[Introduction]
One day when I read someone interview experiences. I find he had been asked this kind of question, and he provided the solution accordingly. But I thought his solution wasn't so correct at some level. So here I want to present more accurate one for you.
[Consideration]
Several things we should consider before begin your coding.
1. Will the two sorted linked list have the same sorted order?
For example: LinkedList A:{1,2,3} LinkedList B:{7,6,5}
2. Will the final merged linked list has the sorted order request?
For example: LinkedList A: {1,2,3} LinkedList B: {4,5,6} but expected result is {6,5,4,3,2,1}
3. Whether or not allow change the amount of data ?
For example: Whether or not allow remove the redundant data.
4. Whether or not exist the memory limitation ?
[Code snippet]
Here I have several assumptions:
1. Memory could holding the whole data.
2. Sorted order could be random
3. Assume the output sorted order is big-ending - from smaller to bigger
4. Should not remove any data from the two lists.
5. Using java
If you want to check the accuracy you could goto here for checking.
goto http://www.leetcode.com/onlinejudge and below the issue list you find "Merge two sorted lists", then click ">> solve the problem". And copy my codes into coding panel, please remember language be selected as Java. You can click "Judge Small" or "Judge Large". Right now the result is 100% pass.
Reading codes from here isn't comfortable, so you download the attachment files into your ide or copy the coding panel. And the "png" file is the guideline how to use "leetcode" website.
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
enum SORTED_ORDER {
LITTLE_ENDING, BIG_ENDING
}
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
// Start typing your Java solution below
// DO NOT write main() function
/**
* The solution need consider several factors:
* 1. the sorting order for two list
* 2. the output list sorting order
* 3. memory limition. Please remember assumption could hold within memory.
* 4. Whether or not allow change the merged result, like remove redudant data.
*
*/
//Based on that here assume the output sorted order will be BIG_ENDING
ListNode result = null;
if (l1 == null && l2 == null) return null;
if (l1 == null && l2 != null) return sort(l2, SORTED_ORDER.BIG_ENDING);
if (l1 != null && l2 == null) return sort(l1, SORTED_ORDER.BIG_ENDING);
ListNode tmpNode1 = sort(l1, SORTED_ORDER.BIG_ENDING);
ListNode tmpNode2 = sort(l2, SORTED_ORDER.BIG_ENDING);
//Begin some sort of merge sort
ListNode bNode = null;
boolean oneListFinished = false;
do {
ListNode tNode = null;
if (tmpNode1 != null && tmpNode2 != null) {
if (tmpNode1.val <= tmpNode2.val) {
//tNode = new ListNode(tmpNode1.val);
tNode = tmpNode1;
tmpNode1 = tmpNode1.next;
} else {
//tNode = new ListNode(tmpNode2.val);
tNode = tmpNode2;
tmpNode2 = tmpNode2.next;
}
} else if (tmpNode1 != null) {
//tNode = new ListNode(tmpNode1.val);
tNode = tmpNode1;
tmpNode1 = tmpNode1.next;
oneListFinished = true;
//break;
} else if (tmpNode2 != null) {
//tNode = new ListNode(tmpNode2.val);
tNode = tmpNode2;
tmpNode2 = tmpNode2.next;
oneListFinished = true;
//break;
}
if (bNode != null) {
bNode.next = tNode;
bNode = tNode;
if (oneListFinished) break;
} else {
bNode = tNode;
result = tNode;
}
} while (tmpNode1 != null || tmpNode2 != null);
return result;
}
public ListNode sort(ListNode l3, SORTED_ORDER order) {
SORTED_ORDER l3Order = SORTED_ORDER.BIG_ENDING;
ListNode tmpNode = l3;
if (tmpNode.next != null && tmpNode.val > tmpNode.next.val) {
l3Order = SORTED_ORDER.LITTLE_ENDING;
}
if (l3Order != SORTED_ORDER.BIG_ENDING) {
ListNode movedNode = tmpNode.next;
while (movedNode != null) {
ListNode immNode = movedNode.next;
movedNode.next = tmpNode;
tmpNode = movedNode;
movedNode = immNode;
}
}
return tmpNode;
}
}
Several things you may need know about Sharding system architecture
Posted by andy.song Jan 21, 2012[Introduction]
Some of you may wondering what's sharding? If you don't know the concept, please read the link http://en.wikipedia.org/wiki/Shard_(database_architecture). It's very useful when you want to deal large data set throughput and traditional single data cluster group (Master-Slave, Master-Master and Slave-Slave, etc) setting couldn't survive from that kinds of situaion. It's concept is very simple and you may know in advance "Divide and Conquer". It has very different characters that quite different with Partition technique (You may know that from some database providers), since Partition was database layer specific technique but Sharding could spread across all layers you could touch.
[Rolling in the deep - amazing voice of Adele]
For examples, You have one web online product it holds only one page, and that page need load data from one table. And imagining if you have 1 billion data persist in that table which was located in single oracle/my-sql/ms-sql server and you query againts that table in average need cost 2 seconds under load 1000 TPS. It's not bad you may said. But please remember that only is database costs for one mature product you may need consider data transformations, network transportation (don't be confused, here I mentioned correlated to from application bewteen end user), page rendering, etc. At the end customer may need pay 5 or 10 seconds for that page action each time in average. Your stakeholder want you provide solution for that issue.
