JBoss EAP 6.1; standalone mode; pbcast.NAKACK; dropped message from non-member...
Hello, Friends,
I have recently installed JBoss EAP 6.1, after having been away from JBoss for several years, and I was quite surprised by how much things have changed!
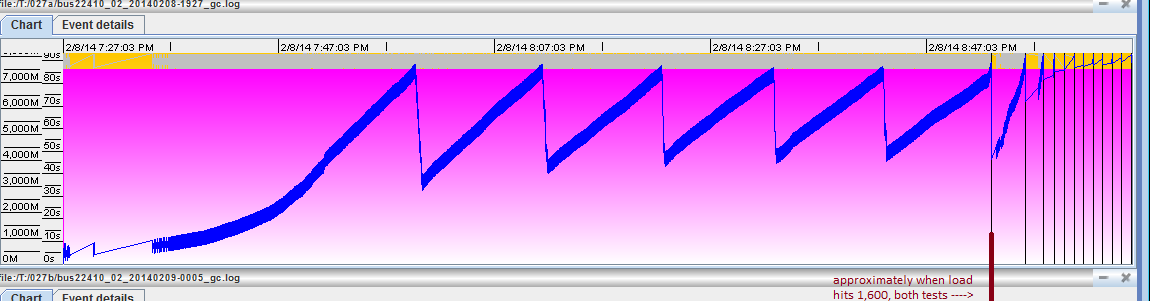
I'm having trouble resolving a problem during stress tests under high load. I have configured four standalone server instances (for reasons I won't go into now, domain mode was not an option), distributed over two app servers (so, a 2x2 configuration). During stress tests, all is well until a certain load level, then all four servers begin to GC out of control, and eventually crash. Some sample messages from the four servers:
Node 10_1
20:57:39,787 WARN [org.jgroups.protocols.pbcast.NAKACK] (OOB-20,shared=udp) (requester=node11_2/web, local_addr=node10_1/web) message node10_1/web::3006060 not found in retransmission table of node10_1/web:
[3006048 (3006091) (size=1180, missing=1, highest stability=3004910)]
20:57:39,837 WARN [org.jgroups.protocols.pbcast.NAKACK] (OOB-17,shared=udp) (requester=node11_1/web, local_addr=node10_1/web) message node10_1/web::3006060 not found in retransmission table of node10_1/web:
[3006048 (3006143) (size=1233, missing=0, highest stability=3004910)]
20:57:39,734 WARN [org.jgroups.protocols.pbcast.NAKACK] (OOB-18,shared=udp) (requester=node10_2/web, local_addr=node10_1/web) message node10_1/web::3006060 not found in retransmission table of node10_1/web:
[3006048 (3006079) (size=1168, missing=1, highest stability=3004910)]
20:59:32,400 WARN [org.jgroups.protocols.FD] (OOB-16,shared=udp) I was suspected by node11_2/web; ignoring the SUSPECT message and sending back a HEARTBEAT_ACK
20:59:36,601 WARN [org.jgroups.protocols.pbcast.GMS] (Incoming-23,shared=udp) node10_1/web: not member of view [node10_2/web|4]; discarding it
20:59:39,829 WARN [org.jboss.as.clustering.web.infinispan] (Incoming-25,shared=udp) JBAS010325: Possible concurrency problem: Replicated version id 40 is less than or equal to in-memory version for session essv+YTl68G+8g5pBfel+tqV
20:59:39,830 WARN [org.jboss.as.clustering.web.infinispan] (Incoming-25,shared=udp) JBAS010325: Possible concurrency problem: Replicated version id 41 is less than or equal to in-memory version for session essv+YTl68G+8g5pBfel+tqV
Node 10_2
20:59:27,904 INFO [org.jboss.as.clustering] (VERIFY_SUSPECT.TimerThread,web,node10_2/web) JBAS010232: Suspected member: node10_1/web
20:59:28,021 INFO [org.jboss.as.clustering] (Incoming-42,shared=udp) JBAS010225: New cluster view for partition web (id: 4, delta: -1, merge: false) : [node10_2/web, node11_1/web, node11_2/web]
20:59:28,023 INFO [org.infinispan.remoting.transport.jgroups.JGroupsTransport] (Incoming-42,shared=udp) ISPN000094: Received new cluster view: [node10_2/web|4] [node10_2/web, node11_1/web, node11_2/web]
20:59:31,705 WARN [org.jgroups.protocols.pbcast.NAKACK] (Incoming-16,shared=udp) [JGRP00011] node10_2/web: dropped message 3,024,568 from non-member node10_1/web (view=[node10_2/web|4] [node10_2/web, node11_1/web, node11_2/web])
Node 11_1
20:59:27,828 INFO [org.jboss.as.clustering] (VERIFY_SUSPECT.TimerThread,web,node11_1/web) JBAS010232: Suspected member: node10_1/web
