Availability
I was thinking about alerting and we had just been talking about alerting on availability changes, like in RHQ. And then I realized that we hadn't really even thought about what availability might look like in Hawkular. There are fundamental differences between Hawkular and RHQ, as well as definite pros and cons of how we did things in the past. After a short while it became clear that things would not really carry over from RHQ. So I started some less public discussions around availability for Hawkular. I've tried to consolidate those conversations and come up with something for more public discussion. Thanks to Heiko, Lukas and Mazz for their input thus far.
This is a rough proposal for how Availability could work in Hawkular. It's totally flexible! Please COMMENT AND ASK QUESTIONS!
Availability in RHQ
RHQ had the following pros and cons with respect to Availability:
Pros:
- Scheduled checks performed by an external agent.
The external agent gave us a way to proactively detect avail changes. The schedules gave us predictable intervals for performing the tests and detecting changes.
Cons:
- Performance
- Timeliness
- Untargeted
Our agent used a lot of cycles repeatedly testing availability. In response we were forced to check availability infrequently. This sometimes led to slow reporting or complete misses of "cycled" avail changes. Furthermore, we tracked avail for every resource. That is a lot of wasted work when users are typically interested in a few, critical resources, and often only for alerting purposes.
Availability in Hawkular
Part 1: Don't Require Availability Reporting
Availability is basically a metric. Primarily UP|DOWN. The fundamental difference between avail and other metrics is that a down resource can't report itself down. That needs to come from an external entity. But it can report itself up (like a ping). In fact, it may be able to report its upTime (a more informative ping). But basically, it could be that it doesn't care to report avail at all, and is happy reporting its other metrics (which is another sign of live-ness), or possibly happy reporting none at all.
We need to provide a mechanism to report availability, but we don't need to force it to be used. Let the feed writers decide what is important for their product.
Part 2: Allow for External Availability Reporting
Because a resource can't report itself down, it's important to allow an external source to report down on any resource. This should be easy, it would just be sending a metric report like any other, as long as it has the resource id.
Part 3: Provide a Light External Agent for Reporting Availability
I don't have the specifics here but the main idea is that we have something that can be deployed that can perform frequent, "light" avail checks for specific resources that have been configured. I'm talking about pid detection, url pings (like what the netservices plugin does in RHQ), generic ways to quickly check avail on historically the most important resources, namely servers (processes) and apps. We could provide various, generic mechanisms that require only some seed data (a pid) or simple configuration. The frequency of checks could be fairly high to catch down situations quickly.
An Example:
Let's take a theoretical EAP feed. This feed can not report the EAP server itself DOWN but it can report UP/DOWN avail for any of it's descendants, as it deems fit or has been configured to do. And possibly quite efficiently if somehow tied in with, say, lifecycle functions for its deployments. Perhaps the EAP feed could optionally "register" with the External Agent (if it is available), thus setting up perhaps some ability to watch the process. Or, maybe the External Agent has some level of process discovery, like in RHQ.
So, in this model we have an external agent monitoring the server and the embedded EAP feed doing the rest.
Part 4: Alerting
Alerting (status-based):
So, given that availability is being reported as a sort of metric, it should be possible to perform simple alerting of avail status changes, like GOES_DOWN. And, also given some sort of alerting-side trickery, duration alerting like STAYS_DOWN X Minutes.
Alerting (activity-based)
So what if the external agent is not deployed. In that case a down avail will not be reported, instead, only a series of up avail (like pings) may be reported and then it will stop. There will begin a period of inactivity for the resource. It should be possible to alert on a period of inactivity (no avail metrics received).
Part 5: Persistence
Unlike RHQ and the RDB, using Hawk-Metrics (Cassandra) we want to avoid updates and read-then-write logic. Instead, the general approach is to just write, write, write. So,for avail the prior run-length-encoded storage model will likely be replaced with simple time-availType data points. So, quite possible to have UP, UP, UP... Not reporting avail for every resource will reduce the amount of unnecessary writes. When fetched for a time interval, we can aggregate into a RLE form as desired, by combining consecutive data points of the same avail type.
As in RHQ, if a resource is set to DOWN, its descendents should likely also be set to DOWN.
Other: Caching
If we can implement some in-memory caching we may be able to do some more interesting things. For example, if we cache the current avail we may be able to limit writes to just changes in avail. Maybe more interesting, and not something we do in RHQ, if we have the resource hierarchy cached we may be able to efficiently do the following: when receiving an UP avail for a resource then we can set it's ancestry to UP. In this way, a single UP from a leaf resource can implicitly set avail for several resources higher in the ancestry tree. This has the potential to save a lot of cycles on the feed side. But to do it efficiently we'd likely need both the hierarchy cached as well as the current avail.
Other: Proxy Metric
It may be useful to allow a different metric to "double" as an avail reporter. If metric X is being reported at a decent interval, it could possibly be flagged as an avail ping, basically saying UP in addition to whatever metric value it carries.
Other: Inactivity
For those involved in the avail discussions you'll note we had discussed the idea of GREEN/YELLOW/RED status as periods of inactivity for a resource grew larger. I have decided to get away from this as something we'd ubiquitously track. The amount of work potentially involved in maintaining this as compared to its perceived usefulness didn't seem favorable. Instead, as you saw above, I basically redefined inactivity solely as a concept for alerting, and solely as the lack of an avail metric. This, I think, distills the prior idea to its essence, and should be doable in a much more efficient way.
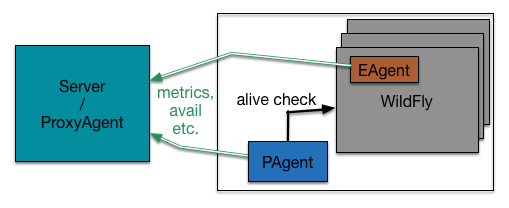
Diagram:
I stole this from Heiko, it's basically the architecture for the example and discussion above. PAgent would be the light, external agent that performed DOWN avail reporting for the EAP server as a whole, for example. EAgent would be a feed embedded in EAP that reported server-level and descendant metrics and avail. The Server is basically where the avail would be processed/persisted/alerted on.
Summary:
So, there are some fundamental changes in approach here. And some questions to answer. Maybe most importantly, what do people think about not forcing/providing explicit availability on all (or probably the majority) of resources?
Any and all feedback appreciated.