Infinispan blocking state during iteration through cache
Hi all
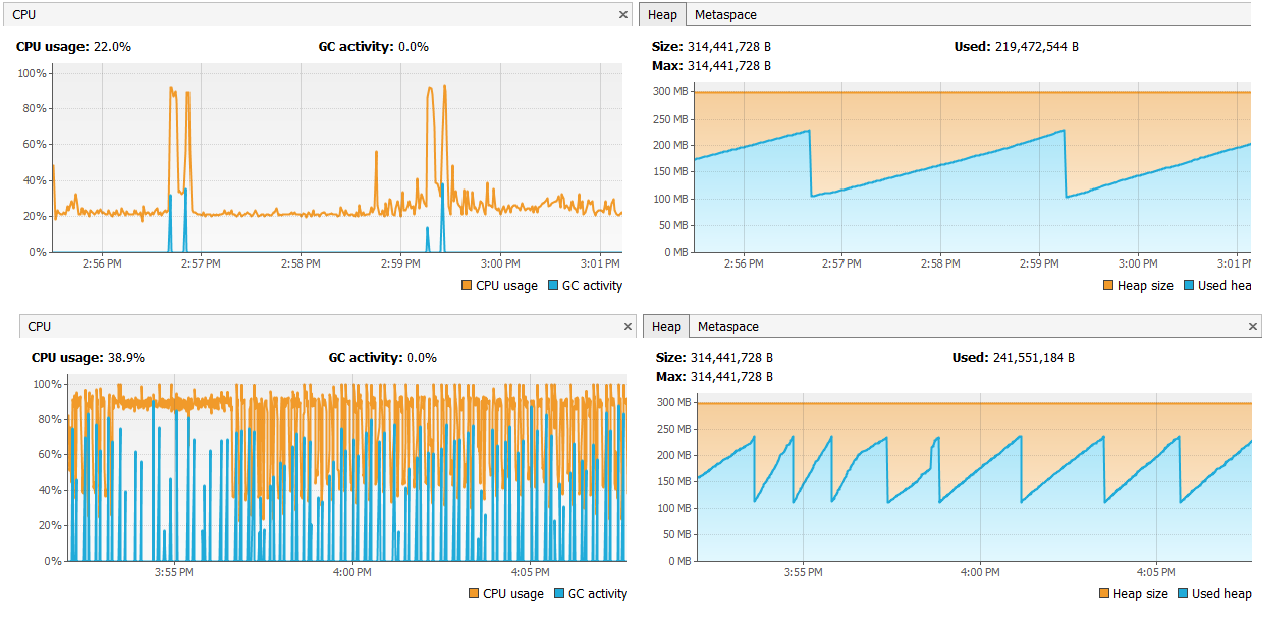
We have spotted in our environment following blocking state in Infinispan. This leads to high CPU load and this load does not goes down.
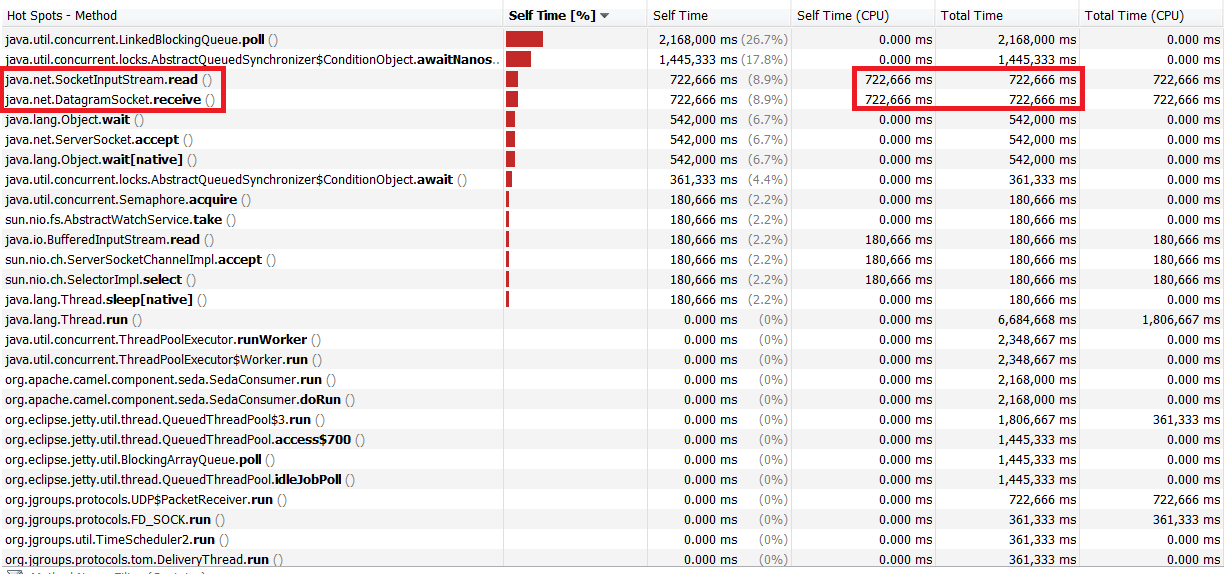
One of our threads has stopped and this is line from its thread dump
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <68f06> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.parkNanos(Unknown Source)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(Unknown Source)
at org.infinispan.stream.impl.DistributedCacheStream$IteratorSupplier.get(DistributedCacheStream.java:754)
at org.infinispan.util.CloseableSuppliedIterator.getNext(CloseableSuppliedIterator.java:26)
at org.infinispan.util.CloseableSuppliedIterator.hasNext(CloseableSuppliedIterator.java:32)
at org.infinispan.stream.impl.RemovableIterator.getNextFromIterator(RemovableIterator.java:34)
at org.infinispan.stream.impl.RemovableIterator.hasNext(RemovableIterator.java:43)
at org.infinispan.commons.util.Closeables$IteratorAsCloseableIterator.hasNext(Closeables.java:93)
at org.infinispan.stream.impl.RemovableIterator.getNextFromIterator(RemovableIterator.java:34)
at org.infinispan.stream.impl.RemovableIterator.hasNext(RemovableIterator.java:43)
at org.infinispan.commons.util.IteratorMapper.hasNext(IteratorMapper.java:26)
So it seems that during iteration through cache cache.entrySet().iterator() Infinispan can get to some infinite loop? This thread stay in this state and not move.
What is proper way to iterate through cache values?
Is there always certainty that following code will end?
final Iterator<> iterator = cache.entrySet().iterator();
while (iterator.hasNext()) {
iterator.next()
}
What could be reason for that?
I read recently that JVM configuration and GC can influence behavior/stability of cluster generally. So I add here also our configuration we use in our environment:
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+UseTLAB -XX:NewSize=128m -XX:MaxNewSize=128m -XX:MaxTenuringThreshold=0 -XX:SurvivorRatio=1024 -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=60 -Xms300m -Xmx300m
Is in configuration something suspicious?
Thanks for help
Tomas