All People > andy.song > Twins Father > 2010 >
December
2010
More often in the large system you may need transfer the byte array - which may serialized stream or read from binary file or socket - via the network. And normally most of system design will took string as the protocol rather than byte array. So here you may need some way safely and efficiently transfer byte arrary to string and vice versa.
So today I will post one toolbox for you resolving that particular problem.
1. ByteArray to HexString
static final String HEXES = "0123456789ABCDEF";
public static String getHex(byte[] raw) {
if (raw == null) {
return null;
}
final StringBuilder hex = new StringBuilder(2 * raw.length);
for (final byte b : raw) {
hex.append(HEXES.charAt((b & 0xF0) >> 4))
.append(HEXES.charAt((b & 0x0F)));
}
return hex.toString();
}
2. HexString to ByteArray
public static byte[] hexStringToBytes(String hexString) {
if (hexString == null || hexString.equals("")) {
return null;
}
hexString = hexString.toUpperCase();
int length = hexString.length() / 2;
char[] hexChars = hexString.toCharArray();
byte[] d = new byte[length];
for (int i = 0; i < length; i++) {
int pos = i * 2;
d[i] = (byte) (charToByte(hexChars[pos]) << 4 | charToByte(hexChars[pos + 1]));
}
return d;
}
private static byte charToByte(char c) {
return (byte) "0123456789ABCDEF".indexOf(c);
}
3. Testing codes
byte[] valueBytes = value.getBytes();
long nanoTime = System.nanoTime();
String hexString = getHex(valueBytes);
System.out.println(hexString.length());
System.out.println(System.nanoTime() - nanoTime);
nanoTime = System.nanoTime();
System.out.println(hexStringToBytes(hexString));
System.out.println(System.nanoTime() - nanoTime);
with the large xml string testing overall the two action took no more than 2 ms. It much better than other alternative solutions.
Note: The value definition for testing list below - the length for that string is 1024:
String value = "<soap:Body>\n" +
"\t\t<ns0:ChangeRFPProposalStatusAction\n" +
"\t\t\txmlns:ns0=\"http://localhost/MeetingBrokerServices\">\n" +
"\t\t\t<StatusChange xmlns:xsi=\"http://www.w3.org/2001/XMLSchema-instance\"\n" +
"\t\t\t\txmlns:xsd=\"http://www.w3.org/2001/XMLSchema\" xmlns=\"http://localhost/MeetingBrokerServices\">\n" +
"\t\t\t\t<DocumentId>b1f10399-40bd-4e10-9426-9f8291ab3a9f</DocumentId>\n" +
"\t\t\t\t<TransactionId>b1f10399-40bd-4e10-9426-9f8291ab3a9f</TransactionId>\n" +
"\t\t\t\t<DocumentDate>2010-12-25T02:39:31.1241257-05:00</DocumentDate>\n" +
"\t\t\t\t<RfpId>5690777</RfpId>\n" +
"\t\t\t\t<Sites>\n" +
"\t\t\t\t\t<Site>\n" +
"\t\t\t\t\t\t<SiteId>213</SiteId>\n" +
"\t\t\t\t\t</Site>\n" +
"\t\t\t\t</Sites>\n" +
"\t\t\t\t<Status>Declined</Status>\n" +
"\t\t\t\t<DeclineReason>No reason provided</DeclineReason>\n" +
"\t\t\t\t<Message>\n" +
"\t\t\t\t\t<To>OnVantage Public Channel</To>\n" +
"\t\t\t\t\t<From>MB Test, User</From>\n" +
"\t\t\t\t\t<Subject>Turndown RFP</Subject>\n" +
"\t\t\t\t\t<Body>with Attach</Body>\n" +
"\t\t\t\t\t<FromEmail />\n" +
"\t\t\t\t\t<MarketingText />\n" +
"\t\t\t\t\t<MarketingHtml />\n" +
"\t\t\t\t\t<Attachments>\n" +
"\t\t\t\t\t\t<Attachment>\n" +
"\t\t\t\t\t\t\t<FileName>file.txt</FileName>\n" +
"\t\t\t\t\t\t\t<ContentType>text/plain</ContentType>\n" +
"\t\t\t\t\t\t\t<FileData>\n" +
"\t\t\t\t\t\t\t\t<char>111</char>\n" +
"\t\t\t\t\t\t\t\t<char>110</char>\n" +
"\t\t\t\t\t\t\t\t<char>101</char>\n" +
"\t\t\t\t\t\t\t</FileData>\n" +
"\t\t\t\t\t\t</Attachment>\n" +
"\t\t\t\t\t</Attachments>\n" +
"\t\t\t\t</Message>\n" +
"\t\t\t</StatusChange>\n" +
"\t\t</ns0:ChangeRFPProposalStatusAction>\n" +
"\t</soap:Body>";
Do you here about C10K?
