This content has been marked as final.
Show 18 replies
-
1. Re: Cannot find messages after failover in Colocated symmetrical cluster
ataylor Apr 4, 2014 3:58 AM (in response to vijay.balasubramanian)
your messages are sitting on the backup server, since you have redistribution turned of they will stay there until a stand alone client connects.
-
2. Re: Cannot find messages after failover in Colocated symmetrical cluster
vijay.balasubramanian Apr 6, 2014 1:08 PM (in response to ataylor)
Thanks for your reply.
I have redistribution turned off as i wanted one EAP1 to serve all client requests. If EAP1 fails there is an external mechanism to direct traffic to EAP2.
Expectation is that any messages that were left unconsumed in EAP1 should be available in EAP2 for consuming.
The problem.
- I have EAP1 and EAP2 setup in colocated live-backup.
- I produced and added 5000 msgs to validOrderQueue in EAP1. There is NO consumer in EAP1, so all msgs are waiting in the queue
- Killed EAP1. ( i see EAP2 recognizes EAP1 failure and backup in EAP2 becomes live)
- I run a consumer on EAP2 and looked for msgs in validOrderQueue. I do not see any messages coming through the backup server.
I am using the In-vm connection factory in both EAP1 and EAP2 for producing and consuming. Both producer and consumer clients run on respective EAPs.
HonetQ version bundled in EAP 6.2 - hornetq-server-2.3.12.Final-redhat-1.jar:2.3.12.Final-redhat-1
Thanks and Regards,
Vijay
Here is the tail snippet from EAP2 logs....
12:03:34,788 INFO [org.jboss.web] (ServerService Thread Pool -- 64) JBAS018210: Register web context: /hornetq-consumer
12:03:34,948 INFO [org.jboss.as.server] (Controller Boot Thread) JBAS018559: Deployed "hornetq-consumer.war" (runtime-name : "hornetq-consumer.war")
12:03:35,141 INFO [org.jboss.as] (Controller Boot Thread) JBAS015961: Http management interface listening on http://127.0.0.1:10190/management
12:03:35,142 INFO [org.jboss.as] (Controller Boot Thread) JBAS015951: Admin console listening on http://127.0.0.1:10190
12:03:35,142 INFO [org.jboss.as] (Controller Boot Thread) JBAS015874: JBoss EAP 6.2.0.GA (AS 7.3.0.Final-redhat-14) started in 13279ms - Started 212 of 352 services (139 services are passive or on-demand)
12:03:55,305 WARN [org.hornetq.core.client] (Thread-2 (HornetQ-client-global-threads-1935643342)) HQ212037: Connection failure has been detected: HQ119015: The connection was disconnected because of server shutdown [code=DISCONNECTED]
12:03:56,046 INFO [org.hornetq.core.server] (HQ119000: Activation for server HornetQServerImpl::serverUUID=e4a0ce9d-bd3f-11e3-a283-29ae42ad0ee3) HQ221020: Started Netty Acceptor version 3.6.6.Final-redhat-1-fd3c6b7 127.0.0.1:5745 for CORE protocol
12:03:56,057 WARN [org.hornetq.core.client] (hornetq-discovery-group-thread-dg-group1) HQ212034: There are more than one servers on the network broadcasting the same node id. You will see this message exactly once (per node) if a node is restarted, in which case it can be safely ignored. But if it is logged continuously it means you really do have more than one node on the same network active concurrently with the same node id. This could occur if you have a backup node active at the same time as its live node. nodeID=e4a0ce9d-bd3f-11e3-a283-29ae42ad0ee3
12:03:56,067 INFO [org.hornetq.core.server] (HQ119000: Activation for server HornetQServerImpl::serverUUID=e4a0ce9d-bd3f-11e3-a283-29ae42ad0ee3) HQ221010: Backup Server is now live