You may come up with other solutions first, but here I could give you one very special. If one table with 1 billion datas need 2 seconds, how about we divide that table into 5 pieces and each piece holds only 200 millions datas. That may related to one math question you may think, possible would be 400 milliseconds, but the result may give you surprise << 400 milliseconds (why two below signs?). Because the database features: the primary data files become more smaller, the indexe files become more smaller, etc. so that means the I/O rounds have been significantly reduced. Okey, you may say "wow" that works for me and go ahead with that proposals with your stakeholds.
Come on, calm down. You need resolve many things before any action against this.
[Things you may know or not]
- Which kinds of rules you want take for dividing the data?
How to divide? You are idiot? (You may think). Very simiple 1 ~ 200 million, 201 million ~ 400 million, etc. Let me tell you.
1. based on row number
2. based on date (year, month or day)
3. based on business data
3.1 If your data contains user information. User identity, male/femal, user location
3.2 If your data contains some unqie enumerations. For example, plane ticket booking system. You may divide data acoording to the plane type and airplane company.
4. Mixed-up all of aboves.
- How you transfer request to the specific regions acoording to data division?
Right now challenge come (if without database help) how could transfer request correctly to the specific regions acoording to data division? Let's imagine, how could you find one phone number from yellow page book? How would the internet controller could work with domain name? So that means we need somewhere persist the division logics or mappings, so that means after we divide data and we could use the same logics or mappings find the correct data again and again. Here we call that as DNS.
- How could we finish some aggregation jobs after data division?
Total counts, min, max across all the datas, this feature was very useful in some kinds of situation especially customer need that. But after division, all aggregation features was gone since database not hold all the data never. You may need work out solution as you own. More worse situaion you need work out cross data division join features. That effort I thought could not be estimated.
- All other layers except data layer will be impacted also
Before data division you data access layer could static the db connection information since that's not changed during runtime. But after data division your data access layer need accomodate the db connection information will be changed frequently due to the data has been splitted.
Cache layer may also need persist more information especially for the data location information
Restful interface was impacted also you may need always transfer the key data (that help division) back and forth.
- Data consistency you may lose in some level
Since data was splitted, you may end up with need update data across different data regions. XA wasn't good from performance and scalability perspective, because those two factors drive you towards to data sharding. So ACID unfortunatly cannot be covered.
- Data re-division
Since data size will grow every day, you may end up with some data region grow unexpectedly larger. You need re-division again. And you may need go through above issues again.
- High maintenance effort
You may need work out tools help you manage and monitoring those data region.
[Black or white]
You may say "come on, so crazy, I will never try". But here please know its advantages.
- High scalability
Since your large data region become many smaller region, that means your throught also be splitted up either. So you could provide more capacity from throughput pespective, so could reach high scalability more easier.
- High performance
Query against smaller data with better performance, I think that is very easy math question. With large in-memory cache, data grid or cloud data service, you may even going to get more better performance.
- High availability
Because you have many regions, so that means customer may also be splitted either. Less data means you could hold more capacity room in one single region, OOM, ConnectionReset, Running out of connection limition, Connection Timeout, etc you may not meet often comparing to traditional solution.
- Smaller portion customer impact when something happen (planned or un-planned)
Because you have many regions, so that means customer may also be splitted either. So even one portion of your regions crashed won't impact other regions, and you could provide better site-down deployment services. Like you could deploy China region at 00:00:00 of china timezone, USA region at 00:00:00 of usa timezone.
- Recovery will be easier
Smaller data recovery will be less effort and more quick.
Note: all of above benefits need your architecture provide better design in advance, otherwise you won't reach the gold and may meet more worse situation.
[Nothing is impossible except Death or Debt]
- First, consider your business model. Is data consistency was very critical to customer?
If your customer could allow the window existence for data inconsistency (well-know data latency). You could go for with this solution. Flicker, twitter, etc adpot this solutions.
- Second, sharding as earlier as possible
If your system architecture from very beginning without consider sharding, changed from non-sharding to sharding will be big headache. But incrementally migrating could be acceptable, but that will more testing your system design ability. More backward-compatibility will be invovled which also is very challengeable. So try you best make it happen as earlier as possible.
- Third, sharding up-front
Sharding up-front will be better choice, since that will reduce the complexity, reducing the coupling between many components and provide the enough flexibility. That will be disucssed in the future topics.
- Fourth, let service fly
Try you best using service arming every components especially hidden the location information. So if one type tuning or improvement could be spread across the same component service.
- Fifth, single function service rather than huge monothlic funcions service
Split the multi-functional components into multiple single functional components would help you a lot. Not only from design perspective but also from organization perpective.
- Sixth, re-organ your teams
Sharding need you more consider or take care of product matainence and monitoring, so you should enlarge product running teams. Like facebook, they have a speical team working for feature deployments and monitoring.
- Seventh, keep changing
[Summaries]
Sharding need many things changing and planning quite different from traditional model. But it did provide many benefit that you cannot decline with that.
1. http://en.wikipedia.org/wiki/Shard_(database_architecture
3. http://highscalability.com/scaling-twitter-making-twitter-10000-percent-faster
[Introduction]
After almost one year using HornetQ for our products, we did get many benefits from this brand new messaging server. But we also met serveral issues, these issues would represent the designer of this product had no very clear sense of the variant of any prouduct env . Here we will go through them each one by one.
[Jonney Walker]
- HornetQ didn't provide any time control mechanism.
