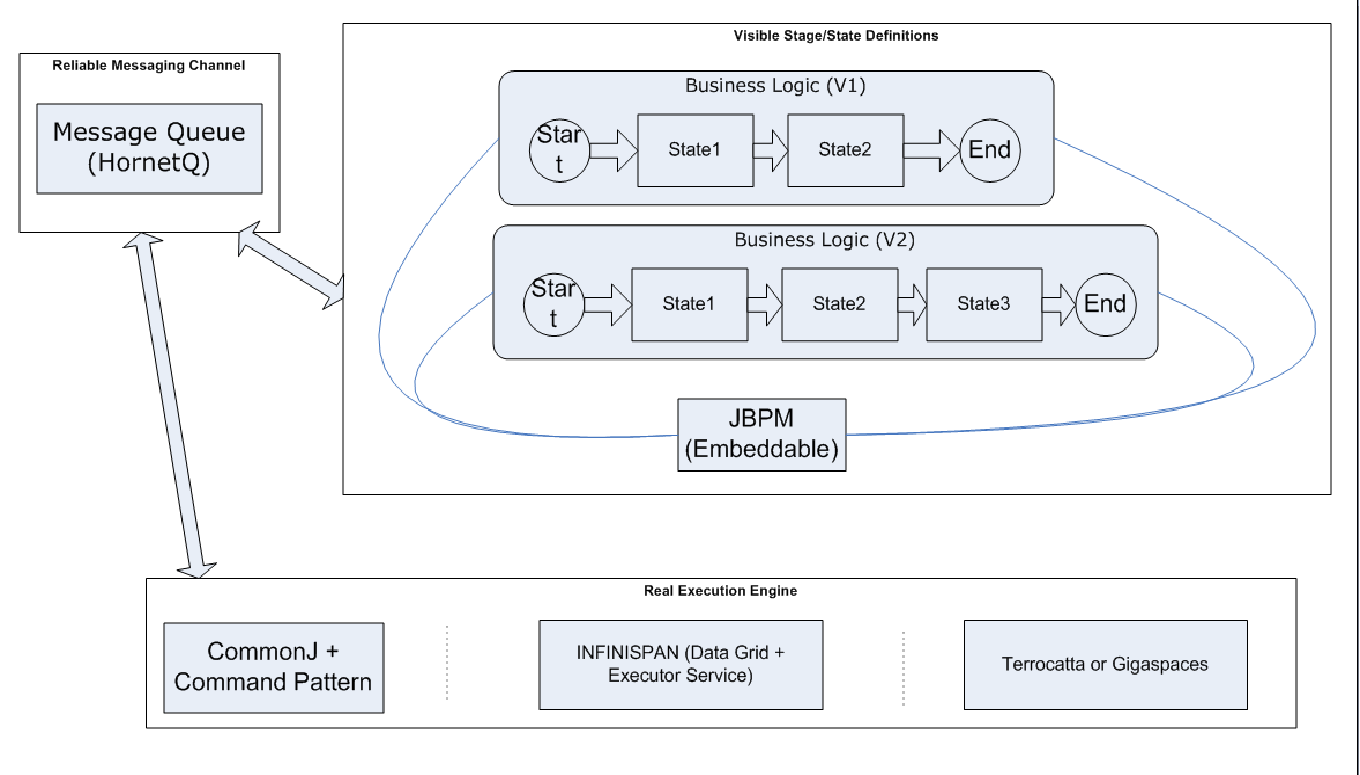
[Introduction]
Many my workmates and viewers ask me about the detail about the "Parallelism" I mentioned in my previous blog post http://community.jboss.org/people/andy.song/blog/2010/08/06/new-way-scale-upout-the-jbpm-without-jbpm-clustering-jbpm-sharding. Because what they think and practice it is impossible from their perspectives, and without the details they even cannot accept the "JBPM sharding" solutions. Then I realized I hided too much things, without that level details something about the new ideas could not be practicable.
