Trouble getting Wildfly 10 HA Config to work!!
(We ran those situations in both Wildfly's 10.0.0.Final and 10.1.0.Final versions)
Hello,
After breaking my brains out during almost 2 weeks I'm finally given up. The Cluster/HA implementation in Wildfly simply doesn't work for Enterprise solutions, but it works fantastic with simple examples provided by the documentation (get.jsp/put.jsp). After going deeper into the internet, searching in Wildfly's documentations and forums, I wasn't able to get our EAR working in a distributed environment using a Domain Configuration (that really sucks, and I'm kind/really frustrated by it - works great in Standalone mode). That doesn't mean I'm not appreciated with the work of thousands of good developers to get this version and product going, just that I think this solution should evolve a little more before going to the Corporate environment. Anyways, as I final resource, if there's some good spirits out there that by any chance already passed by those issues we had, here's a few details about our environment.
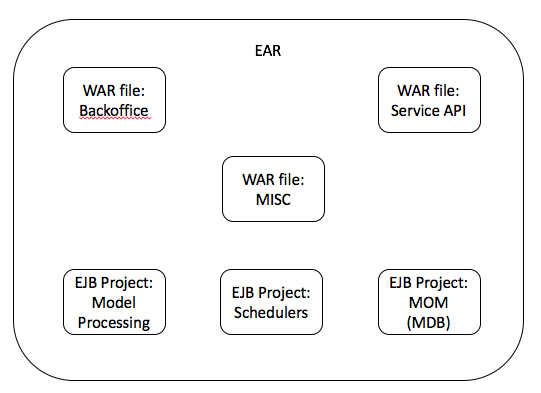
- The EAR package contents (structure) are these:
- My environment general architecture:
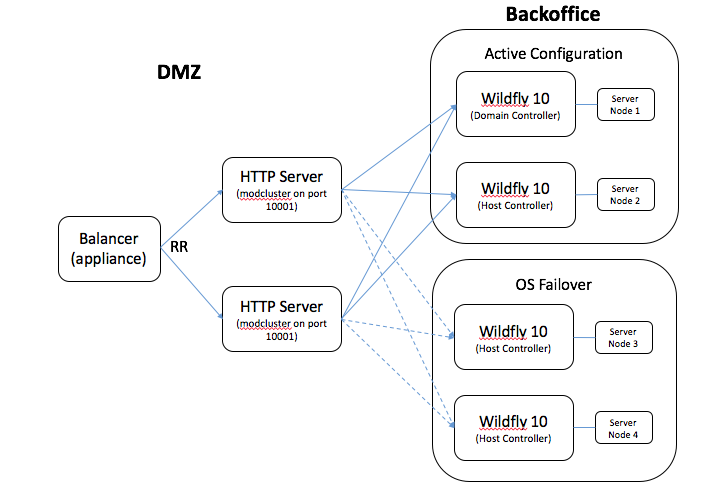
Each Wildfly server have just one server Node configured to it (host.xml), and the profile we are using is "full-ha" with "full-ha-sockets". The JMS queues are all defined in the Domain Controller, the other servers only point to it using a JMS bridge (works like a charm). The first situation arrives with the mod_cluster implementation, CentOS 7 doesn't have the symbols necessary for the mod_cluster.so 1.2.x library versions as described in the documentation (Clustering and Domain Setup Walkthrough - WildFly 10 - Project Documentation Editor - also, the Apache's configuration defined for the entry "LoadModule slotmem_module modules mod_slotmem.so" is incorrect, the correct one is cluster_slotmen_module, it doesn't work if you don't define it like this). So we followed a few steps and were able to download a newer version (1.3.1) and install it successfully in our environment. We ran the HA examples defined by the documentation and also a few of our own. Everything went okay, and the cluster was working and the session was replicated as expected between the server nodes. This is the Apache configuration we used to make the cluster working:
Listen 0.0.0.0:10001
ManagerBalancerName sigma_cluster
#MOD_CLUSTER CONFIGURATION !!!
<VirtualHost *:10001>
<Location />
Require all granted
ProxyPass balancer://sigma_cluster/
ProxyPassReverse balancer://sigma_cluster/
</Location>
ProxyPreserveHost On
KeepAliveTimeout 300
MaxKeepAliveRequests 0
AdvertiseFrequency 5
EnableMCPMReceive
ServerAdvertise on http://<local_ip>:10001
</VirtualHost>
--> "sigma_cluster" is the name of our server group configuration. Each server group in the configuration has only one server node definition.
Well, after a few stress testing in the environment, we actually deployed our EAR, and that's when the problems start occurring ( we run the same EAR in our QA servers. and the only difference between the Production and QA envs are that in QA we use a standalone configuration). I generalized a few of the situations we found:
- For some reason, the Artemis broker doesn't seems to connect the EAR MDBs to the configured queues, e.g.: (ActiveMQNonExistentQueueException[errorType=QUEUE_DOES_NOT_EXIST message=AMQ119017: Queue jms.queue.PaymentQueue does not exist] - this happens in all the servers, including the one that is defined in the DM)
- The queue is there (profile: full-ha): <jms-queue name="PaymentQ" entries="queue/PaymentQueue java:jboss/exported/jms/queues/PaymentQueue"/>
- This error fill up the console, and it doesn't stop until we finish the server (we are running Wildfly as an OS service/systemd).

- For some reason, sometimes a few resources return with a 503 server error and sometimes don't - this is very erratic and for several resources, but it makes the environment very unstable.
- The session is not being replicated between the server nodes defined in the server group configuration (yes we defined the <distributable/> tag in the web.xml for all WAR projects) - we deactivated the option "session sickness" in the domain.xml configuration.

If someone could help, that would be great, but I really hope this could be helpful for someone in the future, to start from where we left.
Best to all, keep'n coding!