12:03:56,113 INFO [org.hornetq.core.server] (Thread-6 (HornetQ-server-HornetQServerImpl::serverUUID=e4a0ce9e-bd3f-11e3-a283-832a8d9e235e-169216509)) HQ221027: Bridge ClusterConnectionBridge@33a6a6f8 [name=sf.my-cluster.e4a0ce9d-bd3f-11e3-a283-29ae42ad0ee3, queue=QueueImpl[name=sf.my-cluster.e4a0ce9d-bd3f-11e3-a283-29ae42ad0ee3, postOffice=PostOfficeImpl [server=HornetQServerImpl::serverUUID=e4a0ce9e-bd3f-11e3-a283-832a8d9e235e]]@21bfe46 targetConnector=ServerLocatorImpl (identity=(Cluster-connection-bridge::ClusterConnectionBridge@33a6a6f8 [name=sf.my-cluster.e4a0ce9d-bd3f-11e3-a283-29ae42ad0ee3, queue=QueueImpl[name=sf.my-cluster.e4a0ce9d-bd3f-11e3-a283-29ae42ad0ee3, postOffice=PostOfficeImpl [server=HornetQServerImpl::serverUUID=e4a0ce9e-bd3f-11e3-a283-832a8d9e235e]]@21bfe46 targetConnector=ServerLocatorImpl [initialConnectors=[TransportConfiguration(name=netty, factory=org-hornetq-core-remoting-impl-netty-NettyConnectorFactory) ?port=5745&host=Manapakam], discoveryGroupConfiguration=null]]::ClusterConnectionImpl@617747968[nodeUUID=e4a0ce9e-bd3f-11e3-a283-832a8d9e235e, connector=TransportConfiguration(name=netty, factory=org-hornetq-core-remoting-impl-netty-NettyConnectorFactory) ?port=5645&host=Manapakam, address=jms, server=HornetQServerImpl::serverUUID=e4a0ce9e-bd3f-11e3-a283-832a8d9e235e])) [initialConnectors=[TransportConfiguration(name=netty, factory=org-hornetq-core-remoting-impl-netty-NettyConnectorFactory) ?port=5745&host=Manapakam], discoveryGroupConfiguration=null]] is connected
12:03:56,113 INFO [org.hornetq.core.server] (Thread-14 (HornetQ-server-HornetQServerImpl::serverUUID=e4a0ce9d-bd3f-11e3-a283-29ae42ad0ee3-931987561)) HQ221027: Bridge ClusterConnectionBridge@76c1b17 [name=sf.my-cluster.e4a0ce9e-bd3f-11e3-a283-832a8d9e235e, queue=QueueImpl[name=sf.my-cluster.e4a0ce9e-bd3f-11e3-a283-832a8d9e235e, postOffice=PostOfficeImpl [server=HornetQServerImpl::serverUUID=e4a0ce9d-bd3f-11e3-a283-29ae42ad0ee3]]@4a6686cf targetConnector=ServerLocatorImpl (identity=(Cluster-connection-bridge::ClusterConnectionBridge@76c1b17 [name=sf.my-cluster.e4a0ce9e-bd3f-11e3-a283-832a8d9e235e, queue=QueueImpl[name=sf.my-cluster.e4a0ce9e-bd3f-11e3-a283-832a8d9e235e, postOffice=PostOfficeImpl [server=HornetQServerImpl::serverUUID=e4a0ce9d-bd3f-11e3-a283-29ae42ad0ee3]]@4a6686cf targetConnector=ServerLocatorImpl [initialConnectors=[TransportConfiguration(name=netty, factory=org-hornetq-core-remoting-impl-netty-NettyConnectorFactory) ?port=5645&host=Manapakam], discoveryGroupConfiguration=null]]::ClusterConnectionImpl@864824009[nodeUUID=e4a0ce9d-bd3f-11e3-a283-29ae42ad0ee3, connector=TransportConfiguration(name=netty, factory=org-hornetq-core-remoting-impl-netty-NettyConnectorFactory) ?port=5745&host=Manapakam, address=jms, server=HornetQServerImpl::serverUUID=e4a0ce9d-bd3f-11e3-a283-29ae42ad0ee3])) [initialConnectors=[TransportConfiguration(name=netty, factory=org-hornetq-core-remoting-impl-netty-NettyConnectorFactory) ?port=5645&host=Manapakam], discoveryGroupConfiguration=null]] is connected
-
3. Re: Cannot find messages after failover in Colocated symmetrical cluster
jbertram Apr 6, 2014 6:18 PM (in response to vijay.balasubramanian) 1 of 1 people found this helpful
1 of 1 people found this helpfulI have redistribution turned off as i wanted one EAP1 to serve all client requests. If EAP1 fails there is an external mechanism to direct traffic to EAP2.
As long as all your clients (both consumers and producers) are connected to "EAP1" while it is alive then you can turn on redistribution and it won't cause any messages to go to "EAP2."
However, based on your description here it sounds to me like you don't actually need a colocated topology. The whole idea behind a colocated topology is that all the physical servers are processing messages concurrently. In your environment you you don't appear to want that. You want EAP1 to handle all the messages and then if EAP1 fails you want EAP2 to handle all the messages. This lends itself more to the classic master/slave topology that HornetQ supports via live/backup server pairs.
I'm curious about what "external mechanism" you're using to direct traffic to EAP2 when EAP1 fails.
Expectation is that any messages that were left unconsumed in EAP1 should be available in EAP2 for consuming.
Since you've turned off redistribution then your expectation here is not valid.
-
4. Re: Cannot find messages after failover in Colocated symmetrical cluster
vijay.balasubramanian Apr 7, 2014 12:59 PM (in response to jbertram)
Thanks for your response Jason.
The whole idea behind a colocated topology is that all the physical servers are processing messages concurrently.
OK. I did not catch this before. Thanks for clarifying this.
As long as all your clients (both consumers and producers) are connected to "EAP1" while it is alive then you can turn on redistribution and it won't cause any messages to go to "EAP2."
I turned on redistribution and sent 5000 msgs to EAP1, 2500 ended up in EAP1 and other 2500 in EAP2.
When i killed EAP1, and consumed msgs in EAP2 only 2500 msgs (ones that ended up in EAP2) were found. Other 2500 messages that ended by in EAP1 were NOT found. I expected the
backup HQ server in EAP2 to pull the 2500 from journal 1.
I'm curious about what "external mechanism" you're using to direct traffic to EAP2 when EAP1 fails.
Using external loadbalancer Netscaler.
This lends itself more to the classic master/slave topology that HornetQ supports via live/backup server pairs.
I had other problems with straight live/backup pairs. Client application is a web application that produces and consumes messages. The same web app is hosted in both EAP1 and EAP2 where the live and backup HornetQ servers are running respectively. I guess this is the problem.
As EAP2 is in backup mode initially, local connection factories are not available so the application could not be enabled and be ready to serve upon failover.
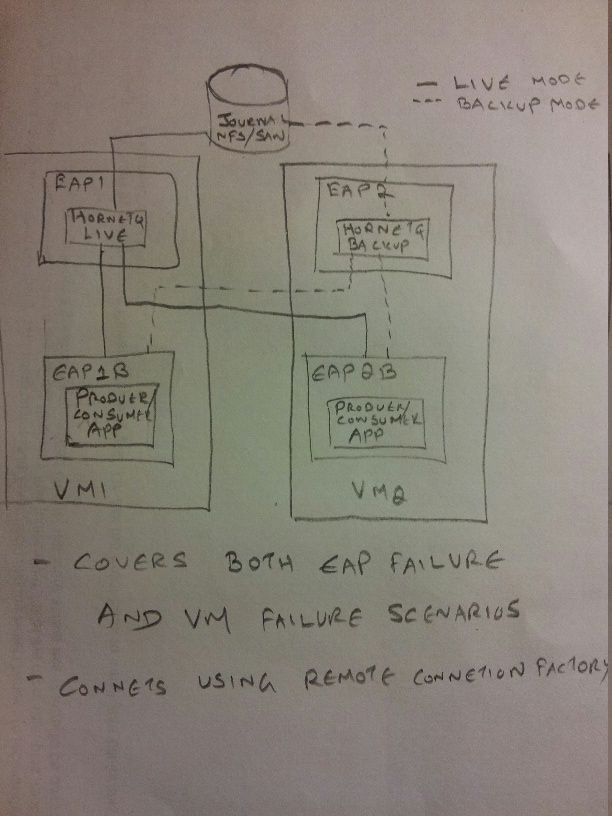
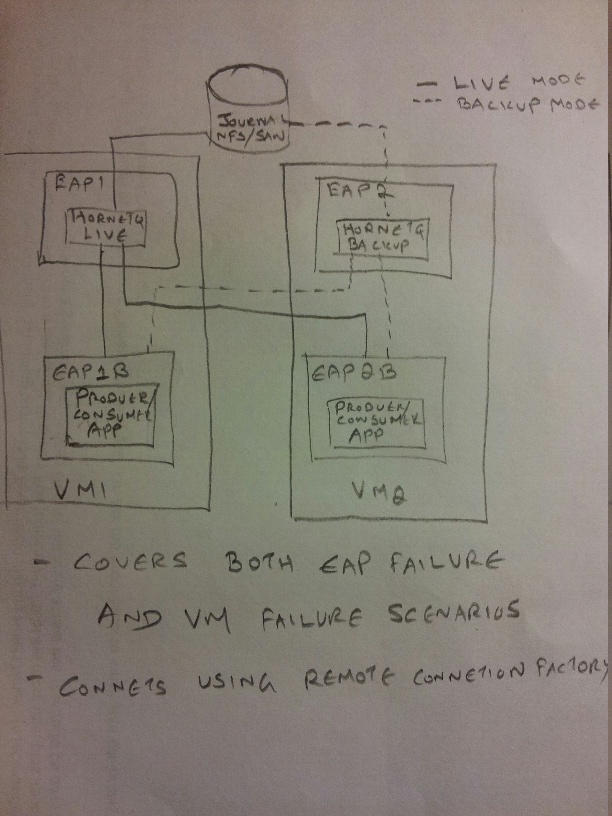
I am wondering if you are suggesting to use the topology shown below for high availability.
Additionally, I can also have a 2nd EAP server (or more) using the same live -backup EAP HornetQ pair.
Thanks.
-
5. Re: Cannot find messages after failover in Colocated symmetrical cluster
jbertram Apr 7, 2014 11:19 AM (in response to vijay.balasubramanian)
Using external loadbalancer Netscaler.
I see. So you don't have remote HornetQ clients. You just have remote web clients, and the HornetQ clients are all local (i.e. the web application).
I had other problems with straight live/backup pairs. Client application is a web application that produces and consumes messages. The same web app is hosted in both EAP1 and EAP2 where the live and backup HornetQ servers are running respectively. I guess this is the problem.
As EAP2 is in backup mode initially, local connection factories are not available so the application could not be enabled and be ready to serve upon failover.
There are a couple of ways you can make this work:
- Write the application so that it will retry in the event that its server is a backup. When the backup becomes live then the application will operate normally.
- Have the application on the backup actually connect to the remote live server and when the live server fails it will fail-over to itself.
- Separate the messaging server from the application server (i.e. the picture you attached).
-
6. Re: Cannot find messages after failover in Colocated symmetrical cluster
vijay.balasubramanian Apr 7, 2014 1:10 PM (in response to jbertram)
Thanks for your help Justin. I will take a look at using the classic live-backup.
I just want to understand the following:
For the "Colocated live-backup shared store" scenario you said:
As long as all your clients (both consumers and producers) are connected to "EAP1" while it is alive then you can turn on redistribution and it won't cause any messages to go to "EAP2."
I turned on redistribution and sent 5000 msgs to EAP1, 2500 ended up in EAP1 and other 2500 in EAP2.
When i killed EAP1, and consumed msgs in EAP2 (thru web app hosted in EAP2) only 2500 msgs (ones that ended up in EAP2) were found. Other 2500 messages that ended by in EAP1 were NOT found. I expected the backup HQ server in EAP2 to pull the 2500 from journal 1 also. Please help me understand. Once again.. Thanks, your feedback.
-
7. Re: Cannot find messages after failover in Colocated symmetrical cluster
jbertram Apr 7, 2014 3:56 PM (in response to vijay.balasubramanian)
I turned on redistribution and sent 5000 msgs to EAP1, 2500 ended up in EAP1 and other 2500 in EAP2.
- Did you ensure that all messaging clients were connected only to EAP1 (i.e. no messaging clients were connected to EAP2)?
- How exactly are you sending your JMS messages?
- How are you ensuring that your web requests are only going to EAP1?
When i killed EAP1, and consumed msgs in EAP2 (thru web app hosted in EAP2) only 2500 msgs (ones that ended up in EAP2) were found. Other 2500 messages that ended by in EAP1 were NOT found.
- How did you kill EAP1?
- Can you confirm that the colocated backup on EAP2 became active?
-
8. Re: Cannot find messages after failover in Colocated symmetrical cluster
vijay.balasubramanian Apr 8, 2014 1:41 PM (in response to jbertram)
- Did you ensure that all messaging clients were connected only to EAP1 (i.e. no messaging clients were connected to EAP2)?
My message producer is a web servlet that is deployed in EAP1 and used localConnectionFactory to produce 5000 messages
How exactly are you sending your JMS messages?