All of us will know machine time is not controllable, especially when multiple machines want to working together. You may meet this kinds of situation: you have three machines, one machine time is 19:40:33 (HH:MM:SS), second machine time is 19:41:02 (HH:MM:SS), third machine time is 19:39:22(HH:MM:SS). And second machine will hold HornetQ server, let's saying if third machine says " i send one message to HornetQ server, and I want keep my message will be expired after 30 minutes". This feature has been implemented by HornetQ in working stage but not functional stage, because if you go through HornetQ source code you will find it use System.currentMilliSeconds() to manipulate the time elapsing. So the problem you will find out ? Yeah, it may happen in two issue: 1. Message not survive according to time expiration setting. 2. Message will exist longer than time expiration setting. Why? Because you should aware: 1. TimeZone setting may different from the three machines. 2. The different time will happen at that time across the three machines. Side effect for that kinds of issue may be : 1. Customer will complain the message was disposed too faster. 2. The message queue will queue up very quickly. Maybe you will say that acutally should not be HornetQ's responsiblity, yeah maybe, but I strongly believe at least HornetQ should provide the interface allow customer plug-in any time control mechanism.
More worse situation may happen in this kind situation: everyone should familar with JMS specification, we all know the consumer features. One feature of consumer is getMessage(long timeOut). That means wait specific time if cannot get message from message server and then retry. It's very useful for long-live message consuming pattern. Issue occur again, here please revie one piece of code:
long start = -1;
long toWait = timeout;
try
{
while (true)
{
... ...
while ((stopped || (m = buffer.poll()) == null) && !closed && toWait > 0)
{
if (start == -1)
{
start = System.currentTimeMillis();
}
... ...
wait(toWait);
... ...
long now = System.currentTimeMillis();
toWait -= now - start;
start = now;
}
}
Do you find issue? No, let's saying if your machine timezone is PST and right now will go through daylight saving. And you will find you cannot get message and consumer.getMessage method will not return. Because this piece of code if not safe, it didn't add any check between toWait and timeOut. So how about we add one line code like below?
long start = -1;
long toWait = timeout;
try
{
while (true)
{
... ...
while ((stopped || (m = buffer.poll()) == null) && !closed && toWait > 0)
{
if (start == -1)
{
start = System.currentTimeMillis();
}
... ...
wait(toWait);
... ...
long now = System.currentTimeMillis();
toWait -= now - start;
start = now;
if (toWait >= timeout) toWait = 0;
}
}
- HornetQ lack abstraction of storage layer (No recovery feature).
Wait! You may say no to me, because HornetQ has storage layer and it works very well. And we all know HornetQ works on files rather than db and right now only support share storage (share file) mode for Master-slave setting, but how about share storage met issue need restart (since hornetQ recommend for SAN for share storage solution). You may find if share storage is restarted, HornetQ will not work any more even the share storage has come back. So that kind of working mechanism will force you will consider more complex alternatives when Hornet is crashed totally.
So from my mind, I try go through HornetQ codes want to find the entry point could add recovery feature. But since it leverage NIO ( we didn't use AIO) lack some information assistance, I could not complete that feature.
Good news they will provide the replication fucntions that will resolve this issue in some levels. Waiting for HornetQ 2.2.6
[Conclusion]
HornetQ team please consider these issues, handle them in the first priority rather than provide more features. And hope these experiences will help you.
1. Novice level
Code block:
public class Bear {
private String name;
public boolean isMatch(String mName) {
if (name.eqauls(mName)) {
return true;
}
return false;
}
public void setBearName(String name) {
this.name = name;
}
}
public class Tester {
public static void main(String[] args) {
Bear bear = new Bear();
bear.isMatch("Foolish Bear");
}
}
How about the result ? You will smile immediately, because it's too easy. Object filed in java will not assign value by JVM initially.
2. Intermediate level
Code block:
public class Bear {
private String name;
public Bear(String name) {
this.name = name;
}
... ...
}
public class BearFactory {
private LinkedBlockingQueue<Integer> bearPool;
private Bear[] bearArray;
public BearFactory() {
bearPool = new LinkedBlockingQueue<Integer>();
bearArray = new Bear[10];
init();
}
public void init() {
for (int i=0; i<10; ++i) {
bearPool.push(new Bear());
}
}
public int sizeOfBearPool() {
return bearPool.size();
}
public int availableBearIndex() {
return bearPool.poll();
}
public Bear getBear(int index) {
return bearArray[index];
}
}
public class Tester {
public static void main(String[] args) {
BearFactory factory = new BearFactory();
if (factory.sizeOfBearPool() > 0) {
factory.getBear(factory.availableBearIndex()).isMatch("this is trap bear");
}
}
}
How about this result ?
Actually here has two issues:
1. Box and unbox for primitive type. Because bearPool.poll() will return null for Integer type, but that method need return int type. That casting will report nullpointer exeception.
2. Use wrong collection fetch mode. Do you remember this mode?
if (collection.size() > 0 )
do something with that collection.
Effective java already give comments on that part.
3. Practical level
Code block:
public class Bear {
private String name;
private Logger logger = Logger.getLogger(Bear.class);
public Bear(String name) {
this.name = name;
}
public boolean isMatch(String mName) {
if (name.eqauls(mName)) {
logger.log("This is trial comments");
return true;
}
return false;
}
public void setBearName(String name) {
this.name = name;
}
}
public class Tester {
public static void main(String[] args) {
Bear bear = new Bear();
bear.isMatch("Foolish Bear");
}
}
How about this result ? ... ... Do you have answer ? ... ... Do you need hints? ... ... Ok, if you don't have any tip about that, I recommend you read java memory model. Actually the NullPointer exception will happend in "logger.log("This is trial comments"); ". Why was that line ? Because in java memory model it will not guarantee the object instance filed constructed completely, you can call java constructor atomic issue. But in which situation you will get exception, the answer is in multi-threading exectuion senarios. How to resolve that ? try add "final static" for the logger variable construction.
Introduce one useful book "The Architecture of Open Source Applications"
Posted by andy.song Jun 17, 2011If you have interesting with architecture of open source application, then this book will be one of them.
http://www.aosabook.org/en/index.html
You can read from online.
In java we didn't have log2n library but we have log10n library, so we can leverage with that
public static double log2(double num)
{
return (Math.log(num)/Math.log(2));
}
Enjoy that.
Note: if you want to use that correctly, remember with the (double) cast for accuracy.
[Introduction]
"How many threads should I create?". Many years before one of my friends asked me the question, then I gave him the answer follow the guideline with " Number of CPU core + 1". Most of you will be nodding when you are reading here. Unfortunately all of us are wrong at that point.
Right now I would give the answer with if your archiecture was based on shared resource model then your thread number should be "Number of CPU core + 1" with better throughput, but if your architecture was shared-nothing model (like SEDA, ACTOR) then you could create as many thread as your need.
[Walk Through]
So here came one question why so many eldership continuely gave us the guideline with "Number of Cpu core + 1", because they told us the context switching of thread was heavy and would block your system scalability. But noboday noticed the programming or architecture model they were under. So if you read carefully you would find most of them described the pragramming or architecture model were based on shared resource model.
Give you several examples:
1. Socket programming - socket layer was shared by many requests, so you need context switch between every requests.
2. Information provider system - most customer will contiuely access the same request
etc...
So they would meet the multiple requests access the same resource situation so system would require add lock to that resource since consistency requirement of their system. Lock contention would come into play so the context swich of multiple threading would be very heavy.
After I find this interesting thing, I consider willother programming or architecture models can walk around that limitation. So if shared resource model has failed for creating more java threading, maybe we can try shared nothing model.
So fortunately I get one chance create one system need large scalability, the system need send out lots of notfication in very quick manner. So I decide go ahead with SEDA model for trial and leverage with my multiple-lane commonj pattern, current I can run the java application with maximum number around 600 threads if your java heap setting with 1.5 gigabytes in one machine.
So how about the average memory consumption for one java thread is around 512 kilobytes (Ref: http://www.javacodegeeks.com/2011/04/erlang-vs-java-memory-architecture.html), so 600 threads almost you need 300M memory consumption (include java native and java heap). And if you system design is good, the 300M usage will not your burden acutally.
By the way in windows you can't create more then 1000 since windows can't handle the threads very well, but you can create 1000 threads in linux if you leverage with NPTL. So many persons told you java couldn't handle large concurrent job processings that wasn't 100% true.
Someone may ask how about thread itself lifecycle swap: ready - runnable - running - waiting. I would say java and latest OS already could handle them suprisingly effecient, and if you have mutliple-core cpu and turn on NUMA the whole performance will be enhanced more further. So it's not your bottleneck at least from very beginning phase.
Of course create thread and make thread to running stage are very heavy things, so please leverage with threadpool (jdk: executors)
And you could ref : http://community.jboss.org/people/andy.song/blog/2011/02/22/performance-compare-between-kilim-and-multilane-commj-pattern for power of many java threads
[Conclusion]
In the future how will you answer the question "How many java threads should I create?". I hope your answer will change to:
1. if your archiecture was based on shared resource model then your thread number should be "Number of CPU core + 1" with better throughput
2. if your architecture was shared-nothing model (like SEDA, ACTOR) then you could create as many thread as your need.
Which level of design you could reach ? novice, proficient, senior, guru
Posted by andy.song Apr 25, 2011[Description]
Every time when my supervisor ask me assessing the capability or performance of team member I feel very nervous, because I don't want any kinds of wrong assessment will result with wrong impression. But fortunately I try my best conclude serveral principals helpping me find out "how good of design you could". It is very important because it will help my supervisor find out who could get the deserved promotion and keep the whole team have the enough energy and good competition atmoshpere. So here I will list that.
[Walk-Through]
Novice Level
- clearness - need communication and documentation for understanding
- configuration - less
- coupling - tight coupling
- reusability - beginning
- diagnostic - hard
- maintainance - hard
- clearness - need communication and documentation for understanding
Proficient Level
- clearness - need less communication and documentation for understanding
- configuration - beginning
- coupling - mixed tight coupling and loose coupling without correct judgement
- reusability - intermediate
- diagnostic - improvement or have capability
- maintainance - improvement or have capability
- complexity - beginning hide complexity
- autonomy - beginning
- flexibility - beginning
- manageability - beginning
Senior Level
- clearness - only need documentation could be understandable
- configuration - intermediate and have more configuration capability
- coupling - selection between tight coupling and loose coupling
- reusability - beginning have the capability be reused by different senarios
- diagnostic - provide the capability
- maintainance - less effort for maintainence
- complexity - most of complexity were hidden
- autonomy - more autonomy decision happen
- flexibility - provide enough flexibility for change
- manageability - easy for manage
- modulization - component idea come into play
- scalability - beginning
- clearness - only need documentation could be understandable
Guru Level (Note: I'm not guru so here were my guess)
- clearness - easy for understandable
- configuration - completely could be configurable
- coupling - select suitable coupling strategy in different senarios
- reusability - could be reused by different senarios
- diagnostic - not only have the capability but also provide the assistance mechanism
- maintainance - easy for maintainence
- complexity - completely hide the complexity
- autonomy - autonomy will be built-in
- flexibility - easy accomodate many kinds of change
- modulization - architecture and component idea come into play
- manageability - not only have the capability but also provide the assistance mechanism
- scalability - easy for scale improve the efficiency
- clearness - easy for understandable
[Comments]
1. The separation wasn't finalized. So that didn't mean if you already designed somthing many year but you didn't familar some term then you are not the level you are.
2. Nobody will capture all the factors, if you master some of them then you are that level already.
3. Even you understand the factors of one level, but if without practice and project proving we cannot tell which level you are.
4. Please not use this forum directly judge any person. Please reading and understanding that then refer from that for your judgement.
5. If you have different opinion, please throw out your points here. , stick or flower I will accpt.
[Conclusion]
I wasn't master of guru for design part, I just had many design experiences and all the information were my experience and study. So if may or may not accurate and each term I assume you know that. If not, please email to me: hqxsn@hotmail.com. I will help you on that.
[Introduction]
After long term preparation and discussion within my team. We finally release the beta version of multi-lane commonj library.
The project name with tinybang and the link is http://code.google.com/p/tinybang/
[History and Context]
How you handle concurrent request in java? Most of the anwser will be: Thread, Thread Pool.
But Thread, Thread Pool was native api and no any abstraction. So make you application is hard to understand and maintain. So bea, ibm and other groups join toghter define one standard and naming that with CommonJ. The CommonJ especially define one structure how to deal with async-job processing abstraction.
Main Concept:
Default standard:
- WorkManager
The main class define the interface could receive the concurrent job request.
- Scheduler
The class could handle the concurrent job lifecycle. You can imagine that was simlar with process scheduler in the OS design.
- Work
Request composition class. So it's main containing the request parameters and other useful information.
- WorkEntry
The encapsulator class contain work, workeventlistener, etc.
- WorkExecutor
The dispatch class, it will directly talking with the backend async processing engine most was thread pool.
- Queue
Using the FIFO structure to store the concurrent job requests.
- Pipe
Could contain multiple types of queue, that mainly depends on how granularity you want to control the job lifecyle. For examples: pending, ready, pause, etc.
- WorkEvent
Define the information want to notify outside the status of the job request
- WorkEventListener
Define the interface can be plugged into and can be awaring of the status of job request.
- Anync Processing (Thread Pool)
The underlying language provide the async processing machanism. We leverage with java concurrent library ThreadPoolExecutor.
Extension standard:
- Router
If contain the logic for commonj define how to pickup pipe from multiple pipes.
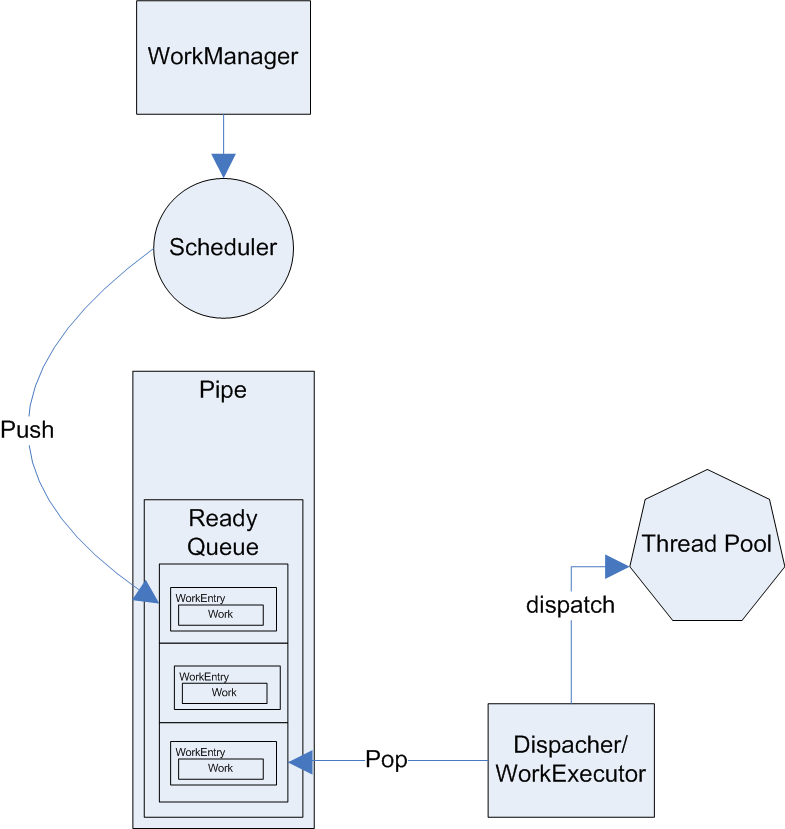
Figure 1: CommonJ
The standard was just a bunch of interfaces not detail implementation. And most implementor just simply implement the logics and binding with thread pool. So from scalability and throughput both cannot meet large amount concurrent job requirements.
And current most company meet the large amount concurrent job handling issues, because java thread creation has limition and distributed computing contain the complexity. So how would we do?
The possible answer could be "MultiLane CommonJ"
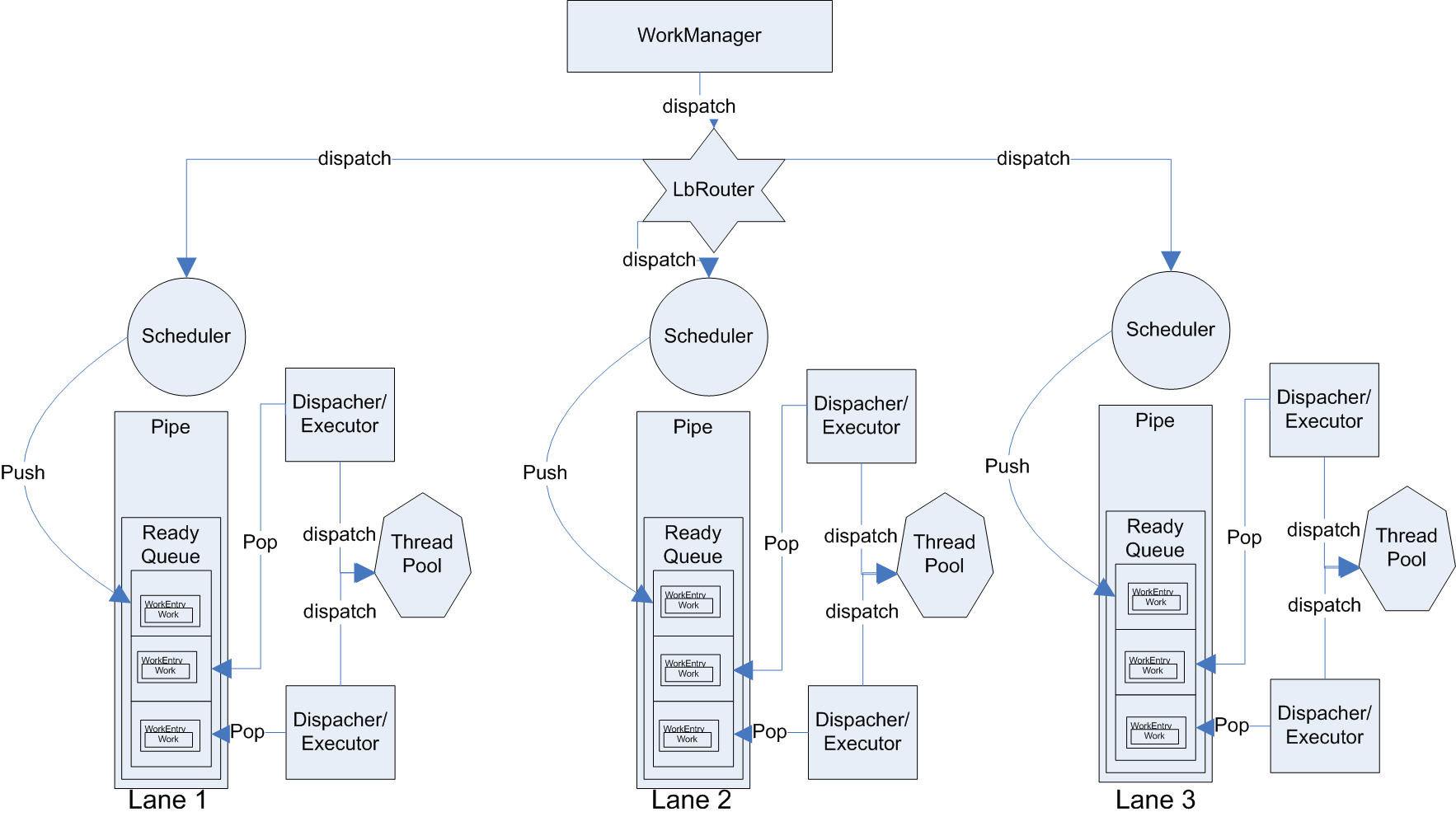
[Follow up]
Next blog we will explain the internal for the multi-lane commonJ library. Please wait for that.
[Reference]
1. TinyBang project : http://code.google.com/p/tinybang/
2. CommJ: http://commonj.myfoo.de/
3. Multilane introduce: http://www.1024cores.net/home/scalable-architecture/multilane
4. Multilane CommonJ Jar: http://code.google.com/p/tinybang/source/browse/tags/tinybang-0.0.1/jar/multilanecommonj/multilanecommonj.jar
[Introduction:]
Recently I worked on one project. The purpose of that project is sending emails according the business rules. So need lots of concurrent jobs then provide the enough scalability and throughput.
It's very interesting we found two solutions:
- CommJ pattern but be optimized from single-lane mode to multiple-lane mode it was designed by me.
- Kilim: Java version Actor, with coroutine support inside.
The kilim said they can work on the million concurrent jobs with minor memory and less thread support. How about the truth?
