Memory leak with 5.3.0 Final
We are using an Infinispan Standalone Server version 5.3.0-Final.
The memory setting are:
-Xms2048m -Xmx2048m -XX:MaxPermSize=256m
The client application is using hotrod to communicate with the Infinispan Server.
We are experiencing a slow memory leak. The old gen displays an increasing trend: the lower limit increases after each major collection.
After around 2 months of up-time the old gen reaches the cap and fails to go down after any major collections
(resulting in high CPU, etc. ) and imposing a restart.
This server is hosting around 10 caches, with at most 5000 keys each. The overall size of the information held in this
caches should not exceed several megs.
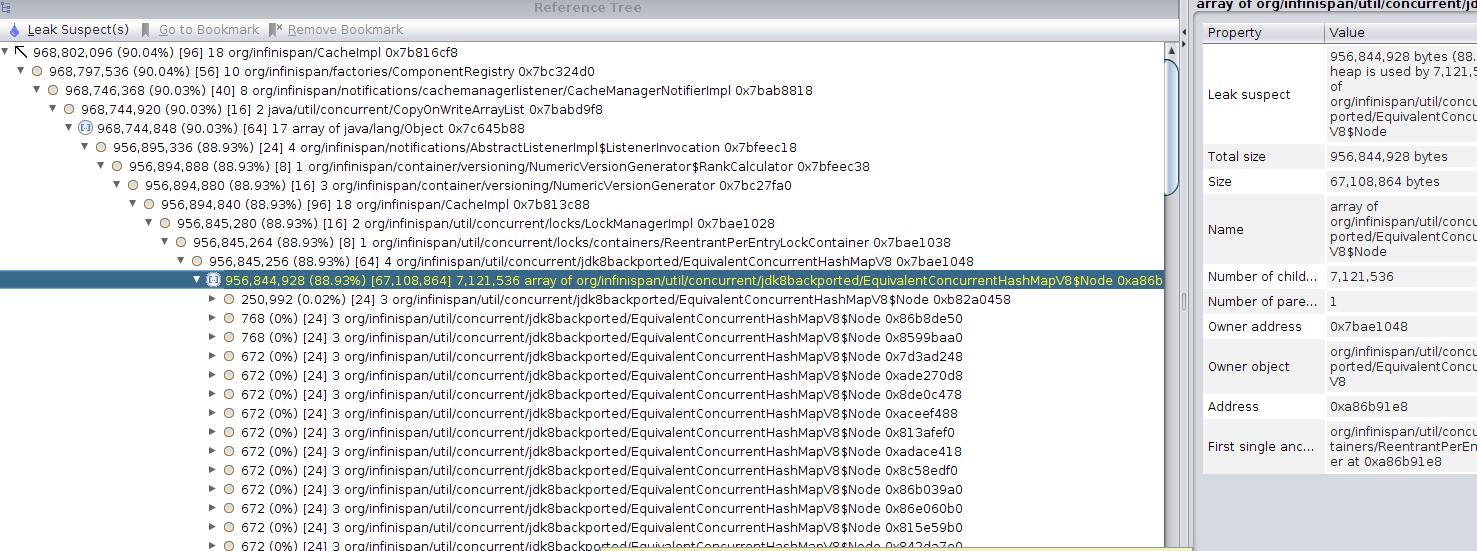
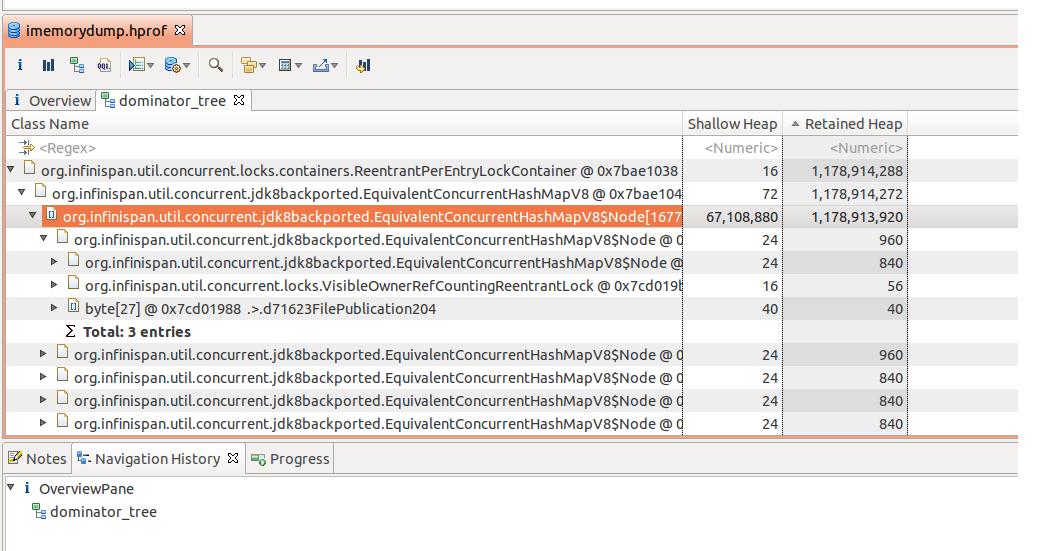
We managed to perform a heap dump when the old gen was 1.2G out of 1.4G and the offender seems to be:
org.infinispan.util.concurrent.locks.containers.ReentrantPerEntryLockContainer
Please check the attached image.
Our caches are defined in one of the following manners:
<local-cache name="Cache1" start="EAGER">
<locking isolation="NONE" acquire-timeout="30000" concurrency-level="1000" striping="false"/>
<eviction strategy="LRU" max-entries="2000"/>
<expiration max-idle="60000"/>
<transaction mode="NONE"/>
</local-cache>
<local-cache name="Cache2" start="EAGER">
<locking isolation="NONE" acquire-timeout="30000" concurrency-level="1000" striping="false"/>
<transaction mode="NONE"/>
</local-cache>
<local-cache name="Cache3" start="EAGER">
<locking isolation="NONE" acquire-timeout="30000" concurrency-level="1000" striping="false"/>
<transaction mode="NONE"/>
<string-keyed-jdbc-store datasource="java:jboss/datasources/JdbcDS" passivation="false" preload="true" purge="false">
<property name="databaseType">ORACLE</property>
<property name="fetchPersistentState">true</property>
<string-keyed-table prefix="IS6">
<id-column name="id" type="VARCHAR2(500)"/>
<data-column name="datum" type="BLOB"/>
<timestamp-column name="version" type="NUMBER(19)"/>
</string-keyed-table>
</string-keyed-jdbc-store>
</local-cache>
Does anyone experienced a similar issue? Is there a know scenario/or misconfiguration on our side that could
lead to this problem?
I would appreciate any advice/hints.