Throgh this servlet
@WebServlet("/test")
@SuppressWarnings("serial")
public class HornetQProducerServlet extends HttpServlet {
private static final Logger logger = LoggerFactory
.getLogger(HornetQProducerServlet.class);
@Resource(mappedName = "java:/ConnectionFactory")private ConnectionFactory connectionFactory;
@Resource(mappedName = "java:jboss/exported/jms/queue/validOrderQueue") private Queue queue;
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
Session session = null;
Connection connection = null;
try {
connection = connectionFactory.createConnection();
session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE);
MessageProducer producer = session.createProducer(queue);
connection.start();
for (int i = 0; i < 5000; i++) {
TextMessage message = session.createTextMessage();
String messageText = "test_" + i;
message.setText(messageText);
logger.info("Sending message: " + messageText);
producer.send(message);
}
} catch (Exception e) {
logger.error("Internal error", e);
resp.getWriter().println("ERROR");
return;
} finally {
if (session != null) {
try {
session.close();
} catch (JMSException e) {
logger.error("Error while closing session", e);
}
}
if (connection != null) {
try {
connection.close();
} catch (JMSException e) {
logger.error("Error while closing connection", e);
}
}
}
resp.getWriter().println("OK");
}
}
How are you ensuring that your web requests are only going to EAP1?
Using localConnectionFactory
When i killed EAP1, and consumed msgs in EAP2 (thru web app hosted in EAP2) only 2500 msgs (ones that ended up in EAP2) were found. Other 2500 messages that ended by in EAP1 were NOT found.
How did you kill EAP1?
CTRL+C on the EAP1 console terminal
Can you confirm that the colocated backup on EAP2 became active?
These are the logs i see in EAP2 after EAP1 is killed
10:49:30,779 WARN [org.hornetq.core.client] (Thread-3 (HornetQ-client-global-threads-477866477)) HQ212037: Connection failure has been detected: HQ119015: The connection was disconnected because of server shutdown [code=DISCONNECTED]
10:49:30,779 WARN [org.hornetq.core.client] (Thread-2 (HornetQ-client-global-threads-477866477)) HQ212037: Connection failure has been detected: HQ119015: The connection was disconnected because of server shutdown [code=DISCONNECTED]
10:49:30,779 WARN [org.hornetq.core.client] (Thread-6 (HornetQ-client-global-threads-477866477)) HQ212037: Connection failure has been detected: HQ119015: The connection was disconnected because of server shutdown [code=DISCONNECTED]
10:49:30,780 WARN [org.hornetq.core.server] (Thread-3 (HornetQ-client-global-threads-477866477)) HQ222095: Connection failed with failedOver=false: HornetQException[errorType=DISCONNECTED message=HQ119015: The connection was disconnected because of server shutdown]
at org.hornetq.core.client.impl.ClientSessionFactoryImpl$CloseRunnable.run(ClientSessionFactoryImpl.java:1631) [hornetq-core-client-2.3.12.Final-redhat-1.jar:2.3.12.Final-redhat-1]
at org.hornetq.utils.OrderedExecutorFactory$OrderedExecutor$1.run(OrderedExecutorFactory.java:107) [hornetq-core-client-2.3.12.Final-redhat-1.jar:2.3.12.Final-redhat-1]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) [rt.jar:1.7.0_51]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) [rt.jar:1.7.0_51]
at java.lang.Thread.run(Thread.java:744) [rt.jar:1.7.0_51]
10:49:30,784 INFO [org.hornetq.core.server] (Thread-0 (HornetQ-server-HornetQServerImpl::serverUUID=ae38bac6-be93-11e3-8ca1-dfe471be7879-406548642)) HQ221029: stopped bridge sf.my-cluster.ae3d75b7-be93-11e3-8ca1-dfe471be7879
10:49:31,373 INFO [org.hornetq.core.server] (HQ119000: Activation for server HornetQServerImpl::serverUUID=ae3d75b7-be93-11e3-8ca1-dfe471be7879) HQ221020: Started Netty Acceptor version 3.6.6.Final-redhat-1-fd3c6b7 127.0.0.1:5745 for CORE protocol
10:49:31,382 WARN [org.hornetq.core.client] (hornetq-discovery-group-thread-dg-group1) HQ212034: There are more than one servers on the network broadcasting the same node id. You will see this message exactly once (per node) if a node is restarted, in which case it can be safely ignored. But if it is logged continuously it means you really do have more than one node on the same network active concurrently with the same node id. This could occur if you have a backup node active at the same time as its live node. nodeID=ae3d75b7-be93-11e3-8ca1-dfe471be7879
10:49:31,384 INFO [org.hornetq.core.server] (HQ119000: Activation for server HornetQServerImpl::serverUUID=ae3d75b7-be93-11e3-8ca1-dfe471be7879) HQ221010: Backup Server is now live
10:49:31,402 INFO [org.hornetq.core.server] (Thread-15 (HornetQ-server-HornetQServerImpl::serverUUID=ae3d75b7-be93-11e3-8ca1-dfe471be7879-436446731)) HQ221027: Bridge ClusterConnectionBridge@23739ca6 [name=sf.my-cluster.ae38bac6-be93-11e3-8ca1-dfe471be7879, queue=QueueImpl[name=sf.my-cluster.ae38bac6-be93-11e3-8ca1-dfe471be7879, postOffice=PostOfficeImpl [server=HornetQServerImpl::serverUUID=ae3d75b7-be93-11e3-8ca1-dfe471be7879]]@7b316878 targetConnector=ServerLocatorImpl (identity=(Cluster-connection-bridge::ClusterConnectionBridge@23739ca6 [name=sf.my-cluster.ae38bac6-be93-11e3-8ca1-dfe471be7879, queue=QueueImpl[name=sf.my-cluster.ae38bac6-be93-11e3-8ca1-dfe471be7879, postOffice=PostOfficeImpl [server=HornetQServerImpl::serverUUID=ae3d75b7-be93-11e3-8ca1-dfe471be7879]]@7b316878 targetConnector=ServerLocatorImpl [initialConnectors=[TransportConfiguration(name=netty, factory=org-hornetq-core-remoting-impl-netty-NettyConnectorFactory) ?port=5645&host=Manapakam], discoveryGroupConfiguration=null]]::ClusterConnectionImpl@1663652447[nodeUUID=ae3d75b7-be93-11e3-8ca1-dfe471be7879, connector=TransportConfiguration(name=netty, factory=org-hornetq-core-remoting-impl-netty-NettyConnectorFactory) ?port=5745&host=Manapakam, address=jms, server=HornetQServerImpl::serverUUID=ae3d75b7-be93-11e3-8ca1-dfe471be7879])) [initialConnectors=[TransportConfiguration(name=netty, factory=org-hornetq-core-remoting-impl-netty-NettyConnectorFactory) ?port=5645&host=Manapakam], discoveryGroupConfiguration=null]] is connected
10:49:31,415 INFO [org.hornetq.core.server] (Thread-10 (HornetQ-server-HornetQServerImpl::serverUUID=ae38bac6-be93-11e3-8ca1-dfe471be7879-406548642)) HQ221027: Bridge ClusterConnectionBridge@442f1ffa [name=sf.my-cluster.ae3d75b7-be93-11e3-8ca1-dfe471be7879, queue=QueueImpl[name=sf.my-cluster.ae3d75b7-be93-11e3-8ca1-dfe471be7879, postOffice=PostOfficeImpl [server=HornetQServerImpl::serverUUID=ae38bac6-be93-11e3-8ca1-dfe471be7879]]@7add8e2e targetConnector=ServerLocatorImpl (identity=(Cluster-connection-bridge::ClusterConnectionBridge@442f1ffa [name=sf.my-cluster.ae3d75b7-be93-11e3-8ca1-dfe471be7879, queue=QueueImpl[name=sf.my-cluster.ae3d75b7-be93-11e3-8ca1-dfe471be7879, postOffice=PostOfficeImpl [server=HornetQServerImpl::serverUUID=ae38bac6-be93-11e3-8ca1-dfe471be7879]]@7add8e2e targetConnector=ServerLocatorImpl [initialConnectors=[TransportConfiguration(name=netty, factory=org-hornetq-core-remoting-impl-netty-NettyConnectorFactory) ?port=5745&host=Manapakam], discoveryGroupConfiguration=null]]::ClusterConnectionImpl@1558770156[nodeUUID=ae38bac6-be93-11e3-8ca1-dfe471be7879, connector=TransportConfiguration(name=netty, factory=org-hornetq-core-remoting-impl-netty-NettyConnectorFactory) ?port=5645&host=Manapakam, address=jms, server=HornetQServerImpl::serverUUID=ae38bac6-be93-11e3-8ca1-dfe471be7879])) [initialConnectors=[TransportConfiguration(name=netty, factory=org-hornetq-core-remoting-impl-netty-NettyConnectorFactory) ?port=5745&host=Manapakam], discoveryGroupConfiguration=null]] is connected
My consumer which is also a webapp is deployed on EAP2.
Thanks again for your help.
-
9. Re: Cannot find messages after failover in Colocated symmetrical cluster
jbertram Apr 8, 2014 1:35 PM (in response to vijay.balasubramanian)
Before we go further I want to ask what your intended topology actually is. Are you going to use a colocated topology or not? If not, the discussion at this point seems moot. If so, why would you use a colocated topology when it appears at odds with your functional requirements.
My message producer is a web servlet that is deployed in EAP1 and used localConnectionFactory to produce 5000 messages
I'm not terribly concerned with producers here. I'm concerned with the consumers. I assume consumers are part of your application. I also assume that your application is deployed on both EAP1 and EAP2. Can you confirm this? If so, please explain the function the consumers play in your application and whether or not they would be active on EAP2 all the time.
How are you ensuring that your web requests are only going to EAP1?
Using localConnectionFactory
Here I asked about your web requests and you gave me an answer about your JMS messages.
-
10. Re: Cannot find messages after failover in Colocated symmetrical cluster
vijay.balasubramanian Apr 8, 2014 2:14 PM (in response to jbertram)
Justin,
Yes, i am talking about colocated topology. Sorry, i did not clearly state this.
I'm not terribly concerned with producers here. I'm concerned with the consumers. I assume consumers are part of your application. I also assume that your application is deployed on both EAP1 and EAP2. Can you confirm this? If so, please explain the function the consumers play in your application and whether or not they would be active on EAP2 all the time.
You are correct, in production the same application (consumer & producer) will be deployed in both EAP1 and EAP2, they will both be alive at any time.
- Messages are read from a socket, validated and put in Queue by the producer. (In my test case i am just creating test messages and queueing them.)
- Consumer picks the messages from the Queue and performs business logic and produces its results
Mainly i am looking to see if messages survive and procssed by the other EAP if any one of the EAP's fail.
How are you ensuring that your web requests are only going to EAP1?
Triggered through URL requests on the browser to EAP1's IP address and port.
why would you use a colocated topology when it appears at odds with your functional requirements
Deployment architecture is still evolving, company wants to ensure they use the efficient option, so i am looking in to both colocated live-backup and classic live-backup topologies.
Thanks again for your time.
Vijay
-
11. Re: Cannot find messages after failover in Colocated symmetrical cluster
jbertram Apr 8, 2014 2:43 PM (in response to vijay.balasubramanian)
As I understand it, the problem you're facing with colocated topology is that:
- If redistribution is disabled then messages get trapped on the colocated backup server when fail-over occurs. There's no way around this.
- If redistribution is enabled then messages go to EAP2 instead of staying EAP1. I believe there is a way around this but it requires that all clients, both consumers and producers, only connect to EAP1 while EAP1 is active otherwise messages could be redistributed to EAP2. I explained this in previous comments saying, "As long as all your clients (both consumers and producers) are connected to 'EAP1' while it is alive then you can turn on redistribution and it won't cause any messages to go to 'EAP2.'" However, it appears that you are unable to fulfill this requirement since the application in question will be deployed and active on both nodes.
Based on this I again conclude that a colocated topology doesn't fit your architecture. You either need to abandon using a colocated topology or change your architecture.
We've covered this same ground twice now. What more needs to be said?
-
12. Re: Cannot find messages after failover in Colocated symmetrical cluster
vijay.balasubramanian Apr 8, 2014 4:32 PM (in response to jbertram)
OK. Thanks.
Can you please explain, what is the role of backup HQ server in colocated live-backup shared store mode?
I'm referring to Chapter 38.1.1 Colocated Live and Backup in symmetrical cluster material in the following doc
Chapter 38. HornetQ and Application Server Cluster Configuration
-
13. Re: Cannot find messages after failover in Colocated symmetrical cluster
jbertram Apr 8, 2014 4:37 PM (in response to vijay.balasubramanian)
The role of a backup server is to enable HA functionality in the case that the corresponding live server fails.
-
14. Re: Cannot find messages after failover in Colocated symmetrical cluster
vijay.balasubramanian Apr 8, 2014 10:29 PM (in response to jbertram)
In colocated mode, i am guessing if the live HQ server fails all the unconsumed messages inflight should be available in backup HQ server.
How to get hold of the leftover messages through the backup HQ server, as it does not have connection factories to connect?
Really appreciate your answers. Thanks.