C10K normally means how to create 10K connections between client and sever via tcp protocol. Have you ever tried two socket client program creating more than 10K connections with single socket sever program?
So in Windows 2003, you will say 2 socket client program can only create 5K connections with 1 socket server program as Windows 2003 default max_user_port is 5000.
So in Windows 2008, you will say 2 socket client program can only create with 15K connections with 1 socket server program as Windows 2008 default max_user_port is 15000.
But I will say you are wrong totally, do you remember the definition for Ephemeral Port?
So the terminology of ephemeral port is mainly used for the socket programming. So (client_ip, client_port, server_ip, server_port) which is ephemeral port actually, the answer is client_port.
So this time can you repeat answer the question above:
So in Windows 2003, you will say 2 socket client program can create 10K connections with 1 socket server program as Windows 2003 default max_user_port is 5000.
So in Windows 2008, you will say 2 socket client program can only create with 30K connections with 1 socket server program as Windows 2008 default max_user_port is 15000.
Then you will find out the max_user_port actually definied the times client can connection with the same server service (server_ip, server_port).
Recently I do test with Netty project with their echo examples,
1. One server machine start with Server Program.
2. Client occupied 3 machines * each machine started 4 jvm instances = 12 jvm instances and each instances will send out 2K connections. So totally we got 24K connections at the end.
Note:
1. all of them based on Windows 2008, the jdk is 1.6_21.
2. The client.bat you need change the parameter with your <sever host address> <server port:8080> <initialMessageSize:256>
It's dummy only can view the connection be connected. But that already give you the ideas how can we implement C10K currently.
Next I will try my best fullfill more functions and try C500K ! Please wait for that post later.
Normally we only have two ways to traversing the object graph of java.
(Assume the java object we talking is conform to java bean specification getXXX/setXXX)
* Prototype java method calling
For instance:
A a = new A();
String name = a.getName();
Benefit:
* Fast and efficient
* No need arbitrary cast
Drawback:
* Only static binding and cannot dynamic specify
* Maintance effort if high and may change regarding to object instance change.
* Java reflection
For instance;
Method method = A.getClass().getMethod("getName());
A a = new A();
String name = (String)method.invoke(null, a);
Benefit:
* Can be used in the flexible way
Drawback:
* Slowly and may cause PERM generation gc times.
* Type safety not be promised.
So if you want to traversing the object graph of java only way - balance the effiency and performance - is prototype java method. But many of us cannot affort the maintainence effort.
Right now how do we do ? We can leverage the scriptable tools. Here we have three choices: JAXB + Xml Parsing, JXpath, MVEL.
* JAXB + Xml Parsing
First use JAXB deseralize the object into XML, and then use parsing tool interpret them.
* JXpath
Use the simliar XPath methodology interpret the object graph path. It was created by Apache.
* MVEL
The scriptable container can execute the documented java programming.
At the end we select the MVEL as the library small and the execution spee is very fast and quite the little slower than JVM. For instance:
A a = new A();
String name = (String)MVEL.eval("getName()", a);
But here we still have several chanllenges for object traversing:
First, how can we get know the detail of one object.
