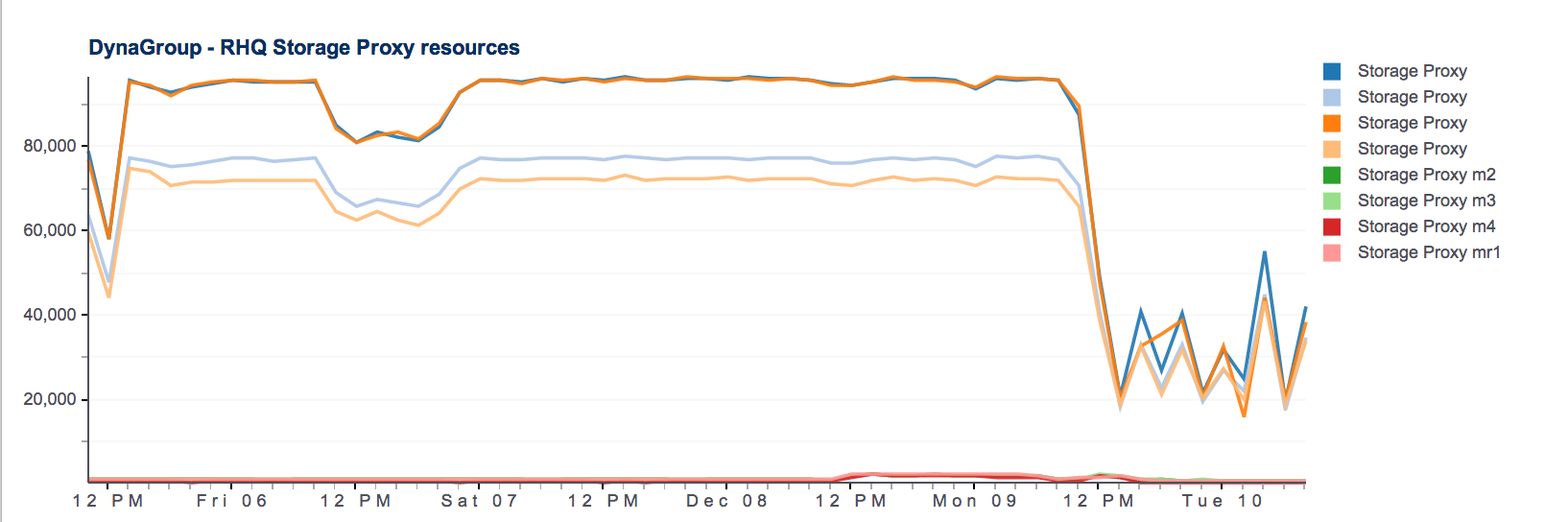
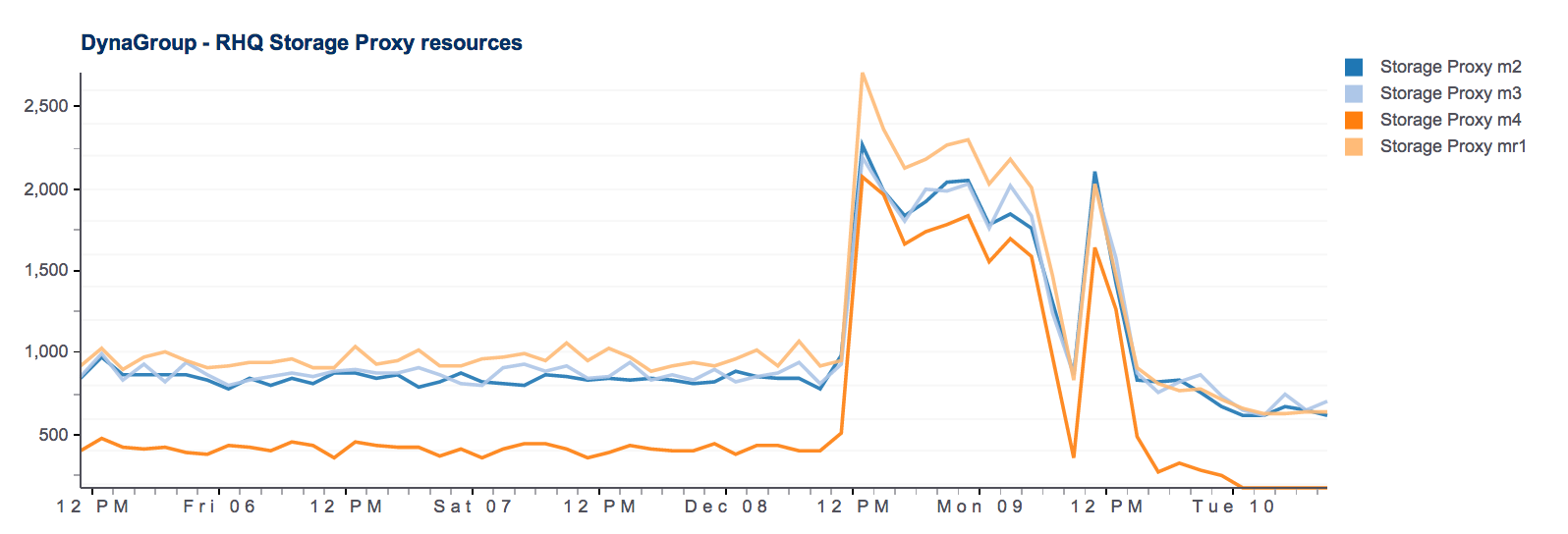
RHQ 4.9; Data compression taking a long, long time
Initially I noticed that graphs were missing data more than a week old.
Digging a bit deeper, I've been seeing the following being logged:
server.log:08:41:43,250 INFO [org.rhq.enterprise.server.scheduler.jobs.DataPurgeJob] (RHQScheduler_Worker-3) Data Purge Job FINISHED [811155108]ms
For a job that runs hourly, this is a long time... However, performance is very good with reading and writing metrics data in general.
So given the purge job takes a long, long time hourly data is very sporadic. This is disk space percentage for a filesystem, as an example:
cqlsh> select * from rhq.one_hour_metrics where schedule_id = 5246208; schedule_id | time | type | value -------------+--------------------------+------+----------- 5246208 | 2013-11-20 17:00:00+0000 | 0 | nan 5246208 | 2013-11-20 17:00:00+0000 | 1 | nan 5246208 | 2013-11-20 17:00:00+0000 | 2 | 0 5246208 | 2013-11-20 18:00:00+0000 | 0 | 2.7201e+08 5246208 | 2013-11-20 18:00:00+0000 | 1 | 2.72e+08 5246208 | 2013-11-20 18:00:00+0000 | 2 | 2.7201e+08 5246208 | 2013-11-21 22:00:00+0000 | 0 | 2.7199e+08 5246208 | 2013-11-21 22:00:00+0000 | 1 | 2.7199e+08 5246208 | 2013-11-21 22:00:00+0000 | 2 | 2.7199e+08 5246208 | 2013-11-24 14:00:00+0000 | 0 | nan 5246208 | 2013-11-24 14:00:00+0000 | 1 | nan 5246208 | 2013-11-24 14:00:00+0000 | 2 | 0 5246208 | 2013-11-24 21:00:00+0000 | 0 | nan 5246208 | 2013-11-24 21:00:00+0000 | 1 | nan 5246208 | 2013-11-24 21:00:00+0000 | 2 | 0 5246208 | 2013-12-03 18:00:00+0000 | 0 | 2.7957e+08 5246208 | 2013-12-03 18:00:00+0000 | 1 | 2.7956e+08 5246208 | 2013-12-03 18:00:00+0000 | 2 | 2.7957e+08
I've also noticed things like queries to Cassandra are hanging:
cqlsh> select * from system_auth.users; name | super -----------+------- rhqadmin | True cassandra | True
This can take about 30 seconds for some weird reason, though querying by 'where name = 'x'' comes back instantaneously. I've run node repair on this keyspace (and rhq keyspace) and it doesn't seem to speed up anything.
I've also seen disk space for Cassandra simply go up and up. Aside from the possible decommission each node and start over plan, is there something that might be done here? I'm guessing there might be some carry-over from when I messed up the file system configuration, but I assume that repair would have fixed this.