[Glossary]
- Parallelism
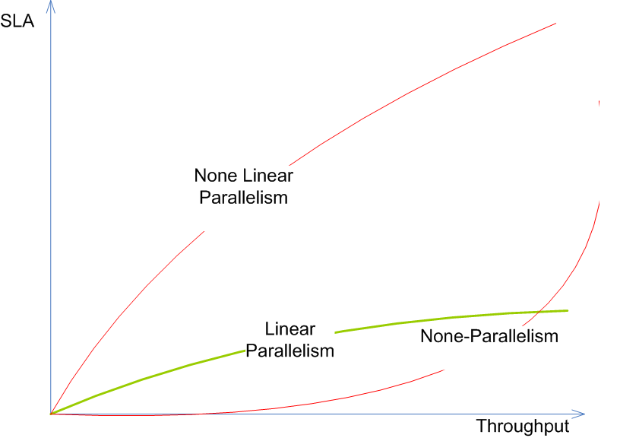
Here I will not lend some expert explaination, I will use my little poor words skill (). If we make the whole system behavior (SLA, Stability) is log(N) same when dealing single request or multiple requests. Simplifies with the examples:
| Type | Single Request (Total Time) | 10 Requests (Total Time) | 100 Request (Total Time) |
|---|---|---|---|
| Parallelism | 10 Seconds | 10.XX seconds | 11.XX seconds |
| None Parallelism | 10 Seconds | 15 seconds | 30 seconds |
- Linear Parallelism
[Details]
Normal JBPM operation contains 3 steps:
1. Start New Processes and signal to the first nodes
2. Do the business logics with each node defined.
3. Singal the process continue execution to next nodes
So here we will fundmentally two different choices will come up, others will be little variant with the following two.
1. Everything is conceptual inside-bpm operations
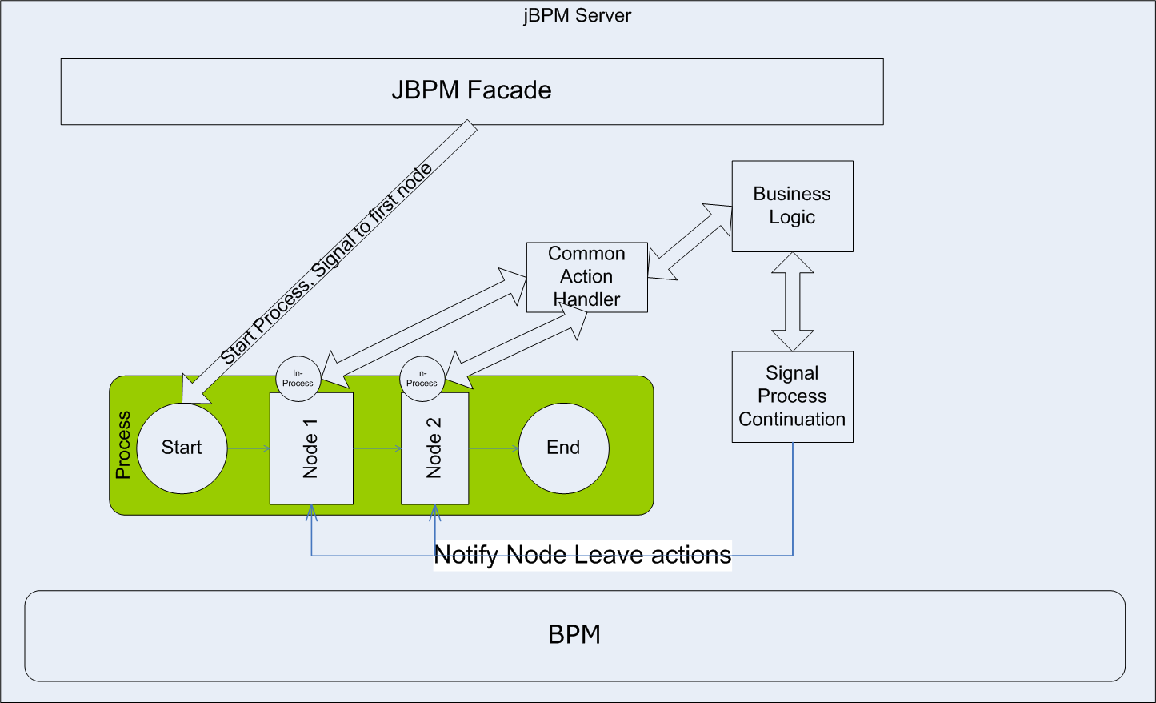
2. Everything is conceptual outside-bpm operations
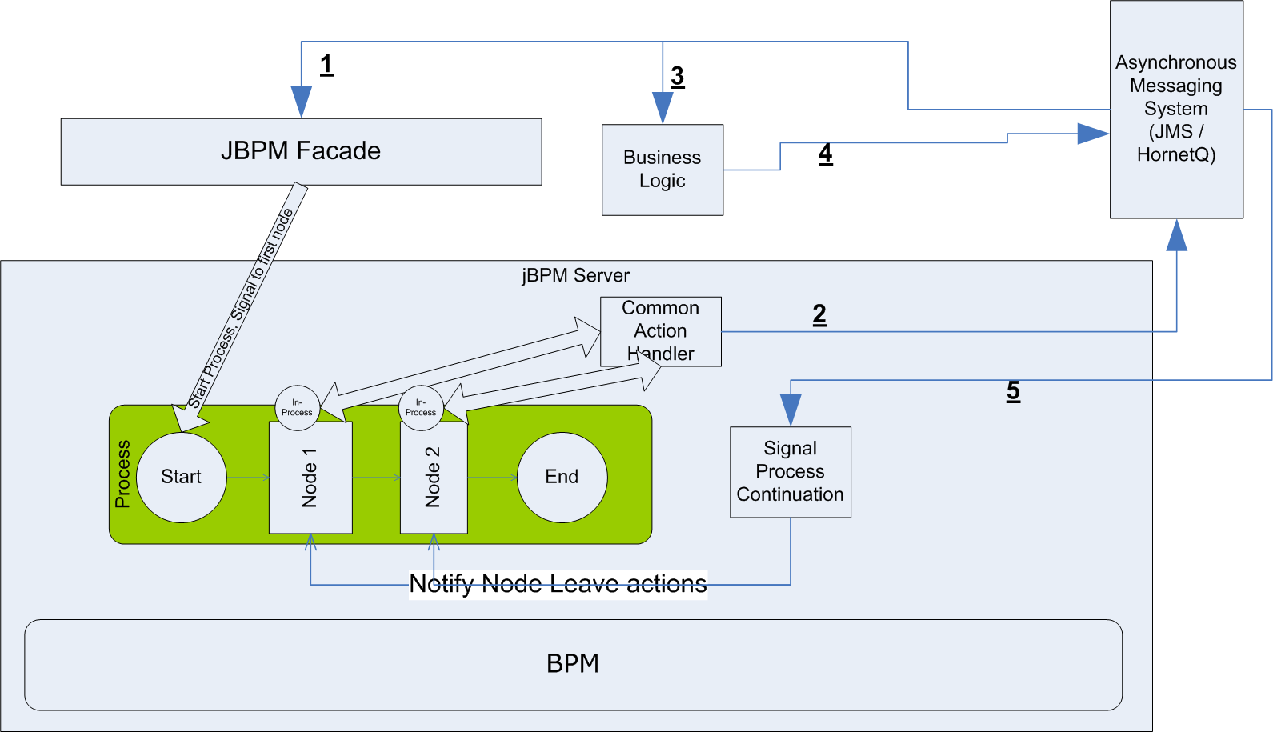
So which was the parrallelism version? Of course "second" was the one we want.
[Pros]
1. Any invocation/interaction with JBPM should be break-up to two pieces: 1. Trigger , 2. Execution. Trigger leverage with asynchronous messaging protocol, jboss does great jobs on that part so HornetQ/Jboss Message is your first choice.
2. The each invocation/interaction input could be searilized to some text format stream, so business logic will only meet some identifiers stream and true business state information will load from storage (DB, Cache, etc).
3. The same datacenter for jBPM and execution logics will be important, otherwise the network partition will become some bottelnecks.Please ref: http://highscalability.com/blog/2010/8/12/think-of-latency-as-a-pseudo-permanent-network-partition.html