The answer is annotation, here we can leverage XmlType.
@XmlAccessorType(XmlAccessType.FIELD)
@XmlType("A", propOrder={ "name",
"title"
})
public class A {
private String name;
private String title;
}
Then we can use the A.getClass().getAnnotation(XmlType.class).getProperOrder(). Then you will know the object fields detail.
But several things need to be handled:
* Class hierachy. Class.getSuperClass()
* Static fields. Class.getDeclaredFields()
* All detail collection variables need have a value. Because that's limitation for java reflection
So you can generate the fields collection with the following structures:
public class AutoFieldEntry {
private String simpleFieldName;
private String typeInfo;
private String fullFieldPath;
private String xpathFieldPath;
private String mvelFieldPath;
private String fieldReferenceName;
*** ***
}
Then you will have the whole object structures.
Second, how can we avoid the arbitrary object casting.
* Generics help
public T getValue(String simpleFieldName, Class<T> type, A container) {
AutoFieldEntry entry = getFieldsEntry(simpleFieldName);
if(entry.getTpeInfo().equals(type.getName())) {
return (T)MVEL.eval(mvelFieldPath, container);
} else {
throw new Exception("The type you want don't match with the class definition");
}
}
So after those things done, you have the object atrribute arbitrary access container. It reduce the reflection disadvantages and usage was more simlar with java propotype method calling with acceptable peformance ahead.
Example for understanding:
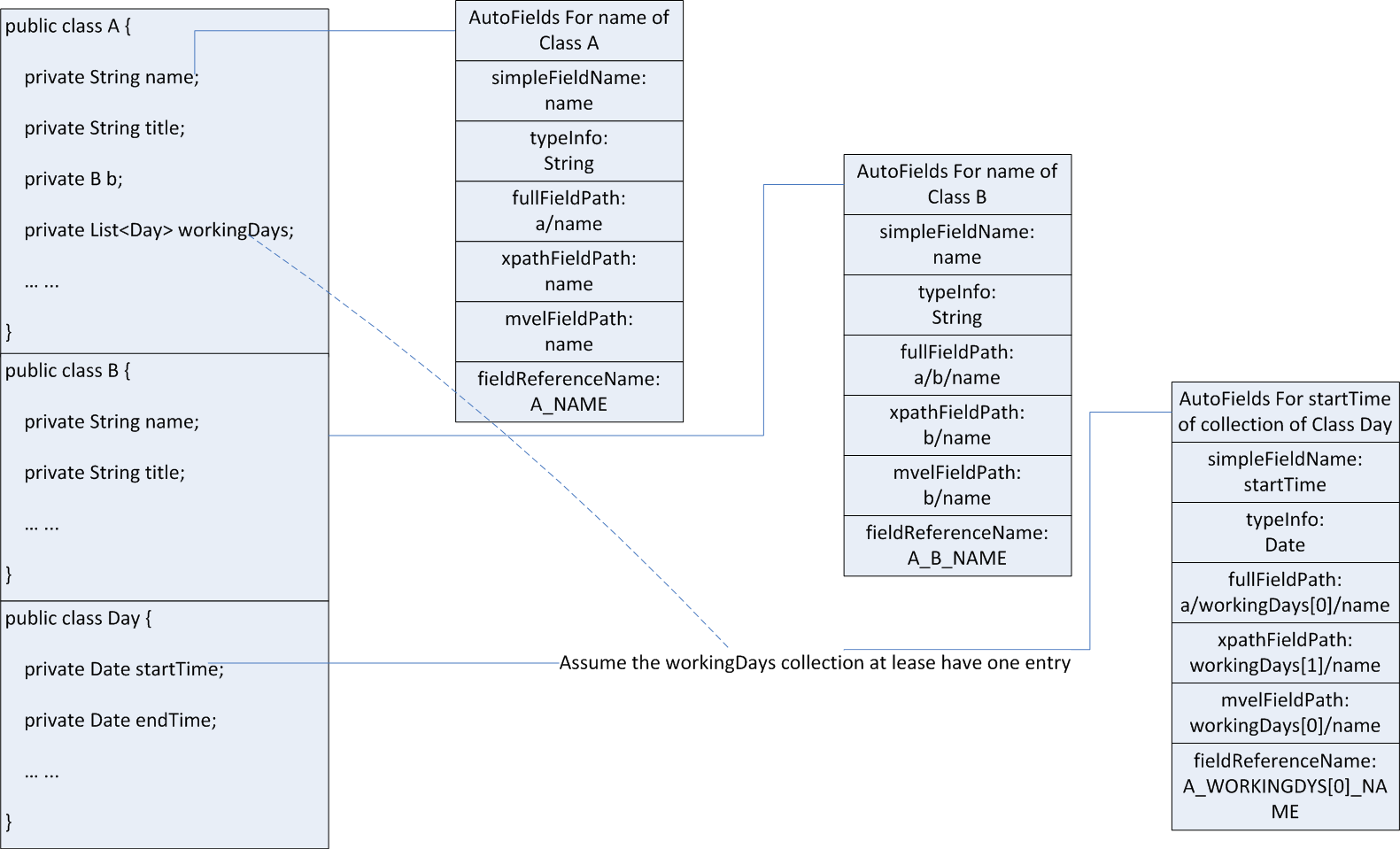
The suitable areas:
1. Data binding. Struts, UI drawing, Rule engine or other areas.
Later we will open-source the codes. So you can refer from that.
Reference:
1. JXPath: http://commons.apache.org/jxpath/
2. MVEL: http://mvel.codehaus.org/
3. Visitor for object graph traversing: http://stackoverflow.com/questions/3361608/java-object-graph-visitor-library
We often meet this situation "Boss always need balance between technical initiatives (especially performance tuning) and business feature". The account manager or sales will always say more features more revenue. How do we say competitive comments ?