20:59:28,017 INFO [org.jboss.as.clustering] (Incoming-17,shared=udp) JBAS010226: New cluster view for partition web: 4 (org.jboss.as.clustering.impl.CoreGroupCommunicationService$GroupView@670f68f6 delta: -1, merge: false)
20:59:28,018 INFO [org.infinispan.remoting.transport.jgroups.JGroupsTransport] (Incoming-17,shared=udp) ISPN000094: Received new cluster view: [node10_2/web|4] [node10_2/web, node11_1/web, node11_2/web]
20:59:31,940 WARN [org.jgroups.protocols.pbcast.NAKACK] (Incoming-13,shared=udp) [JGRP00011] node11_1/web: dropped message 3,024,580 from non-member node10_1/web (view=[node10_2/web|4] [node10_2/web, node11_1/web, node11_2/web])
20:59:35,896 WARN [org.infinispan.loaders.file.FileCacheStore] (OOB-45,shared=udp) ISPN000163: FileCacheStore ignored an unexpected file admin in path /scratch/akuchara/AppServers/JBoss/JBoss6.1.0/jboss-eap-6.1/standalone/data/infinispan/web/default-host/dyn. The store path should be dedicated!
21:01:49,058 WARN [org.jgroups.protocols.FD] (OOB-82,shared=udp) I was suspected by node10_2/web; ignoring the SUSPECT message and sending back a HEARTBEAT_ACK
21:01:49,119 WARN [org.jgroups.protocols.pbcast.NAKACK] (Incoming-7,shared=udp) [JGRP00011] node11_1/web: dropped message 3,026,370 from non-member node10_1/web (view=[node10_2/web|4] [node10_2/web, node11_1/web, node11_2/web]) (received 1,804 identical messages from node10_1/web in the last 137,180 ms)
21:01:49,055 ERROR [nucleusNamespace.atg.dynamo.servlet.dafpipeline.VirtualContextRootInterceptor] (ajp-/10.152.221.80:8109-43) Could not forward request to context org.apache.catalina.core.ApplicationContextFacade@c6f651d: ClientAbortException: java.net.SocketException: Broken pipe
Node 11_2
20:59:27,938 INFO [org.jboss.as.clustering] (VERIFY_SUSPECT.TimerThread,web,node11_2/web) JBAS010232: Suspected member: node10_1/web
20:59:28,044 INFO [org.jboss.as.clustering] (Incoming-23,shared=udp) JBAS010226: New cluster view for partition web: 4 (org.jboss.as.clustering.impl.CoreGroupCommunicationService$GroupView@22d4c86a delta: -1, merge: false)
20:59:28,045 INFO [org.infinispan.remoting.transport.jgroups.JGroupsTransport] (Incoming-23,shared=udp) ISPN000094: Received new cluster view: [node10_2/web|4] [node10_2/web, node11_1/web, node11_2/web]
20:59:31,685 WARN [org.jgroups.protocols.pbcast.NAKACK] (Incoming-32,shared=udp) [JGRP00011] node11_2/web: dropped message 3,024,568 from non-member node10_1/web (view=[node10_2/web|4] [node10_2/web, node11_1/web, node11_2/web])
20:59:35,729 WARN [org.infinispan.loaders.file.FileCacheStore] (OOB-19,shared=udp) ISPN000163: FileCacheStore ignored an unexpected file admin in path /scratch/akuchara/AppServers/JBoss/JBoss6.1.0/jboss-eap-6.1/standalone/data/infinispan/web/default-host/dyn. The store path should be dedicated!
20:59:42,533 ERROR [org.apache.catalina.core.ContainerBase.[jboss.web].[default-host].[/crs].[default]] (ajp-/10.152.221.80:8209-255) JBWEB000236: Servlet.service() for servlet default threw exception: java.lang.IllegalStateException: JBAS018058: Session is already expired
As far as I know I have not specifically enabled session replication of my application, but it appears that some sort of replication is overwhelming my system, and udp messages are not getting delivered to the nodes. I have a general understanding of what's happening, but I'm not able to find a resolution. Can anyone provide a few pointers for this problem?
Thanks