ModeShape 3.5: performance
Hi,
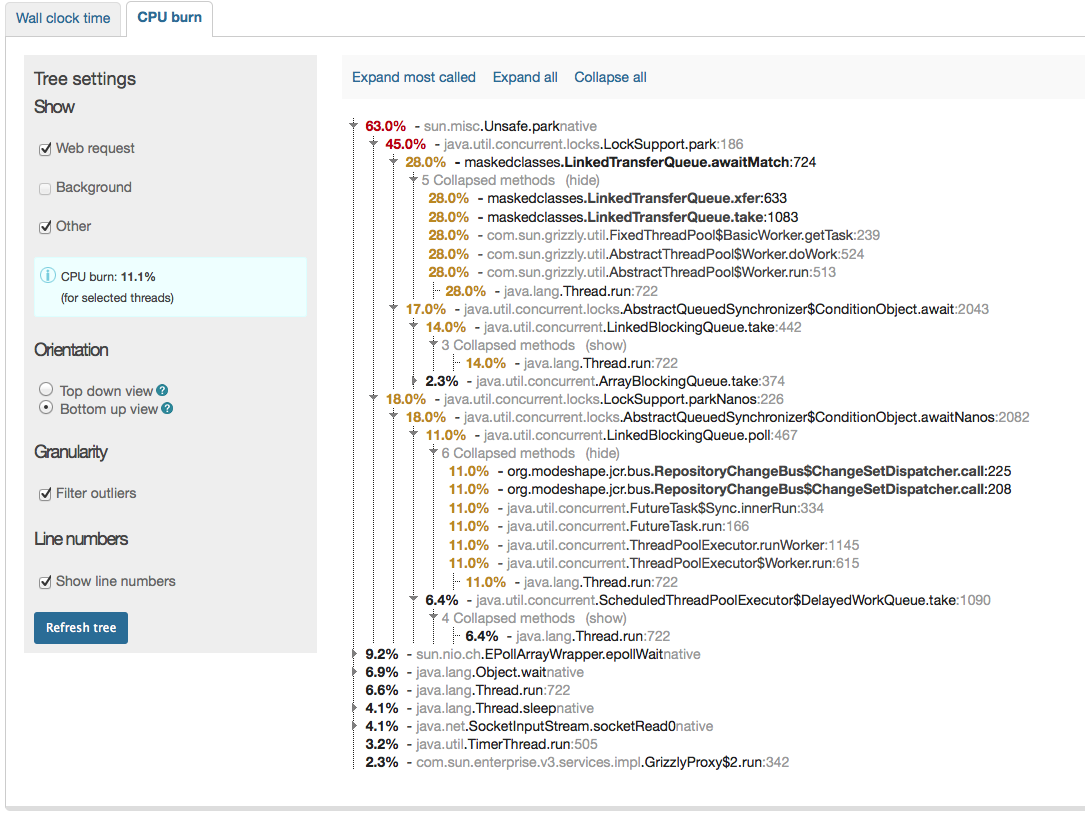
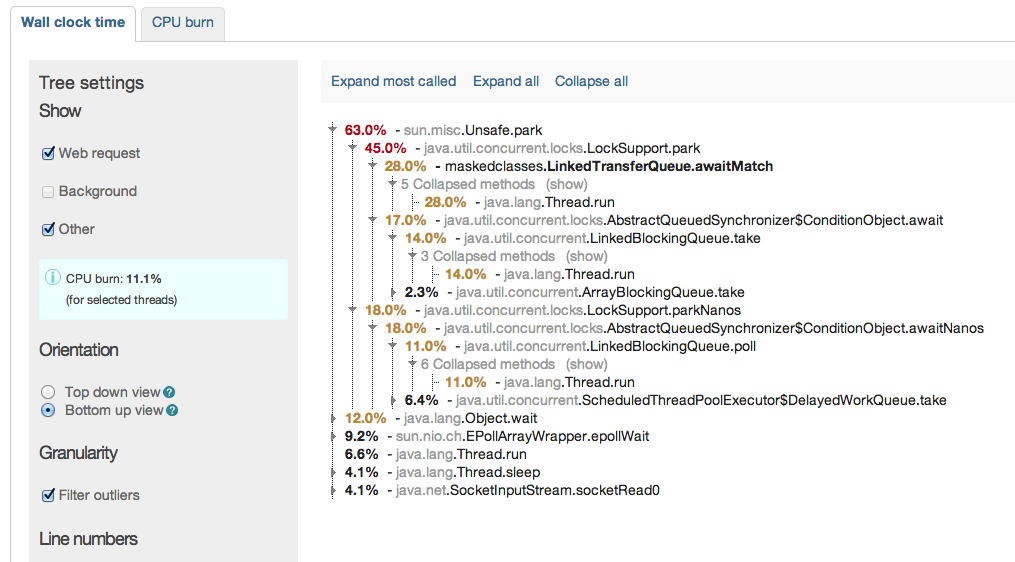
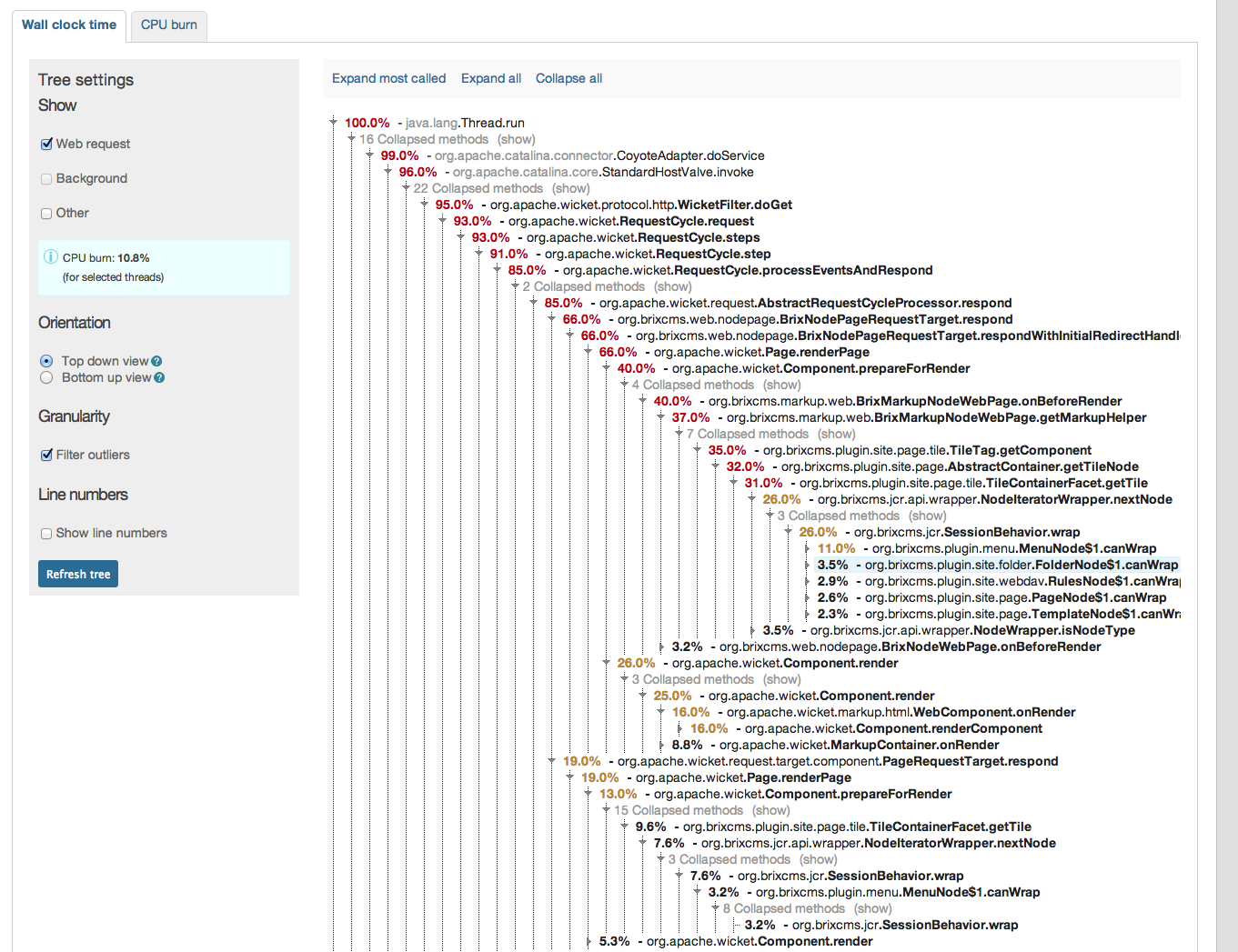
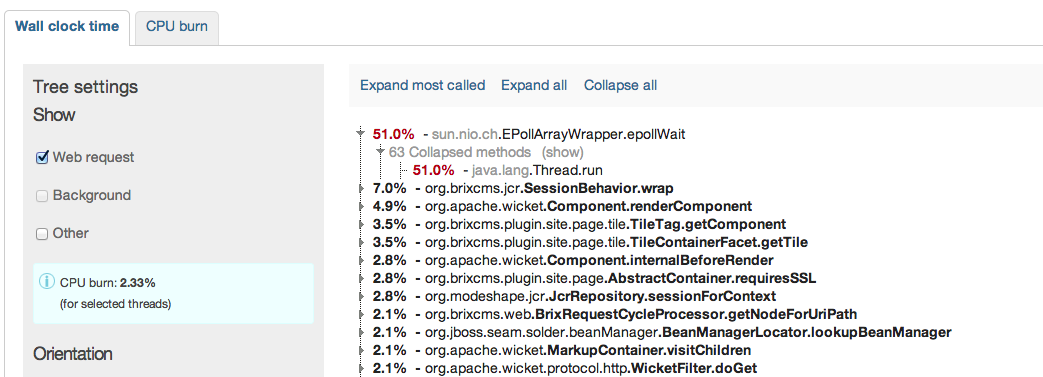
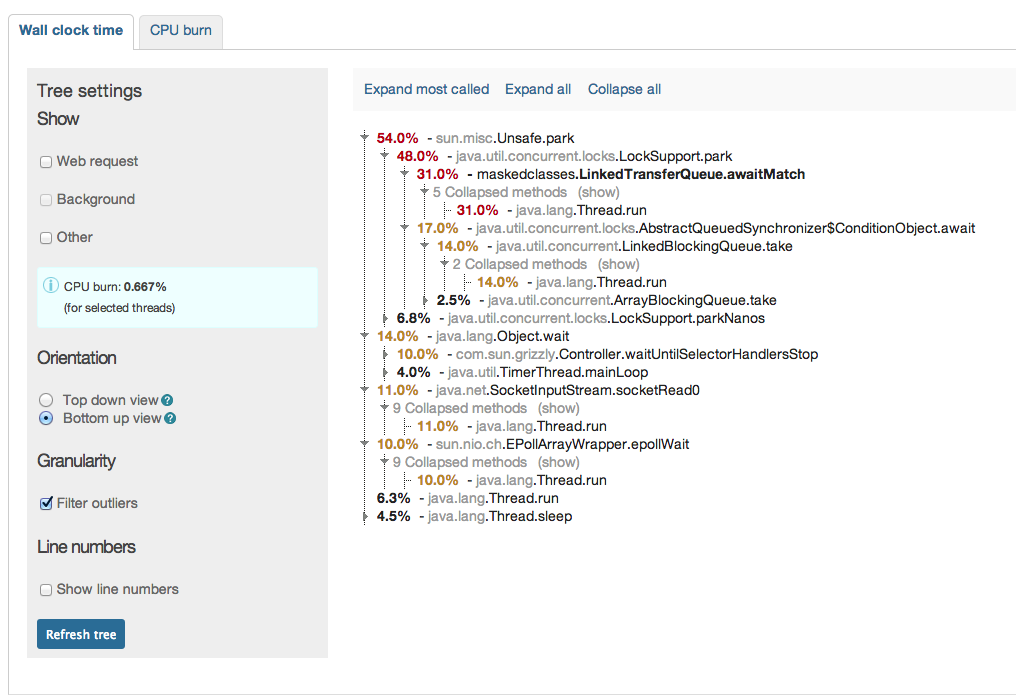
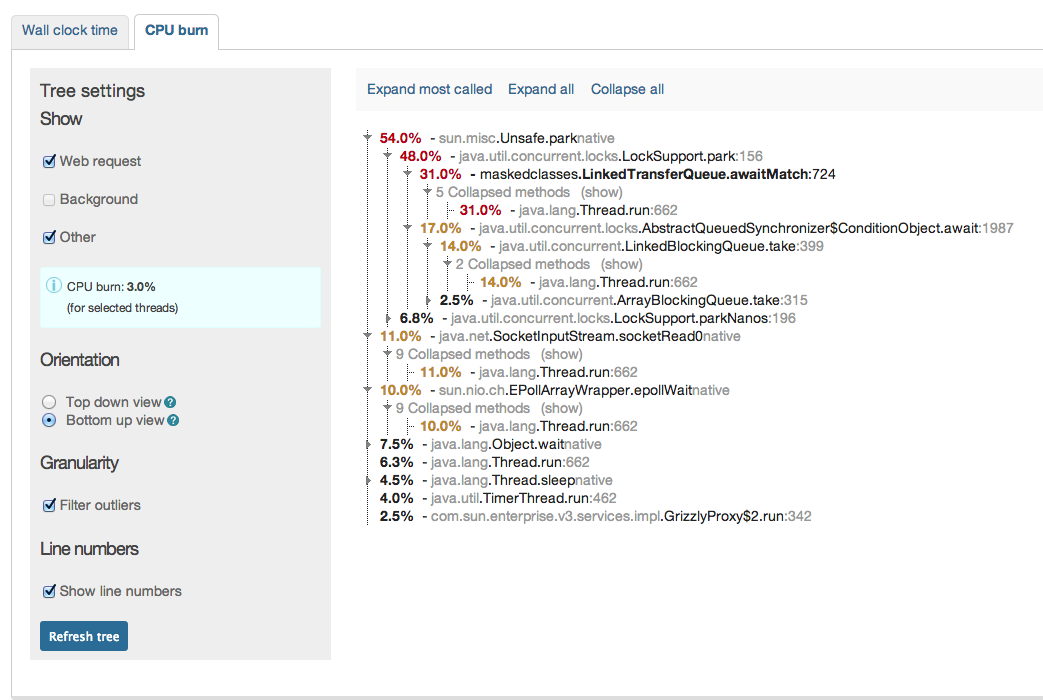
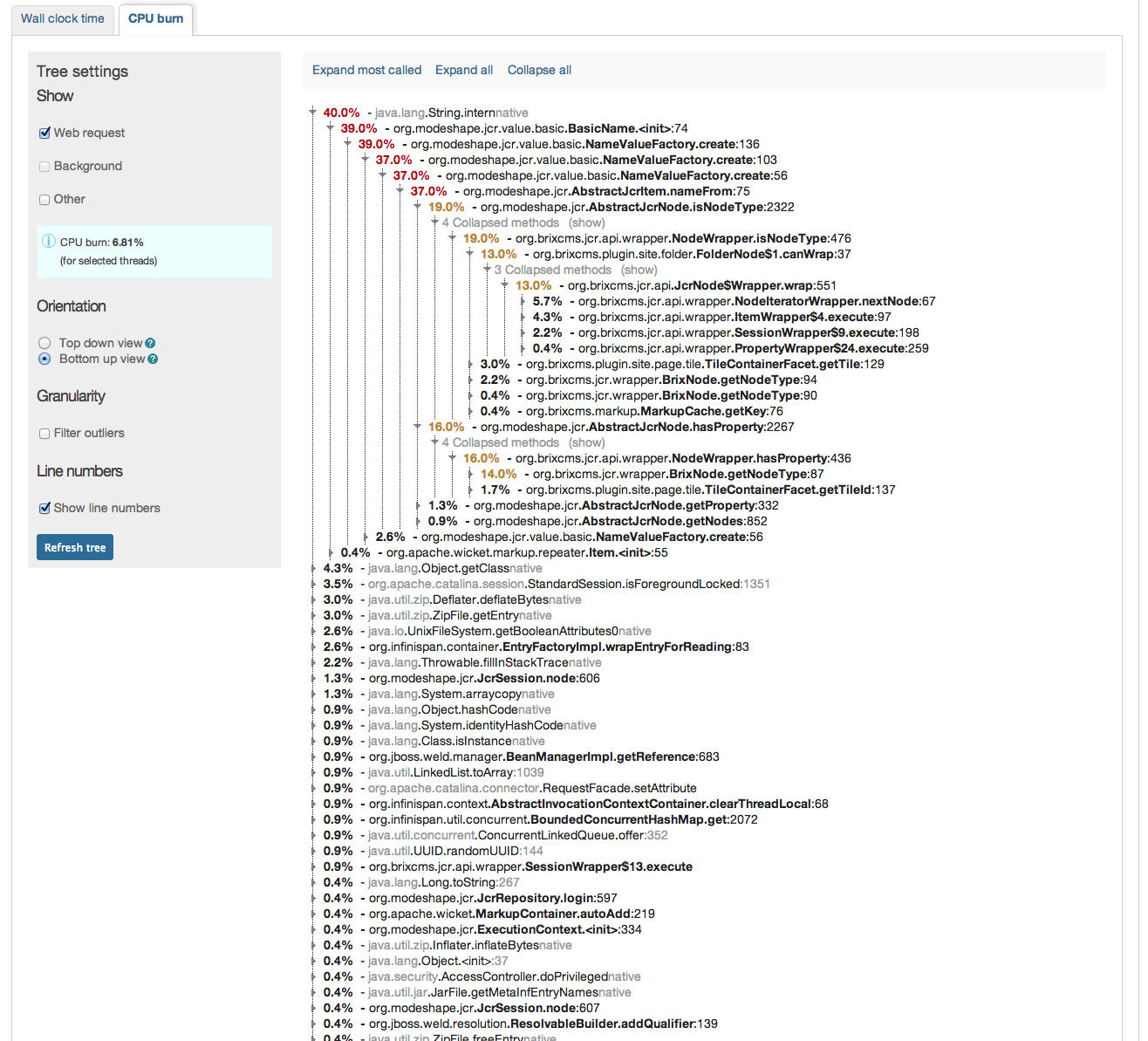
we finally switched from ModeShape 2.8.1 to ModeShape 3.5.0. All works very well so far, however we have seen some slow rates in term of performance compared to 2.8 (we used the DiskStore).
Our whole web-app stores its content within a modeshape JCR repo and therefore the page rendering times clearly can state the difference. With 2.8 we got on a static page ~120-160 ms while we now get about ~220-260ms for the same page in warmed up server. This increase of about 100ms is visible over all pages. This is now using the "org.infinispan.loaders.file.FileCacheStore" which we chosen after we've seen even worse numbers with "org.infinispan.loaders.bdbje.BdbjeCacheStore" and the worst: "org.infinispan.loaders.jdbm.JdbmCacheStore";
Interestingwise especially the BdbJE shoult outperform the FileCacheStore by a magnitude according to infinispan docs. After some testing it turns out that the not very fast IO from the HD on our server might be the reason for this. As if I test it here on a FusionDrive (meaning on SSD part) the speed difference not only disappeas, but mode 3.5 is even faster than old mode 2.8.
For testing purposes I completely switched to an pure in-memory and then the numbers were blazing, meaning the time for the test page down to ~80-100ms;
So it seems the cachestore config is the vital part thats not going so wall here. Our current production json-config reads as follows:
{
"name": "wwRepo",
"jndiName": "",
"workspaces": {
"default": "default",
"allowCreation": true
},
"security": {
"anonymous": {
"useOnFailedLogin": true
}
},
"storage": {
"cacheConfiguration": "cache-ms3.xml",
"cacheName": "wwRepoCache",
"transactionManagerLookup": "org.infinispan.transaction.lookup.GenericTransactionManagerLookup",
"binaryStorage": {
"type": "file",
"directory": "/z-modeshape/appshop-mode3/jcr",
"minimumBinarySizeInBytes": 524288
}
},
"sequencing": {
"removeDerivedContentWithOriginal": true,
"sequencers": {
"cndSequencer": {
"description": "CND Sequencer Same Location",
"classname": "CNDSequencer",
"pathExpressions": [ "default://(*.cnd)/jcr:content[@jcr:data]" ]
}
}
}
}
With infinispan as this:
<infinispan xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="urn:infinispan:config:5.1 http://www.infinispan.org/schemas/infinispan-config-5.1.xsd" xmlns="urn:infinispan:config:5.1"> <!-- Global settings shared by all caches managed by this cache container. --> <global/> <!-- Individually named caches. --> <namedCache name="wwRepoCache"> <transaction transactionManagerLookupClass="org.infinispan.transaction.lookup.GenericTransactionManagerLookup" transactionMode="TRANSACTIONAL" lockingMode="OPTIMISTIC"/> <loaders passivation="false" shared="false" preload="true"> <loader class="org.infinispan.loaders.file.FileCacheStore" fetchPersistentState="false" purgeOnStartup="false"> <!-- See the documentation for more configuration examples and flags. --> <properties> <!-- We have to set the location where we want to store the data. --> <property name="location" value="/z-modeshape/appshop-mode3/filecache"/> </properties> </loader> </loaders> </namedCache> </infinispan>
So, this config is rather basic and I wonder how can we configure modeshape and infinispan that it performs well by storing the cache by its full size in memory and also in a cachstore, while not querying the cachstore when data needed as it should be all in memory though we still dont loose all data when system is shutdown?
Regards,
KB
PS: the write times dont really matter so far, as we write very very rare new data (which then is usually a whole new workspace that gets imported or cloned over an existing one);