Here I want to post one interesting point, performance tuning can reduce the cost of everyday and greenfield. As all of us know the normal state of computer quite like bear hibernate, so the cost for that state is very low and the voltage usage of power is low either. But if something want to running in the computer the voltage usage will go-up. So the goal of performance tuning want to keep the go-up state lifetime shortest. So please do the following steps:
1. First, get the average voltage usage of normal state of your server.
2. Second, without tunning get the average voltage usage of load running state of your sever.
3. Third, with turning get the average voltage usage of load running state of your sever.
4. Fourth, conclude with each milliseconds performance gainning = # number of voltage reduce / hour
5. Fifth, calculate the money reduced for the voltage saving.
Then later you would say like this "If we could reduce the performance by XXX milliseconds then we can approximately reduce XXX voltage / hour". And each voltage will cost # dollar, so we approximately reduce # dollar totoally 1day. And also by reduce # of cs call, we also reduce # dollar totally 1 day.
At that stage, I think your comments and point will be easily accepted by your boss and sales. Because all of us the purpose is reduce cost and enlarge revenue (Money).
- Keep Long Live Consumer or Producer healthy
Most messaging system suggest keep reusing the constructed connection and reduce the significant overhead as you can. But many of them hadn't given us the solution how to keep the connection or other underlying dependent object healthy, so if you didn't take care of that you would find many unexpected behavior happen. So solution could be the following two:
- Reactive Mode
You are sure the connection or other underlying depend object unhealthy in sometime, so you will regular check each connection or underlying depend object usages. After one connection or underlying depend object is not used from a while, you can reload or reinitialize that connection.
Benefit: It can meet the connection healthy requirement and no need big moving for your infrastructure
Drawback: The point for reloading or reinitilization was hard to decide. And almost failed in many cases
- Proactive Mode
Many messaging system are building upon the traditional TCP/IP, so that means the underlying was one tcp (socket) connection. So keep the connection or underlying depend object for messaging system would transfter to keep tcp (socket) connection healthy. So here you can use heartbeat methodology.
