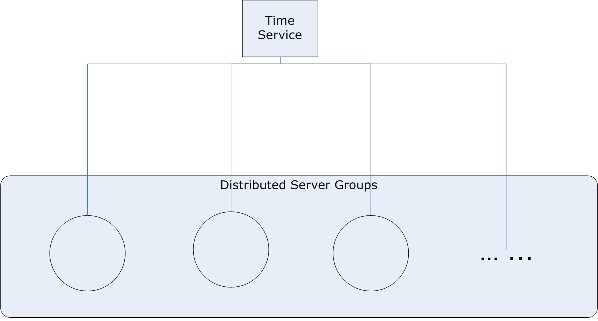
OS will provid your the time support for you automatically, so you already used to that. But how about you go to distrubuted computing senarios, which means multiple servers works for large chunk requests, can you trust each machine time? The answer is "no", as time for each machine depends on the electronic power so some may go faster some may go slower. So that may introduct some expected behaviors if you don't handled that.
So from machine perspective the time synchronization come to stage, for example: Windows Time Service.
But how about from software perspective ? The answer is "centralized or distributed Time service".
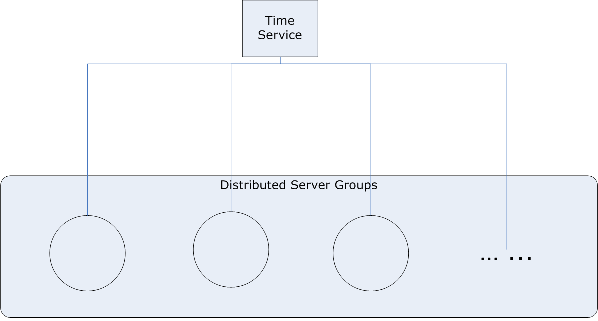
The chanllenges will be:
* Network Communication Latency
* The scale level you want to achieve (Seconds, Milliseconds, Nanoseconds, etc)
* Still need machine time service coordination because how about you want to do geographical distribution
* SPOF invovled ? Maybe, but you can overcome by some other design.