This content has been marked as final.
Show 5 replies
-
1. Re: Delimited Flat Files | Performance observations
shawkins Jan 2, 2015 9:36 AM (in response to shiveeta.mattoo)
> We observe a performance degradation for File Sources while accessing the File data using Teiid VDB vs a normal File read in our application.
A performance degradation relative to what?
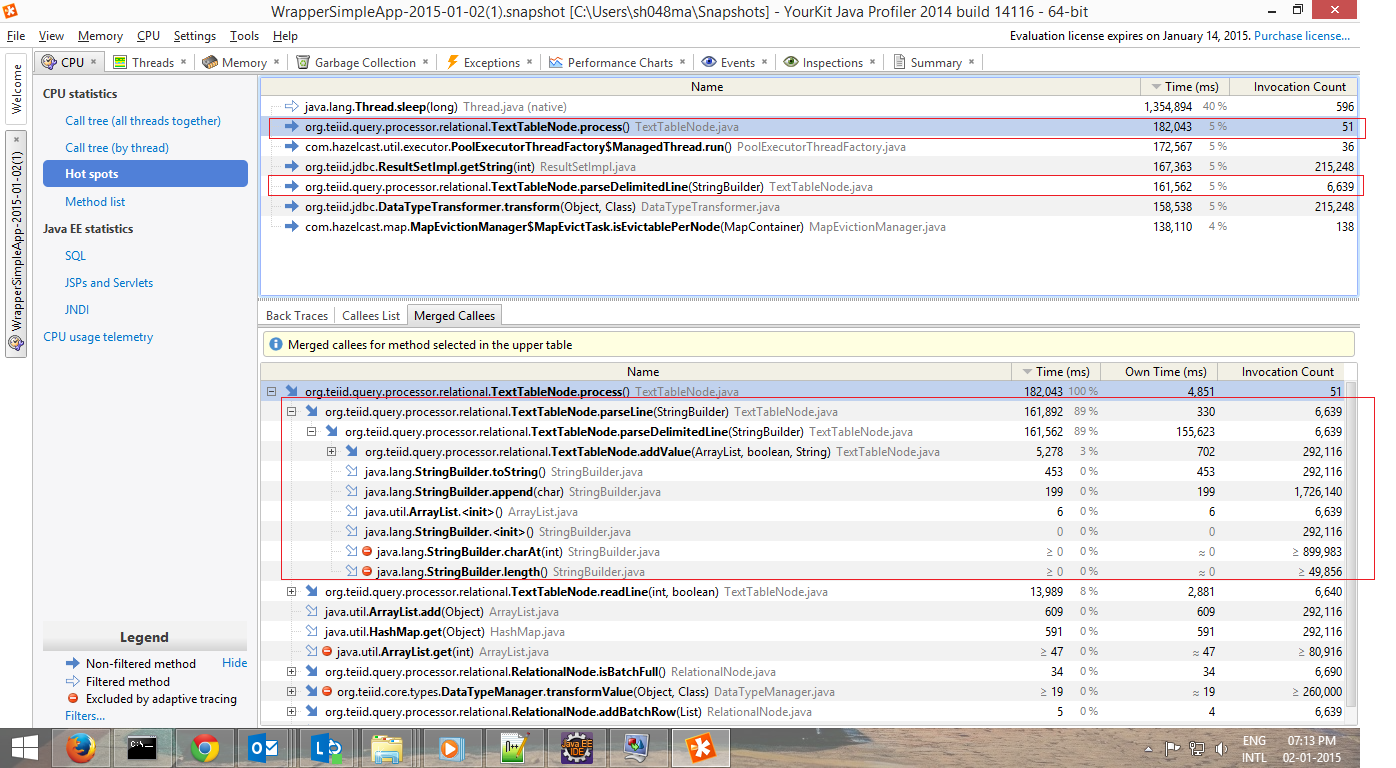
> For the delimited file source, I profiled the application and the major bottleneck reported is at TextTableNode.process method, specifically - TexTableNode.parseDelimitedLine.
It should be expected that delimited is more expensive to process than fixed as full scans of the line/characters are required. Using the stringbuilder does add overhead, but simplifies handling of escapes. You can submit a patch/log an issue if you want to improve what's there.
-
2. Re: Delimited Flat Files | Performance observations
shiveeta.mattoo Jan 20, 2015 4:26 AM (in response to shawkins)
Thanks Steven,
The performance degradation was in comparison to direct File read from our application which did not include the virtualization layer.
On further testing, the performance degradation was observed for Fixed width files as well.
I am working on submitting a patch for improving the performance improvement for Flat File read.
-
3. Re: Delimited Flat Files | Performance observations
shiveeta.mattoo Feb 21, 2015 7:33 AM (in response to shiveeta.mattoo)
I made following changes locally to readLine and parseDelimitedLine to fix the performance bottlenecks reported by the profiler.
- Instead of BufferedReader, did manual buffering of the lines as suggested here - http://www.kegel.com/java/wp-javaio.html
- Enhanced parseDelimited line to reduce the number of String objects that were being created.
Based on prelim readings, these changes gave a performance improvement of nearly 50sec for a 446MB file (5 million records).
However the results are not yet satisfactory with respect to readings of file read without a virtualization layer, where in the performance is almost 3 times slower compared to a normal read. For a 48M record file, (~ 3 GB), the time taken is almost 1.5 hours.
Fresh profiling results report bottlenecks at BufferedManagerImpl and BufferedFrontedFileStoreCache.get.
Although this is common framework code for any file source, any pointers, if anything special done for file source, which might cause these to be reported as Hot spots.
Any pointers would be helpful. Thank you.
-
4. Re: Delimited Flat Files | Performance observations
shawkins Feb 21, 2015 7:48 AM (in response to shiveeta.mattoo)
> Based on prelim readings, these changes gave a performance improvement of nearly 50sec for a 446MB file (5 million records).
That's encouraging.
> Fresh profiling results report bottlenecks at BufferedManagerImpl and BufferedFrontedFileStoreCache.get.
That would have more to do with processing above the texttablenode, such that the results are being buffered for further processing rather than just streamed. What does your user query look like?
-
5. Re: Delimited Flat Files | Performance observations
shawkins Mar 12, 2015 11:53 AM (in response to shawkins)
Is there any code that you would want to share for this?