Benefit: It can fullfil the healthy requirement and meet many situations.
Drawback: Big moving for your infrasturcture
So the goal for many messaging system in the future is reduce the overhead for create connection or underlying depend object, and provide the configurable way or transparently keep the connection or underlying depend object healthy fullfil the requirement for the long live (or large scalable messaging driven system)
[Ephemeral Port]
Ephemeral port is one virtual port concept, it includes the 4 parts {client_ip, client_port, server_ip, server_port}
So if server can provide 5000 port number for tcp connection, that means total sever can allow the maximumconnections was:
# of client * 5000
Below was referenced from: http://www.ncftp.com/ncftpd/doc/misc/ephemeral_ports.html
Ephemeral ports are temporary ports assigned by a machine's IP stack, and are assigned from a designated range of ports for this purpose. When the connection terminates, the ephemeral port is available for reuse, although most IP stacks won't reuse that port number until the entire pool of ephemeral ports have been used. So, if the client program reconnects, it will be assigned a different ephemeral port number for its side of the new connection.
[Windows MaxUserPort]
Windows default provide the limition to be 5000 in windows 2003 and 15000 in windows 2003.
[Consideration]
Question #1: Will I need always tuned the port range?
Answer #1: Yes and except you know your client will be intranet connections. And each connection is short-around request and response so can finish very quickly. And time_out setting you should also consideration.
For examples:
10000 client of intranet Server port range is 5000
If each connection can be finished below 500 ms, so you won't need tuned the port range. Otherwise you need.
- Turn on Gzip for web service request and response
When constructing client stub instances, we can do the following things: (Assume we use CXF or JAWS-ri)
AService portyType = super.getPort(AServiceQName, AServicePortType.class);
BindingProvider bp = (BindingProvider) portType;
bp.getRequestContext().put(BindingProvider.ENDPOINT_ADDRESS_PROPERTY,
"<service address>");
Map<String, List<String>> httpHeaders = new HashMap<String, List<String>>();
// For request
httpHeaders.put("Content-Encoding", Collections.singletonList("gzip"));
// For response
httpHeaders.put("Accept-Encoding", Collections.singletonList("gzip"));
bp.getRequestContext().put(MessageContext.HTTP_REQUEST_HEADERS, httpHeaders);
It can reduce a lots network bandwidth and faster transfer flow in the network But the server need do some configuration change can accept or
recognize gzip content.
- Cache | Pool the service stub handler
For jbossws, CXF, jaws-ri you can cache or pool the client service stub handler, you can get benefit from the JAXB cache. So the total
performance will improve a lot. But XFire you cannot as it will have perm generation contiue gc issues.
And cache | pool has two choices:
* Session based
Invovle http session, it more like pool
* Dispather
Invovle some load balancing, so it more like cache
- Reduce as many network communication as you can
* Coarse-grained api provided
But that not 100% true. For example: 99% customer need one field of one service model, at that time corase-grained or fine-grained ? But in
general coarse-grained api was the goal
* Know your capacity
Define the box for your services, so that means know your server capacity. Load balancing and partitionning prepare from the very beginning.
- Service aggregator
* Multiple correlated service request can be aggregate together and consider gateway service.
So the average performance of mutiple intranet communications better than the average of multiple internet communications.
- Tuning your enviornment
* Turn on the large memory page support
Reduce the page missing and avoid cpu swap the phsyical memory and disk.
* Turn on NUMA, turn of hyperthreading, turn Tubor boost
* Configure the JVM with the folloing:
** Turn on support NUMA: -XX:+UseNUMA -XX:NUMAPageScanRate=0 -XX:-UseAdaptiveNUMAChunkSizing
** Give enough memory with 64bit: -Xmx16g -Xms16g -Xmn4g
** Turn on parallel old gc if support: -XX:ParallelGCThreads=50 -XX:+UseParallelOldGC
** Turn on large page support: -XX:LargePageSizeInBytes=64m
- Column Restriction
If you choose to also include expressions that reference columns but do not include an aggregate function, you must list all columns you use this way in the GROUP BY clause.