[Detail:]
Let's design one scenario:
The job contain the follwing steps:
1. Take map<string,string> as request
2. First get the value from the map<string,string> with the key value "KEY"
3. Second execute the subroutine with no parameter.
4. Third the subroutine will wait 200 ms and then return with string result with static value "executed".
| Scenario | Kilim | MultiLane CommJ |
|---|---|---|
| Concurrent 10000 Jobs | Memory consumption: 512M Backend thread count: 160 Total execution time: 10072416187 ns | Memory consumption: 512M Backend thread count: 160 Total execution time: 332489185 ns |
| Concurrent 1000000 jobs | Memory consumption: 1024M Backend thread count: 160 Total execution time: 1256589994539 ns | Memory consumption: 512M Backend thread count: 160 Total execution time: 10244263167 ns |
Note:
- Lab env:
Computer: Dell Latitude E6400
OS: Windows XP sp2
Memory: 4G
JDK: 1.6.1_22
- Kilim exhaust memory a lot when the concurrent job count higher than some level.
- MultiLane CommJ could handle million conncurrent jobs with minor memory and less threads.
- MultiLane CommJ could handle concurrent jobs with almost linear scalability.
- So Java could be very fast even in the very poor machine.
[References:]
1. Kilim: https://github.com/krestenkrab/kilim
2. CommJ: http://commonj.myfoo.de/
3. Mulilane introduce: http://www.1024cores.net/home/scalable-architecture/multilane
[Follow-up:]
I will open source the multi-lane version of commj. So please wait the future introduce.
[Introduction]
In most distributed computing architecture, we can not avoid programming directly with byte information. Like Serialization/DeSerialization, File reading/changing, etc. So all of us need some solution resolve the memory allocation/deallocation effiently with good performance numbers and acceptable overhead.
So here I introduce the memory pool design. It's underlying depends on the ByteBuff of java nio.
[Consideration]
1. Provide the estimated memory block consumptions.
We assumed all of the request for memory requirement can be categorized by many blocks[segment]. The segment could like 64 bytes, 128 bytes, 256 bytes, 512 bytes, etc. And then we could define the pool initial size and final size, like init=2 * 1024 bytes and end= 16 * 1024 bytes. And pool will dispatch the request of memory allocation to the segment that can fullfil the request.
For examples:
The segment will be 2*1024, 4*1024, 8*1024, 16*1024
The request need allocate 3456 bytes, so the segment contain 4*1024 can fullfil the request.
2. Direct ByteBuffer or Heap ByteBuffer
I decided support both of them, as I thought the decision by the application designer. Due to the direct bytebuffer allocation slow than heap bytebuffer, but read/write against direct bytebuffer better than read/write against heap bytebuffer - Of course, all of those comments means generally in average situations.
Btw, if you decide using the direct bytebuffer. Please remember set pool initialization as earlier as possbile than your application codes.
[Reference]
We already created one open source project: TinyBang - http://code.google.com/p/tinybang/
You can find the memory pool implementation from there.
svn path: https://tinybang.googlecode.com/svn/trunk/src/main/java/memorypool
Configuration items:
1. memory.pool.segment.min.size - the minimum segement size with default value is 2
2. memory.pool.segment.max.size - the maximum segment size with default value is 16
3. memory.pool.segment.size.scale - the scale for size of memory with default value is 1024
(Note: so the pool default start from 2 * 1024 to 16 * 1024)
4. memory.pool.segment.size.inc.pace - the pace for size increasing with default value is 2
(Note: so the pool default range is 2, 4, 6, 8, 16)
5. memory.pool.each.segment.counts - the number of entry was contained within each segment with default value is 50
6. memory.pool.allocate.offjvmheap - Direct bytebuffer with true flag and heap bytebuffer with false flag.
My colleagues and I recently do more investigation, we found the two alternatives for the byte array to string and vice versa:
1. sun.misc.BASE64Decoder and sun.misc.BASE64Encoder. But that was not officially supportted by SUN.
2. MigBase64 http://migbase64.sourceforge.net/.
Right now the MigBase64 is the fastest solution for this area. And detail bechmarch please check the url: http://migbase64.sourceforge.net/
So here means if you had direction, you could find any fastest solutions for you references.
The results is:
Example StringLength:6291456
HEX encoder time:421371431 nano seconds
HEX decoder time:257492503 nano seconds
Encoded StringLength:6291456
sun.misc.BASE64 encode time:258552414 nano seconds
sun.misc.BASE64 decode time:359357404 nano seconds
Encoded StringLength:4304680
MigBASE64 encode time:49359904 nano seconds
MigBASE64 decode time:67830130 nano seconds
Encoded StringLength:4304680
So you can see the average time for MigBase64 6 times faster than SunBase64 and 10 times faster than my proposed yesterday.
More often in the large system you may need transfer the byte array - which may serialized stream or read from binary file or socket - via the network. And normally most of system design will took string as the protocol rather than byte array. So here you may need some way safely and efficiently transfer byte arrary to string and vice versa.
So today I will post one toolbox for you resolving that particular problem.
1. ByteArray to HexString
static final String HEXES = "0123456789ABCDEF";
public static String getHex(byte[] raw) {
if (raw == null) {
return null;
}
final StringBuilder hex = new StringBuilder(2 * raw.length);
for (final byte b : raw) {
hex.append(HEXES.charAt((b & 0xF0) >> 4))
.append(HEXES.charAt((b & 0x0F)));
}
return hex.toString();
}
2. HexString to ByteArray
public static byte[] hexStringToBytes(String hexString) {
if (hexString == null || hexString.equals("")) {
return null;
}
hexString = hexString.toUpperCase();
int length = hexString.length() / 2;
char[] hexChars = hexString.toCharArray();
byte[] d = new byte[length];
for (int i = 0; i < length; i++) {
int pos = i * 2;
d[i] = (byte) (charToByte(hexChars[pos]) << 4 | charToByte(hexChars[pos + 1]));
}
return d;
}
private static byte charToByte(char c) {
return (byte) "0123456789ABCDEF".indexOf(c);
}
3. Testing codes
byte[] valueBytes = value.getBytes();
long nanoTime = System.nanoTime();
String hexString = getHex(valueBytes);
System.out.println(hexString.length());
System.out.println(System.nanoTime() - nanoTime);
nanoTime = System.nanoTime();
System.out.println(hexStringToBytes(hexString));
System.out.println(System.nanoTime() - nanoTime);
with the large xml string testing overall the two action took no more than 2 ms. It much better than other alternative solutions.
Note: The value definition for testing list below - the length for that string is 1024:
String value = "<soap:Body>\n" +
"\t\t<ns0:ChangeRFPProposalStatusAction\n" +
"\t\t\txmlns:ns0=\"http://localhost/MeetingBrokerServices\">\n" +
"\t\t\t<StatusChange xmlns:xsi=\"http://www.w3.org/2001/XMLSchema-instance\"\n" +
"\t\t\t\txmlns:xsd=\"http://www.w3.org/2001/XMLSchema\" xmlns=\"http://localhost/MeetingBrokerServices\">\n" +
"\t\t\t\t<DocumentId>b1f10399-40bd-4e10-9426-9f8291ab3a9f</DocumentId>\n" +
"\t\t\t\t<TransactionId>b1f10399-40bd-4e10-9426-9f8291ab3a9f</TransactionId>\n" +
"\t\t\t\t<DocumentDate>2010-12-25T02:39:31.1241257-05:00</DocumentDate>\n" +
"\t\t\t\t<RfpId>5690777</RfpId>\n" +
"\t\t\t\t<Sites>\n" +
"\t\t\t\t\t<Site>\n" +
"\t\t\t\t\t\t<SiteId>213</SiteId>\n" +
"\t\t\t\t\t</Site>\n" +
"\t\t\t\t</Sites>\n" +
"\t\t\t\t<Status>Declined</Status>\n" +
"\t\t\t\t<DeclineReason>No reason provided</DeclineReason>\n" +
"\t\t\t\t<Message>\n" +
"\t\t\t\t\t<To>OnVantage Public Channel</To>\n" +
"\t\t\t\t\t<From>MB Test, User</From>\n" +
"\t\t\t\t\t<Subject>Turndown RFP</Subject>\n" +
"\t\t\t\t\t<Body>with Attach</Body>\n" +
"\t\t\t\t\t<FromEmail />\n" +
"\t\t\t\t\t<MarketingText />\n" +
"\t\t\t\t\t<MarketingHtml />\n" +
"\t\t\t\t\t<Attachments>\n" +
"\t\t\t\t\t\t<Attachment>\n" +
"\t\t\t\t\t\t\t<FileName>file.txt</FileName>\n" +
"\t\t\t\t\t\t\t<ContentType>text/plain</ContentType>\n" +
"\t\t\t\t\t\t\t<FileData>\n" +
"\t\t\t\t\t\t\t\t<char>111</char>\n" +
"\t\t\t\t\t\t\t\t<char>110</char>\n" +
"\t\t\t\t\t\t\t\t<char>101</char>\n" +
"\t\t\t\t\t\t\t</FileData>\n" +
"\t\t\t\t\t\t</Attachment>\n" +
"\t\t\t\t\t</Attachments>\n" +
"\t\t\t\t</Message>\n" +
"\t\t\t</StatusChange>\n" +
"\t\t</ns0:ChangeRFPProposalStatusAction>\n" +
"\t</soap:Body>";
Do you here about C10K?
C10K normally means how to create 10K connections between client and sever via tcp protocol. Have you ever tried two socket client program creating more than 10K connections with single socket sever program?
So in Windows 2003, you will say 2 socket client program can only create 5K connections with 1 socket server program as Windows 2003 default max_user_port is 5000.
So in Windows 2008, you will say 2 socket client program can only create with 15K connections with 1 socket server program as Windows 2008 default max_user_port is 15000.
But I will say you are wrong totally, do you remember the definition for Ephemeral Port?
So the terminology of ephemeral port is mainly used for the socket programming. So (client_ip, client_port, server_ip, server_port) which is ephemeral port actually, the answer is client_port.
So this time can you repeat answer the question above:
So in Windows 2003, you will say 2 socket client program can create 10K connections with 1 socket server program as Windows 2003 default max_user_port is 5000.
So in Windows 2008, you will say 2 socket client program can only create with 30K connections with 1 socket server program as Windows 2008 default max_user_port is 15000.
Then you will find out the max_user_port actually definied the times client can connection with the same server service (server_ip, server_port).
Recently I do test with Netty project with their echo examples,
1. One server machine start with Server Program.
2. Client occupied 3 machines * each machine started 4 jvm instances = 12 jvm instances and each instances will send out 2K connections. So totally we got 24K connections at the end.
Note:
1. all of them based on Windows 2008, the jdk is 1.6_21.
2. The client.bat you need change the parameter with your <sever host address> <server port:8080> <initialMessageSize:256>
It's dummy only can view the connection be connected. But that already give you the ideas how can we implement C10K currently.
Next I will try my best fullfill more functions and try C500K ! Please wait for that post later.
Actions
Filter Blog
By date:
By tag: