Further Integration of Teiid and Hadoop
Quick Introduction. I'm a long time listener first time caller. I worked for JBoss pre-acquistion, founded a project called POI which ported Microsoft's file formats to Java which I donated to Apache (poi.apache.org) and served briefly on the board of the Open Source Initiative. I also run a big data consultancy called Mammoth Data... I've used Teiid in the past, but haven't recently. Yet I do kind of see it as a potential solution to some of the kinds of problems that I encounter now.
While I understand the use cases for Something<----JDBC<---Teiid <--- Hive which already exists - I think there are other use cases that could be served by integrating Teiid in reverse. Meaning allowing Teiid to provide data to Hive and Spark. This would be similar to what others have done with Solr (Playing with Apache Hive and SOLR | Chimpler https://lucidworks.com/fusion/hadoop/) and Elasticsearch (Hadoop: Immediate Insight into Big Data | Elastic). The idea would be to reduce the burden of ETL on developers while using Spark, Hive, Hadoop, etc for the data processing, transform and analytics.
Concretely:
1. A Hive connector
2. A Spark connector
3. A Hive DDL generator based on the schema meta-model

One would then connect Hive to Teiid. generate the DDL for Hive and then you could directly query Teiid via Hive or SparkSQL.
To go further, integrate the cache into Hadoop (speaking of the ecosystem) and have it overflow to HDFS. Configure the "staleness" of the data through meta-data as opposed to load processes (ala PIG/Sqoop/Oozie). This would allow data to be distributed throughout the cluster potentially "ahead of time." -- Additionally the query engine could issue SparkQL thereby distributing the processing.
The goal would be to avoid writing ETL or using SQOOP but leave my data in place yet take advantage of the distributed platform through a combination of caching and distribution.
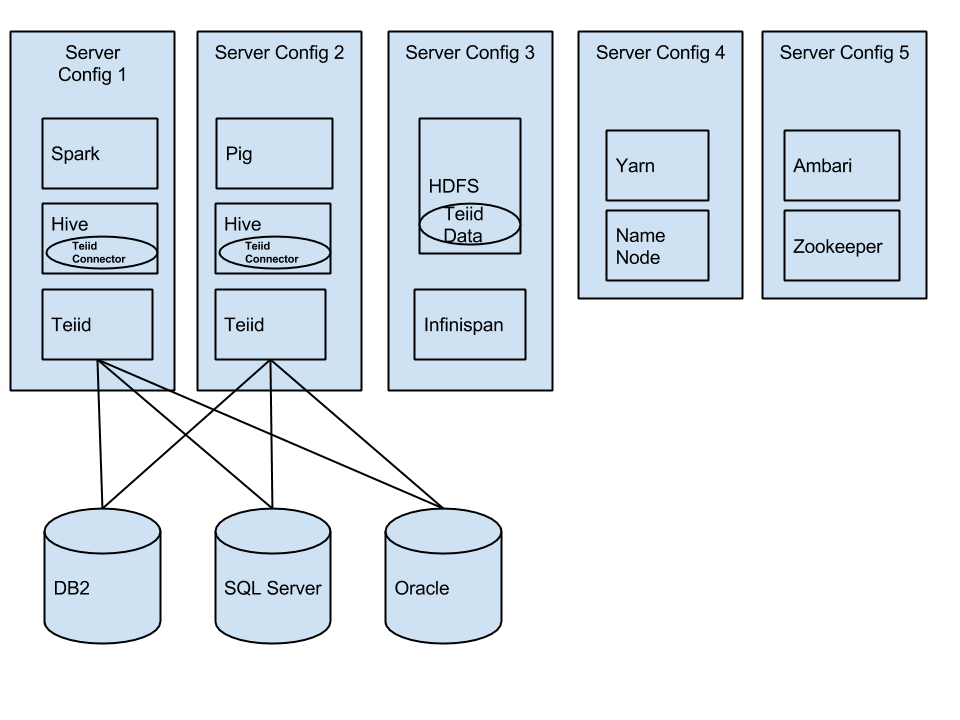
Has anyone thought of doing something like this? Why? Why not?