One of the most common mistakes is to assume that you can reference columns in nonaggregate expressions as long as the columns come from unique rows.
For example:
Table
Student
Colunms:
ID Numeric Primary key
Name String Not Null
Age Int Not Null
Class String Not Null
Score Int Not Null
So if we want get the average score and total class selected for each student include ID, name
Failed query:
select ID, Name, Count(*) as NumOfClass, Sum(score)/numOfClass
from Student
group by ID
Correct query:
select ID, Name, Count(*) as NumOfClass, Sum(score)/numOfClass
from Student
group by ID, Name
More reasonable query:
select Name, Count(*) as NumOfClass, Sum(score)/numOfClass
from Student
group by Name
- Grouping on Expressions
One of the most common mistakes is to attempt to group on the expression you create in the SELECT clause rather than on the individual columns. Remember that the GROUP BY clause must refer to columns created by the FROM and WHERE clauses. It cannot use an expression you create in your SELECT clause.
For example:
Wrong Sql:
SELECT Customers.CustLastName || ', ' ||
Customers.CustFirstName AS CustomerFullName,
Customers.CustStreetAddress || ', ' ||
Customers.CustCity || ', ' ||
Customers.CustState || ' ' ||
Customers.CustZip AS CustomerFullAddress
MAX(Engagements.StartDate) AS LatestDate,
SUM(Engagements.ContractPrice)
AS TotalContractPrice
FROM Customers
INNER JOIN Engagements
ON Customers.CustomerID =
Engagements.CustomerID
WHERE Customers.CustState ='WA'
GROUP BY CustomerFullName,
CustomerFullAddress
Correct Sql:
SELECT CE.CustomerFullName,
CE.CustomerFullAddress,
MAX(CE.StartDate) AS LatestDate,
SUM(CE.ContractPrice)
AS TotalContractPrice
FROM
(SELECT Customers.CustLastName || ', ' ||
Customers.CustFirstName AS CustomerFullName,
Customers.CustStreetAddress || ', ' ||
Customers.CustCity || ', ' ||
Customers.CustState || ' ' ||
Customers.CustZip AS CustomerFullAddress,
Engagements.StartDate,
Engagements.ContractPrice
FROM Customers
INNER JOIN Engagements
ON Customers.CustomerID =
Engagements.CustomerID
WHERE Customers.CustState ='WA')
AS CE
GROUP BY CE.CustomerFullName,
CE.CustomerFullAddress
It referenced from "SQL Queries for Mere Mortals, Second Edition"
Most distrubution system will select UUID as the object indentifier. But the length of UUID would be 36 chars and in Java it need 72 bytes persist and it was randomly and no-sequential inside so it will hurt the search/lookup within storage. Even some system provide some sequential UUID support, but it binding with system (specialization). So here I want post new way replace that:
The new ID will be includes the following parts:
1. Sever identifier
2. Component identifier
3. Thread identifier (need consider thread group | thread pool either)
4. Time (it need be judged by your system loads, seconds, milliseconds, etc)
Note: Time should be consider centralized synchronized. Otherwise it's not universal unique. Please refer:
http://community.jboss.org/people/andy.song/blog/2010/12/09/the-time-of-your-machine-can-be-trust
For examples:
1 2 111 6183640443687
Sever Component Thread NanoTime
So totoal 19 bits, and its numeric values. And in general situation is has sequence, so use that kinds of id will improve a lot your system performance.
It's not new, Twitter current will leverage that ideas. One of their engineer open source that library (snowflake) in:
https://github.com/twitter/snowflake/tree/1cd0af14db9efa7972a9ed605661a7b70962914a/src
OS will provid your the time support for you automatically, so you already used to that. But how about you go to distrubuted computing senarios, which means multiple servers works for large chunk requests, can you trust each machine time? The answer is "no", as time for each machine depends on the electronic power so some may go faster some may go slower. So that may introduct some expected behaviors if you don't handled that.