4. Transaction ISOLATION prefer the eventually consistency, rather than read_committed. As snapshot information will be largely used in whole process executions.So tranditional transaction isolation will become the stone-block for parallelism.
[Cons]
1. Easy model the transparancey layer wrapper jbpm. So the JBPM sharding will become possible implictly.
2. Object seralization is not acceptable anymore only applicable is identiifer of object seralization.
3. So the individual request processing a little longer than none-parallelism mode.
[Changllenges]
1. Select correct phase for split-up is more important, so SEDA model could help you re-think your system architecture. Please ref: http://community.jboss.org/people/andy.song/blog/2010/08/12/how-jboss-products-contribute-to-seda-models
2. Select correct seralization mode is also important, TEXT/String will be applicable solutions. But memory consumption for sting in java is very bad, you should try your best banlance the memory consumption and parallelism maximum.
3. Only could be put inside the same location Data Center. If cross network locations, the pattern is not applicable. We may need other tools for help like Inter-Data Grid service or Clouding services.
4. You should build your own diagnostic tools for tracing, debuging and deployments. But that means you can learn more, good thing isn't it from DEV perspectives. But managers may hate that.
So right now you understand a little more detail about my previous two blog messages regarding parallelism? Some simple principles comes online:
1. try your best split/isolations.
2. seralization is not always your victim.
3. network communciation isn't always your victim.
4. synchronous or in-jvm execution isn't always means the parellelism
5. research, research, .....
6. reading source codes is good habit
7. slowness, none-parellelsim isn't tools fault, actually is your mind.
8. you should always has your own libraries, because your always don't have enough time for practices.
9. try your best balance the performance(SLA), parellelism, and high avaibilities.