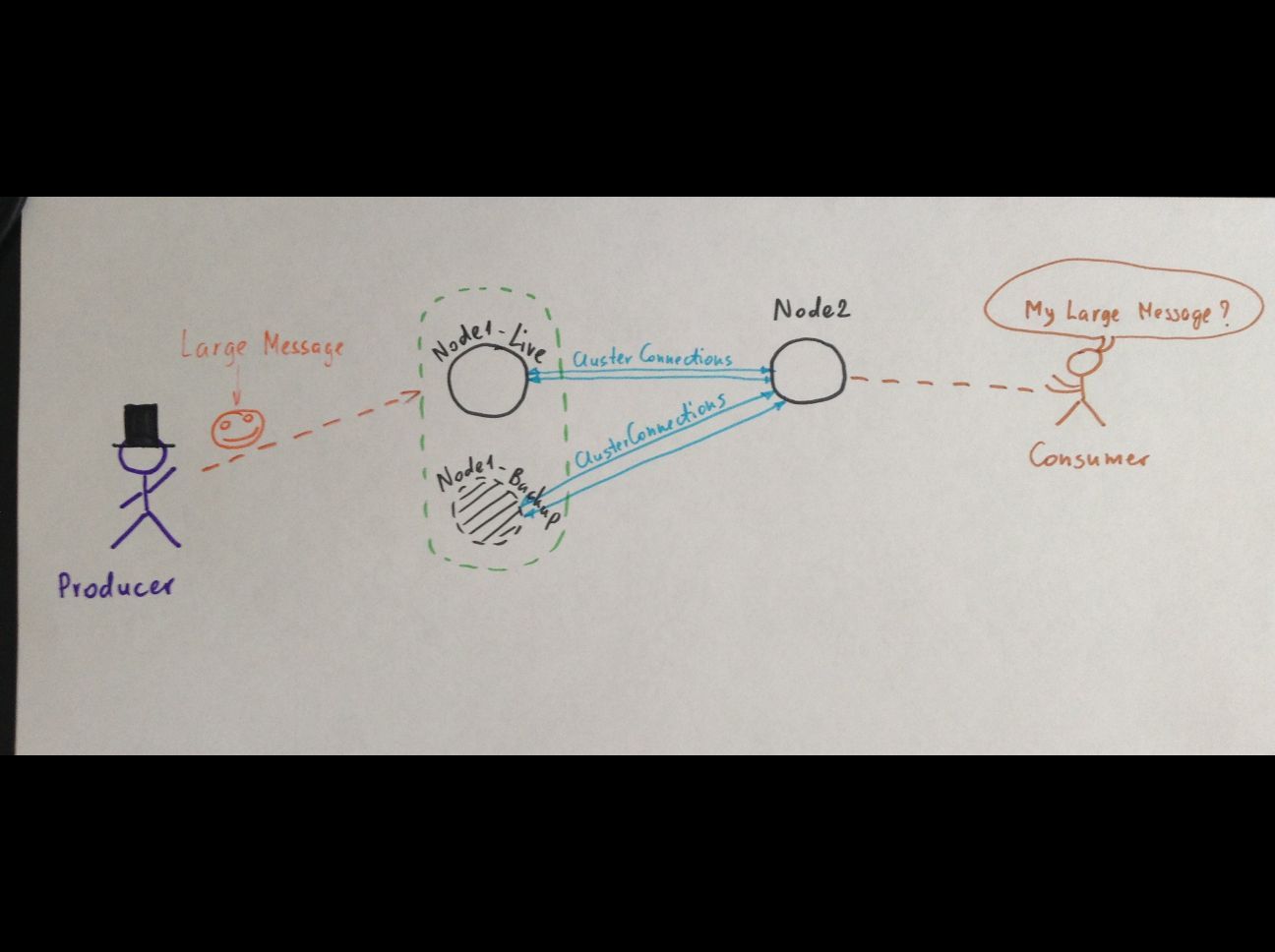
Phase 1. Large message (1Gb) came to Node1-live. Node1-backup contains the replica of this Large_File. Both files are stored in <hornet_dir>/data/large-messages/. The producer receives the ack from Node1.
Phase 2. Node1-live starts transferring the Large_File to Node2. The Large_File still in <hornet_dir>/data/large-messages/*.msg on both Node1-live and Node1-backup nodes.
Phase 3. Node1-live crashes while transferring. Node1-backup becomes active and starts to send the Large_File to Node2 from the beginning.
Phase 4. I restart Node1-live. It discovers that the Node1-backup is active and initiates the synchronization. At this moment the Node1-backup DELETES the Large_File from <hornet_dir>/data/large-messages/ (as well as it deletes the large message from queue, am I right?) and tries to shutdown to allow the failback. But it's JVM still stays alive to let the last netty thread to finish sending the Large_File to Node2.
The problem is: If we kill the Node1-backup at this moment, Node1-live will not re-send the Large_File.
-
4. Re: Large messages lost between cluster nodes after failover
shainsky Aug 12, 2014 4:01 AM (in response to clebert.suconic)
Sorry, but still no ideas how to solve the problem?
-
5. Re: Large messages lost between cluster nodes after failover
clebert.suconic Aug 12, 2014 2:07 PM (in response to shainsky)
You are talking about replica...
But clustering != Replication
Is there a way you could create a testcase based on the examples?
-
6. Re: Large messages lost between cluster nodes after failover
clebert.suconic Aug 12, 2014 2:55 PM (in response to shainsky)
So, I read your message again... this is about failover, not clustering... clustering = message redistribution.
I believe you are failing over while the backup is synchronizing the data with the live.
The backup is not really functional until you have synchronized your data.
And the message will not be available for consumption until your client has finished transmitting it, and committed it in case it was transactional.
I would need some idea on how you are sending it.. when you are killing the live server and what's happening before I can give you better answer. But so far I believe the issue is expected as it doesn't seem that you waited the message or the server to be in sync.
-
7. Re: Re: Large messages lost between cluster nodes after failover
shainsky Aug 19, 2014 10:18 AM (in response to clebert.suconic)
Sorry for the delay. I attached log files from Node1-Live and Node1-backup and put my comments right inside logs.
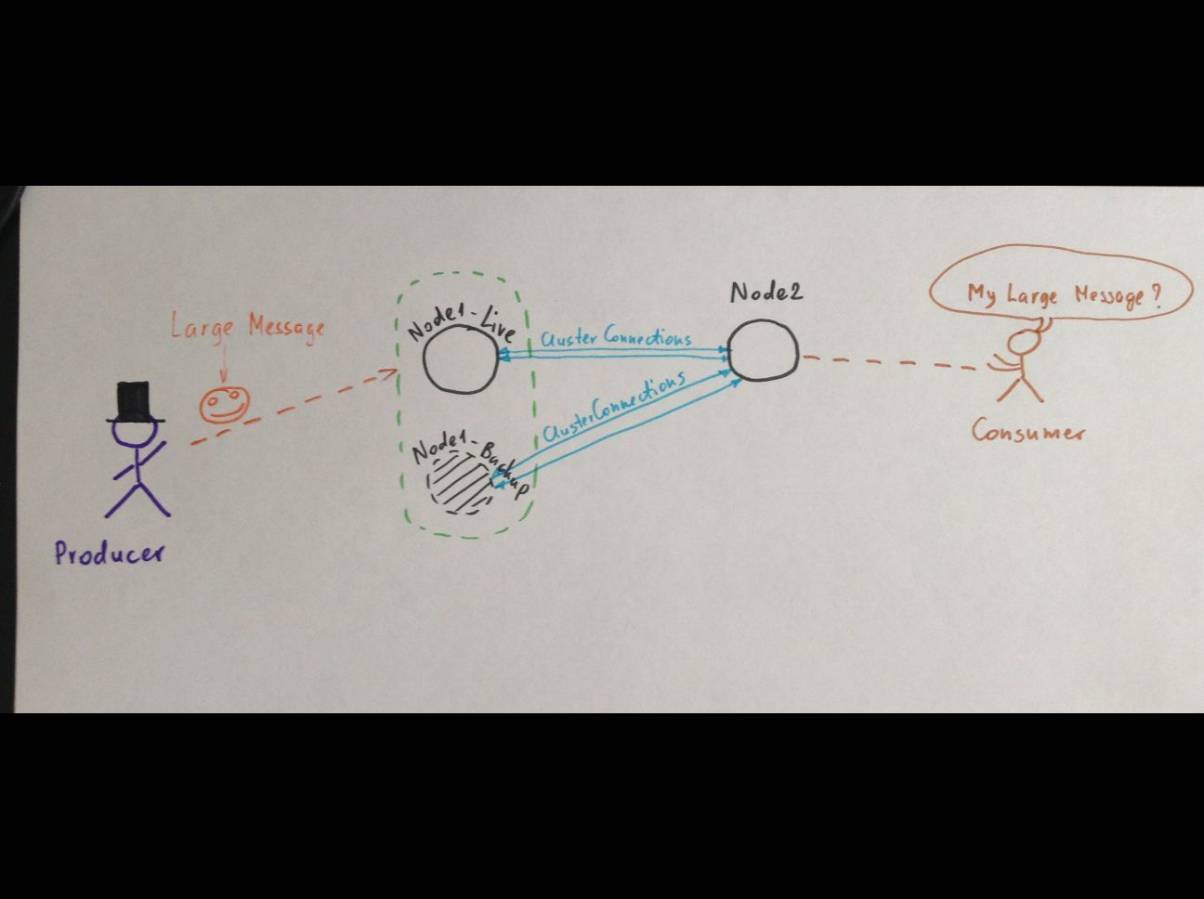
Here is the scenario:
1. Node1-live started 2. Node1-backup started 3. Large message started transferring from producer to Node1-Live 4. Large message received, replicated by Node1-Backup and started transferring to Node2 5. [Ctrl + C] 6. Node1-Backup came live and resumed transferring the large message to Node 2 7. Node1-Live restarted 8. Node1-backup discovered that Node1-live restarted 9. Node1-backup sent synchronization info to Node1-live 10. Node1-Live synchronized with Node1-backup 11. Node1-Live sent 'shutdown' signal to Node1-backup 12. Node1-Live became 'live' again (failed back). Large message transferring didn't resume from Node1-Live. 13. Node1-backup received 'shutdown' signal and coming back to 'backup' mode 14. IMPORTANT! Look at the Thread pool - there's still one thread transferring large message from Node1-backup to Node2. 15. [Ctrl + c]. Node1-Backup stopped transferring large message. Large message is lost!
-
log-node-live.txt.zip 3.0 KB
-
log-node-backup.txt.zip 2.8 KB
-
-
8. Re: Large messages lost between cluster nodes after failover
clebert.suconic Aug 19, 2014 6:52 PM (in response to shainsky)
What you mean by 6 (resumed transferring large message).
We don't have such operation. The client will either complete sending or not. If the message wasn't finished the client should have received an exception for not having the operation complete.
How you're sending the large message? Persistent message I assume.
Why don't you attach your testcase? it would probably be easier to understand it (well.. if the testcase is easy to run).