So from machine perspective the time synchronization come to stage, for example: Windows Time Service.
But how about from software perspective ? The answer is "centralized or distributed Time service".
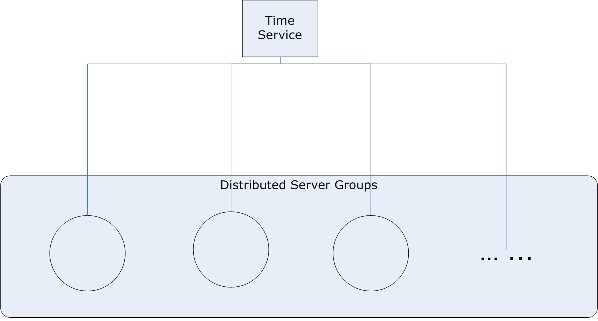
The chanllenges will be:
* Network Communication Latency
* The scale level you want to achieve (Seconds, Milliseconds, Nanoseconds, etc)
* Still need machine time service coordination because how about you want to do geographical distribution
* SPOF invovled ? Maybe, but you can overcome by some other design.
1. The restriction of ephemeral port range in OS when designning long running Queue|Topic consumer
2. TCP time_wait and close_wait impact on the create new connections with Messaging Server
3. Due to producer or consumer were client from TCP/IP design, so the close one tcp/ip connection wasn't active close. That will hurt the messaging server capacities.
4. Equal messaging size or freedom messaging size? Equal messaging size will decrease the message server persistence fragment will bring you more benefit when large concurrent messaging going-in and -out.Compressed or uncompressed? Compressed with some overhead with client perspective but gain more benefit from Messaging Server perspective, so it deserved to compressed messages as you can.
5. General Messaging Header need consider, recommend:
* Source
* Destination
* Version
* SendTime
* ReceiveTime
* TransactionId or CorrelationId
6. Messages compatibility.
Do you have more advices?
Will Java "New" keyword putting inside or outside synchronized block?
Posted by andy.song Dec 1, 2010[Introduction]
Recently I was joined one interesting discussion with my colleagues "What's details for "new" operations of Java? Putting "new" inside or outside synchronized block?". I surprisingly found nobody could telling correctly about that. So here I listed the possible semantics about "new".
A a = new A();
1. Loading class definition of Class "A"
* Using class loader of current thread trying to load class "A"
* Reading the class information into memory (it was "Native Memory" or "VM heap" ? - My answer will be both)
* Transforming the class information to runtime JIT codes let JVM could executing them.
2. Calculate the initial memory consumption for the instance of class "A"
* Calculation contains:
** Static Variables
** None-static Variables
note: Please remember the differences between reference and object. Otherwise you cannot understanding the concept.
3. Analysis the hiercharies of Class "A". Then loop the step 4, 5, 6 until all the class of hiercharies were touched:
4. Use the size be calculated by previous step and use system level "C" function "malloc" allocate the memeory of OS.
* Malloc is not thread safe except several flag need to be set
* Malloc implementation is OS depend.
note: Sun already cover those issues. 99% is thread safe.
5. Create the reference in the stack, and make the reference point to the Object.
6. Calling the object constructor method and do initialization
* Static initialization
* None-static initialization
* Constructor body
note: any of above path could be none-thread safe victim.
So here the answer for "new" is thread safe or not is uncentainty or Dependes class/object instantiation need to be thread-safe.
[Back to topic]
Then the strategy for putting "new" operator inside or outside synchronized block will be:
* Always putting the "new" operator inside the synchronized block except when
* Only if you understand or design class completely and already make sure the whole path is thread safe, you can put the "new" operator outside synchronized block.
References:
"http://gee.cs.oswego.edu/cgi-bin/viewcvs.cgi/jsr166/src/main/java/util/concurrent/LinkedBlockingQueue.java?view=log reversion 1.54
move value allocation outside the lock scope."
Actions
Filter Blog
By date:
By tag: