Missing entry in JGroup view during parallel start causes Infinispan failure
I'm using WildFly 13.0 version with Infinispan 9.3.0. While bringing up non master servers all at once, at times facing issue due to race condition that occurs between JGroup and infinispan
Say: A1 - 100.1.1.1, A2 - 100.1.1.2, A3 - 100.1.1.3, A4 - 100.1.1.4
A1 elected as master and it is completely up
After that, brought up A2 and A3 at the same time:
A2 send broadcast message for to all the nodes in the cluster during "client-mapping" cache startup
2019-05-15 13:23:24,344 INFO [ServerService Thread Pool -- 32]-[org.infinispan.remoting.transport.jgroups.JGroupsTransport] 100.1.1.2 sending request 3 to all-required:
LockControlCommand{cache=client-mappings, keys=[100.1.1.2], flags=[IGNORE_RETURN_VALUES], unlock=false, gtx=GlobalTx:100.1.1.2:1}
A3 receives the request send by A2
2019-05-15 13:23:24,361 INFO [thread-56,ejb,100.1.1.3]-[org.infinispan.remoting.transport.jgroups.JGroupsTransport] 100.1.1.3 received request 3 from 100.1.1.2: LockControlCommand{cache=client-mappings, keys=[100.1.1.2], flags=[IGNORE_RETURN_VALUES], unlock=false, gtx=GlobalTx:100.1.1.2:1}
Everything works fine till this point,
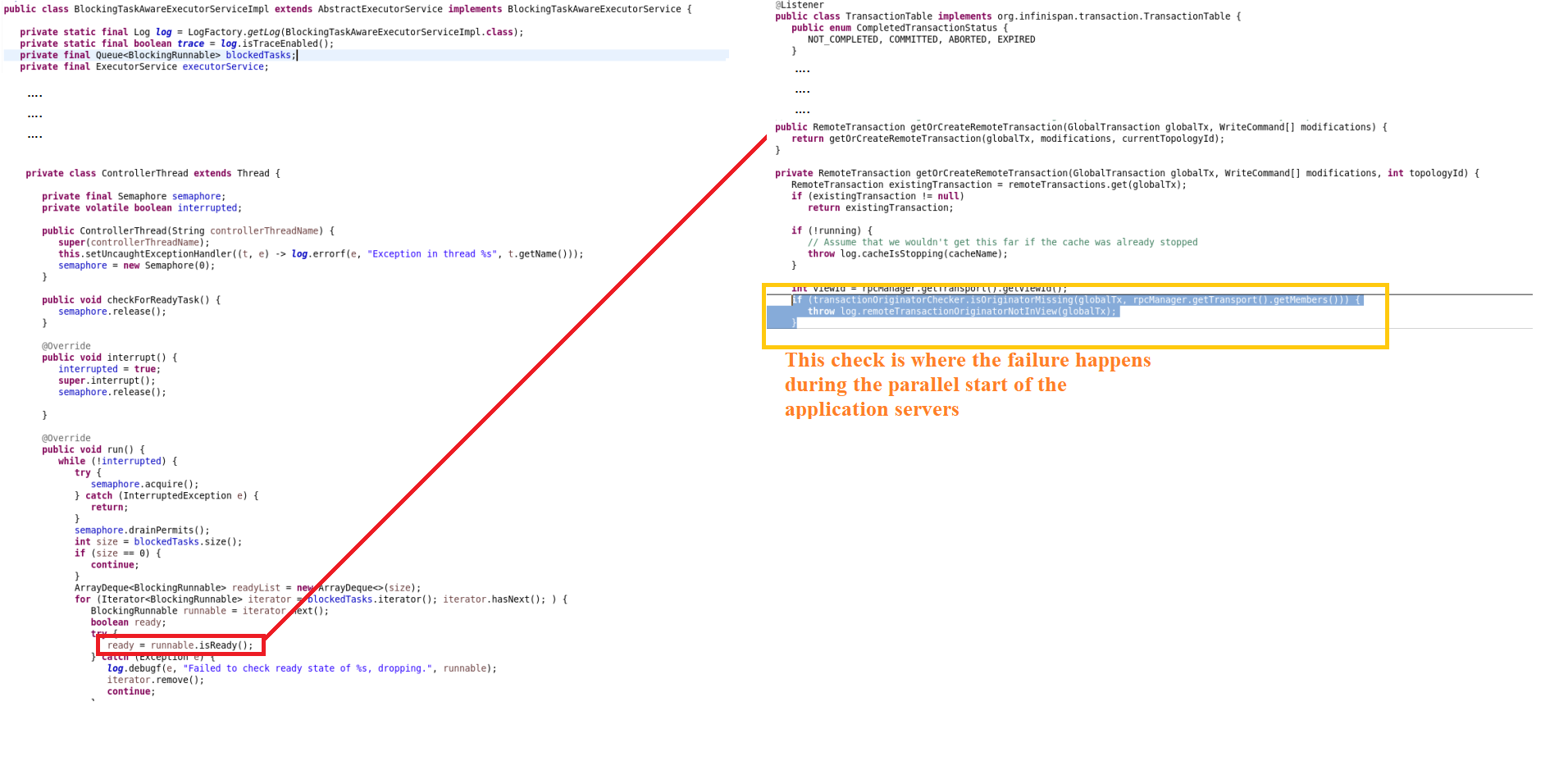
Problem arises when A3 - 100.1.1.3 starts processing the request 3, which is a separate thread
ERROR:
2019-05-15 13:21:14,445 TRACE [transport-thread--p20-t3]-[org.infinispan.statetransfer.StateConsumerImpl] Received new topology for cache client-mappings, isRebalance = true, isMember = true, topology = CacheTopology{id=10, phase=READ_OLD_WRITE_ALL, rebalanceId=4, currentCH=PartitionerConsistentHash:ReplicatedConsistentHash{ns = 256, owners = (2)[100.1.1.1: 84, 100.1.1.3: 85]}, pendingCH=PartitionerConsistentHash:ReplicatedConsistentHash{ns = 256, owners = (3)[100.1.1.1: 63, 100.1.1.3: 64, 100.1.1.4: 67]}, unionCH=PartitionerConsistentHash:ReplicatedConsistentHash{ns = 256, owners = (3)[100.1.1.1: 84, 100.1.1.3: 85, 100.1.1.4: 87]}, actualMembers=[100.1.1.1, 100.1.1.3, 100.1.1.4] persistentUUIDs=[6c7061c6-7546-4873-86f2-1313135d33f8, fbca5ff3-2a7b-46ce-aaa7-d2a454f51078, 663294bc-28d2-46b1-a429-121e8517b388, fa2d1cd7-f535-4ac9-a48d-8ac40d0e88e6]}
2019-05-15 13:23:24,445 DEBUG [Controller-remote-thread-null]-[org.infinispan.util.concurrent.BlockingTaskAwareExecutorServiceImpl] Failed to check ready state of DefaultTopologyRunnable{topologyMode=READY_TX_DATA, commandTopologyId=10, command=LockControlCommand{cache=client-mappings, keys=[100.1.1.2], flags=[IGNORE_RETURN_VALUES], unlock=false, gtx=GlobalTx:100.1.1.2:1}, sync=false}, dropping.: org.infinispan.commons.CacheException: ISPN000481: Cannot create remote transaction GlobalTx:100.1.1.2:1, the originator is not in the cluster view
at org.infinispan.transaction.impl.TransactionTable.getOrCreateRemoteTransaction(TransactionTable.java:376)
at org.infinispan.transaction.impl.TransactionTable.getOrCreateRemoteTransaction(TransactionTable.java:361)
at org.infinispan.commands.control.LockControlCommand.createContext(LockControlCommand.java:139)
at org.infinispan.commands.control.LockControlCommand.createContext(LockControlCommand.java:42)
at org.infinispan.remoting.inboundhandler.action.PendingTxAction.createContext(PendingTxAction.java:115)
at org.infinispan.remoting.inboundhandler.action.PendingTxAction.init(PendingTxAction.java:58)
at org.infinispan.remoting.inboundhandler.action.BaseLockingAction.check(BaseLockingAction.java:39)
at org.infinispan.remoting.inboundhandler.action.DefaultReadyAction.isReady(DefaultReadyAction.java:42)
at org.infinispan.remoting.inboundhandler.action.DefaultReadyAction.isReady(DefaultReadyAction.java:45)
at org.infinispan.remoting.inboundhandler.NonTotalOrderTxPerCacheInboundInvocationHandler$1.isReady(NonTotalOrderTxPerCacheInboundInvocationHandler.java:114)
at org.infinispan.util.concurrent.BlockingTaskAwareExecutorServiceImpl$ControllerThread.run(BlockingTaskAwareExecutorServiceImpl.java:178)
GMS update happens at the same time frame
2019-05-15 13:23:21,589 DEBUG [ServerService Thread Pool -- 3]-[org.jgroups.protocols.pbcast.GMS] 100.1.1.29: installing view [100.1.1.1|2] (3) [100.1.1.1, 100.1.1.3, 100.1.1.4]
2019-05-15 13:23:21,596 DEBUG [FD_SOCK pinger-26,ejb,100.1.1.3]-[org.jgroups.protocols.FD_SOCK] 100.1.1.29: pingable_mbrs=[100.1.1.1, 100.1.1.3, 100.1.1.4], ping_dest=100.1.1.1
2019-05-15 13:23:23,623 DEBUG [thread-54,ejb,100.1.1.3]-[org.jgroups.protocols.pbcast.GMS] 100.1.1.29: installing view [100.1.1.1|3] (4) [100.1.1.1, 100.1.1.2, 100.1.1.3, 100.1.1.4]
Sequence
1. The remote call from A2 lands on A3,
2. but the clusterView of A3 was not updated with A2 during that time,
3. A3 failed in processing A2's request and throws "originator is not in the cluster view" exception.
How to fix this properly?
Is there a way to make this in sequence, i.e Cluster View update first, followed by inifinispan cache during the startup to avoid the above situation during parallel start?
Thanks,
Sudhan.