This content has been marked as final.
Show 29 replies
-
1. Re: RHQ 4.6 high CPU usage on Linux (RHEL)
jayshaughnessy Mar 11, 2013 11:04 AM (in response to pathduck)
Please keep us posted of anything you learn. If you are running an RHQ agent on the RHQ Server machine, and have imported the RHQ Server Resource, please try not running the agent and see if that reduces the CPU load.
-
2. Re: RHQ 4.6 high CPU usage on Linux (RHEL)
pathduck Mar 11, 2013 12:13 PM (in response to jayshaughnessy)
I have some hours with profiling now, and have the hprof output which basically starts like this:
CPU SAMPLES BEGIN (total = 10715781) Mon Mar 11 16:15:22 2013 rank self accum count trace method 1 34.82% 34.82% 3731294 302943 java.net.SocketInputStream.socketRead0 2 22.40% 57.22% 2400071 301217 sun.nio.ch.EPollArrayWrapper.epollWait 3 17.92% 75.14% 1920278 301759 java.net.PlainSocketImpl.socketAccept 4 9.43% 84.57% 1010622 302849 java.net.SocketInputStream.socketRead0 5 4.48% 89.05% 480027 302272 java.net.PlainSocketImpl.socketAccept 6 2.90% 91.95% 310638 303051 java.security.AccessController.getStackAccessControlContext 7 0.79% 92.74% 84719 303025 java.lang.SecurityManager.getClassContext 8 0.42% 93.16% 45365 305871 java.lang.SecurityManager.getClassContext 9 0.37% 93.54% 40060 303120 java.security.AccessController.getStackAccessControlContext 10 0.35% 93.88% 37411 305212 java.net.SocketOutputStream.socketWrite0Unfortunately running without the local RHQ Agent did not change it, still seeing the RHQ Server process using from 100-200 % cpu. Load isn't too bad though, about 1.0 - 1.5 but we have a lot of resources under it.
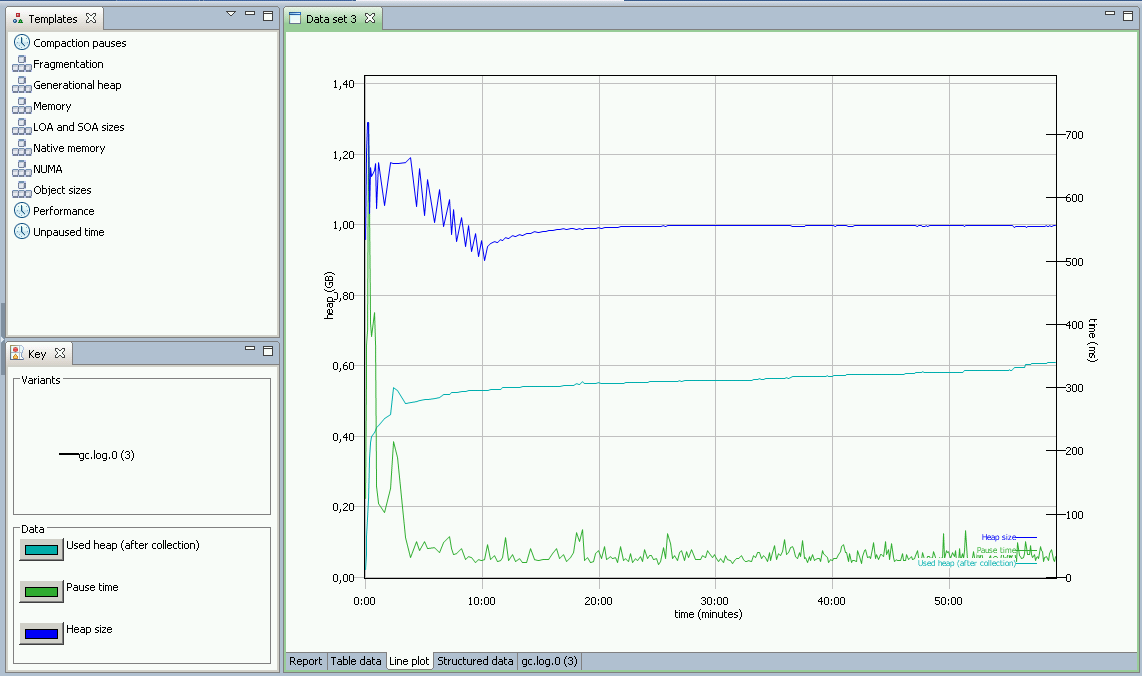
I am running with verbose GC on but cannot so far see anything unusual (see attachment).
-
RHQServer-Heap.png 36.3 KB
-
-
3. Re: RHQ 4.6 high CPU usage on Linux (RHEL)
jayshaughnessy Mar 11, 2013 2:07 PM (in response to pathduck)
I've been poking around your info and also the traces in the releted Bugzilla and then the net. I found one interesting thread that may be related to the stack traces and hprof data I see:
https://github.com/netty/netty/issues/327
https://github.com/netty/netty/pull/565
The behavior may be related, and it does mention that it can be related to Java and/or netty version. There is a workaround property you can try setting, or, maybe more easily, try updating to the specified version of java7. Of course if you are already using that version the problem is likeley something else. Let me know what you find out because i can't reproduce here.
-
4. Re: RHQ 4.6 high CPU usage on Linux (RHEL)
pathduck Mar 11, 2013 3:47 PM (in response to jayshaughnessy)
Thanks for looking into this Jay.
We are running Java 1.7.11 but tomorrow I will try to update to .17 and see if it helps, and possibly downgrade to 1.6.38 which was the version we ran RHQ 4.5 on.
If that does not help also I will try setting the Dorg.jboss.netty.epollBugWorkaround property.
-
5. Re: RHQ 4.6 high CPU usage on Linux (RHEL)
pathduck Mar 12, 2013 9:06 AM (in response to pathduck)
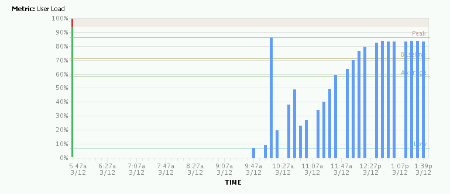
Update; we have two RHQ installations for testing, and I am running one with Java 1.7.u17 and one with 1.6.u38. Both are still high in CPU usage, 180-190% on two cores.
I also tried the netty.epollBugWorkaround setting but it didn't appear to make any difference.
As you can see it slowly rises to full cpu utilization over a couple of hours:
Some more info about this RHQ installation:
Using an Oracle 11.2.0.3 database.
Disabled unnecessary agent and server plugins.
Set -Xms1024M and -Xmx2048M, on a 8GB machine.
13 Platforms, 52 servers, 1838 Service, 7 Groups.
Any ideas what can be done to further debug this problem?
-
6. Re: RHQ 4.6 high CPU usage on Linux (RHEL)
jayshaughnessy Mar 12, 2013 1:06 PM (in response to pathduck)
Stian, thanks for investigating that potential issue. It was worth a try but it seems that the problem is something else.
In general I think we're going to need some more detailed profiling to figure this out. But before that we could try a simple test to see if the CPU load somewhat normal, or totally aberrant. If we, for example, shut down 1/2 of the agents, does the CPU utilization go down? If not, what about all of the Agents?
If you are able to run a real profiler, like JProfiler, that would be great. For some quick heap analysis tips see http://management-platform.blogspot.com/2009/02/quick-java-heap-analysis.html.
-
7. Re: RHQ 4.6 high CPU usage on Linux (RHEL)
pathduck Mar 13, 2013 6:14 AM (in response to jayshaughnessy)
Thanks for the tip - I'll try to do some digging.
I guess using jmap/jhat is basically the same as generating a heap dump and parsing it with for instance Eclipse Memory Analyzer?
I have used jhat before but find it not all that useful unless you are a developer maybe.
And not sure how a heap analysis would help a high cpu issue? I'll see what I can find. and also re-enable the other profiling and let it run overnight.
Also I did a stop of all the agents - cpu usage dropped to almost nothing instantly. Then I tried starting about half the agents and saw an increase to about 100-150% usage, not as high as before but still.
Btw, in production on RHQ 4.5.1 we have 17 platforms, 118 servers and 6446 services, avg. mettrics/min 436. This with a user load on RHQ of about 2-3%.
Avg. metrics/min for our test-server (4.6) is about 106.
-
8. Re: RHQ 4.6 high CPU usage on Linux (RHEL)
jayshaughnessy Mar 13, 2013 9:14 AM (in response to pathduck)
Stian, some interesting info. As you know, 4.6 is significantly different from 4.5.1 in that it is now based on AS7 as opposed to AS 4.2.3, so the server architecture has changed quite a lot in addition to other features etc. By removing the agents and seeing the CPU usage drop we can at least infer that there is a correlation between this issue and agent communication or requests coming into the server, and not purely server-side processing. That doesn't narrow it down very much but it's something. Also, it seems that each agent may contribute incrementally to the issue.
Some sort of profiler is really what we need here. Is there anything in either the server or agent logs that you think may be relevant? Really a profiler is what we need to identify where the time is being spent on the server.
-
9. Re: RHQ 4.6 high CPU usage on Linux (RHEL)
pathduck Mar 14, 2013 7:05 AM (in response to jayshaughnessy)
Hello. I have now been running the hprof sampler overnight, and have the following top consumers.
CPU SAMPLES BEGIN (total = 80578234) Thu Mar 14 09:28:43 2013 rank self accum count trace method 1 31.98% 31.98% 25772514 301109 sun.nio.ch.EPollArrayWrapper.epollWait 2 25.60% 57.59% 20631673 301630 java.net.PlainSocketImpl.socketAccept 3 20.73% 78.31% 16700319 302299 java.net.SocketInputStream.socketRead0 4 6.40% 84.72% 5158267 302249 java.net.PlainSocketImpl.socketAccept 5 6.25% 90.96% 5034780 302693 java.net.SocketInputStream.socketRead0 6 1.95% 92.91% 1571085 302938 java.security.AccessController.getStackAccessControlContext 7 0.42% 93.34% 341665 305927 java.net.SocketOutputStream.socketWrite0So really, nothing specifically new here I think - but I have a strong suspicion that the count of calls here is extremely high. I'd have to verify with our other installation for this though, possibly running 2 hours of both.
I suspected first it might have to do with the JBoss AS7 plugin, so I stopped all the agents and started only those running on Tomcat, but the cpu still increased for each agent I started up again. So it does not seem to be related to the JBoss AS7 plugin.
Another suspicion was the Java version, since some of the agents still run with Java 1.6, because that's what is installed on the servers except on the RHQ server, where we run 1.7. So I only started the agent on the RHQ server machine and still saw an increase in CPU usage.
My main theory now is that this is network traffic, and I ran a tcpdump with port 7080 and only traffic to/from a single host. I ran the test for two minutes. I got the following results:
timeout -sHUP 2m tcpdump -nn port 7080 and host xxx.yyy.
Test (4.6):
8770 packets captured
8830 packets received by filter
8 packets dropped by kernel
Production (4.5.1):
46 packets captured
50 packets received by filter
0 packets dropped by kernel
So that's a pretty major difference wouldn't you say? What could account for this massive difference in data traffic between agent and server?
Is there any way I could send you tcpdump output without exposing it to everyone? I'd rather not expose IP adresses and host names etc.
-
10. Re: RHQ 4.6 high CPU usage on Linux (RHEL)
mazz Mar 14, 2013 8:44 AM (in response to pathduck)
Can you do the same test with 4.5.1 vs. 4.6, only this time, turn on command tracing in the agent? In the agent, there is an agent prompt command "debug --comm=true" that does this. Then, let it run for a bit like you've been doing. In your logs/ directory, there is a command-trace.log where the agent traffic to the server is kept. Zip up that log from both runs (4.5.1 and 4.6) and attach here. I wonder if that would show the difference and perhaps could help.
Here's the steps I would do:
1) run the agent with "--nostart" so it starts but doesn't start sending messages yet -- "rhq-agent.sh --nostart"
2) in the agent prompt, enter "debug --comm=true" to turn on comm debugging
3) now start the agent's internals via the agent prompt "start"
Your logs/command-trace.log should start filling up.
Some details on the comm tracing is found here if interested: https://docs.jboss.org/author/display/RHQ/Design-DebuggingCommunications
-
11. Re: RHQ 4.6 high CPU usage on Linux (RHEL)
pathduck Mar 15, 2013 6:11 AM (in response to mazz)
Hi again, stuff to do yesterday so didn't have time to check up on this.
I did run the comm debugging for some time both on a production agent and one of the test agents running 4.6.
What I see is a huge amount of calls to getResourcesAsList.
And what is a bit worrisome is that a lot of them seem to be related to Samba, Postfix, SSHD, Grub, Cron and Cobbler, which is stuff we have disabled in the agent plugins (we have no need for these).
I am attaching files from both systems, having removed some stuff like hostnames etc.
-
command-trace-test.zip 127.0 KB
-
command-trace-prod.zip 2.4 KB
-
-
12. Re: RHQ 4.6 high CPU usage on Linux (RHEL)
mazz Mar 15, 2013 9:03 AM (in response to pathduck)
OK, its clear that those plugins aren't actually disabled. You should double check that. In your agent's /plugin directories, those should be there (I think, IIRC, if the plugins are disabled in the Administration>AgentPlugins page, the agent will be told and will delete those plugins). If you go in your Discovery Queue in the GUI, do you see things like GRUB and SSHD and things like that? If you do, things aren't disabled. If you don't, that doesn't necessarily mean they are disabled - you can go to the agent prompt (if you run the test agent in foreground) and run "plugins info" and see what it says.
-
13. Re: RHQ 4.6 high CPU usage on Linux (RHEL)
pathduck Mar 15, 2013 9:57 AM (in response to mazz)
Ok -
I think this is gettings somewhere maybe - we used to run the plugins for those resources, then disabled them and did a 'reload plugins' on all the agents. So the plugins folder on the agent installations contain just the plugins we are interested in.
But I did already have a number of discovered resources of the above types, which I put into "Ignored". Maybe that was a mistake or the reason for this? I don't really know what to do about those, but I will try to - first Import them, then do Uninventory. If correct, then they should *not* show up in the discovery queue.
So 4.6 might have a problem with resources in the Ignore list, is that a possible explanation? This certainly is not a problem in 4.5.1, we have many resources in the Ignored list there.
-
14. Re: RHQ 4.6 high CPU usage on Linux (RHEL)
jayshaughnessy Mar 15, 2013 10:16 AM (in response to pathduck)
Stian,
If you deployed those plugins to the server they have been uploaded to the agents. If you disabled them you may want to go the next step and purge them. This is done from the Administration Agent Plugins are of the GUI. Purging them will completely remove them. Then you can see whether there is a difference in performance. Does your production env run those plugins? Is that a difference between the 4.5.1 and 4.6 environments?