SQL script doesn't get pushed down to Aster Teradata data source
ENV'NT
Aster Teradata cluster (ATC) <--> JBoss DV with Dev Studio & Teiid (JDV) <--> dbVisualizer (dbVis)
All of the above, anmely ATC, JDV and dbVis reside on different servers in different IP segments separated by Firewalls w/ appropriate ACL rules to allow traffic via port 31000 (dbVis -> JDV) and port 2406 (JDV -> ATC)
I'm not the DBA on ATC but I can ask the DBA Qs if I have to.
I have full ctrl of JDV and dbVis
SETUP
Aster Teradata is one of our data sources JDV connects to
A Teiid JDBC connection to ATC, along with a VBLayer and VDB have all been configured from Dev studio and work perfectly fine
Tested the JDV connection to Aster from dbVisualizer (dbVis) and can run simple queries (Select * from tbl LIMIT 10, select count(*) from tbl, etc)
PERFORMANCE TEST
When the following script runs from dbVis through a straight connection to Aster Teradata it takes a couple of mins
When the following script runs from dbVis via the JDV connection it takes about an hr or more.
DW is Aster's db schema
4 tbls are called in this script. They have the following sizes:
tbl1: 2.3 Billion rcds
tbl2: 4.2 Billion rcds
tbl3: 15 Million rcds
tbl4: 73,000 rcds
select f.fld1_dim_key, f.fld2_dim_key, f.fld3_dim_key,
f.fld8_FACT_KEY, f.fld7, f.fld9_dim_key,
f.fld10_dim_key, f.fld12_dim_key, f.fld11,
f.natural_key, a.fld13_DIM_KEY, a.fld14
from
DW.tbl1_fact f
left outer join
DW.tbl2_fact a
on f.natural_key = a.fld8_fact_nk and f.fld2_dim_key = a.fld2_dim_key
inner join DW.tbl3_dim b
on f.fld15_dim_key = b.fld16_dim_key
inner join DW.tbl4_dim d
on f.fld17_DIM_KEY = d.dt_dim_key
where
coalesce(a.fld4_key,'20130601') between '20130601' and '20131130'
and f.fld4_key between '20130601' and '20131130'
and f.fld5_DIM_KEY = 35768
and Cy_NMBR = 2013 and CM_NMBR = 8
and f.fld1_dim_key = 678
and b.fld6 = 'John Smith'
ORDER BY f.fld7, f.natural_key ;
TESTING conducted already to perf tune the above script:
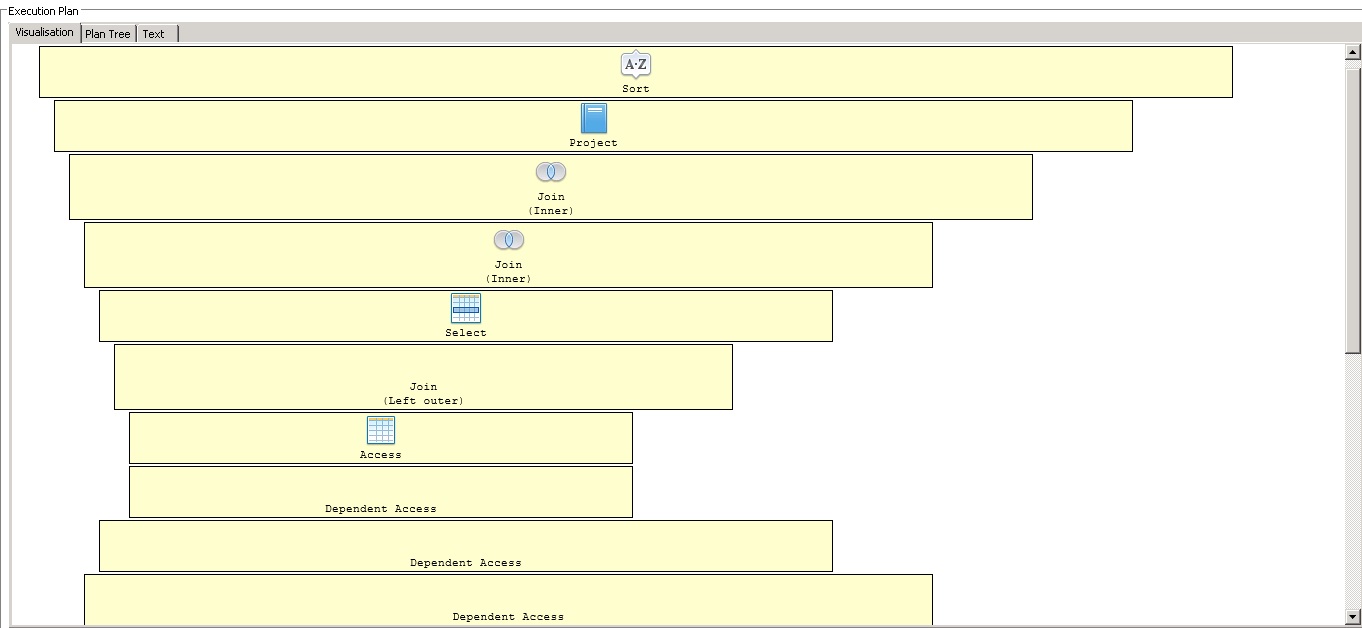
1. I was under the impression that such a script will get pushed down to ATC by default.
2. replaced the left outer join with an inner join (although the logic of the script changes) to chk any change in exec time. Result: run time dropped from an hr down to less than 100secs. Does that mean the translator has issues with the left outer join
OR
as Chapter 9. Translators says
| The Salesforce Connector executes SQL commands by “pushing down” the command to Salesforce whenever possible, based on the supported capabilities. Teiid will automatically provide additional database functionality when the Salesforce Connector does not explicitly provide support for a given SQL construct |
where Salesforce is ATC in this case.
3. Rewrote the script using a right outer join but no luck. It still takes quite a bit of time to complete.
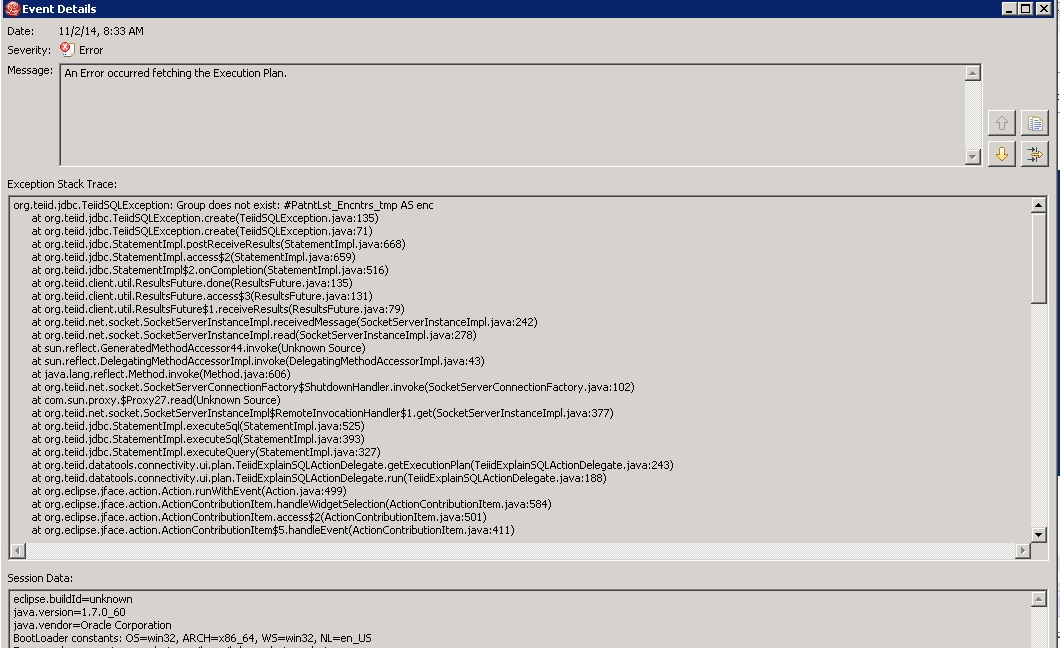
4. Per Redhat's engineer advice (worked with him in the past) I imported a physical model to a new data source and exposed it via a fresh standalone VDB and then run the script from dbVis against that VDB. I still got a long execution response, no change.
QUESTION:
I'm not an expert in JDV in any stretch of the imagination but I can follow advice and, most importantly, learn from it. How can I make this particular script run faster and what general development guidelines (any docs, URLs you can point me to? ) should I follow when I write scripts like that ? By the way, how does SQL push down work on Teiid ? I didn't import the indexes with the views (ATC's DBA exposed only views from his env'nt and that's understandable) I brought in from ATC when I created the data source in Dev Studio, is that a problem ?
This issue has been occupying my nights for quite a while so ANY advice is greatly appreciated.
Anything I'm forgetting to report please ask and I'll answer ASAP.
Thanks
Stavros K.