jBPM jPDL improves enterprise support, adds email and new console
Posted by tom.baeyens Mar 16, 2007jPDL is a simple but powerful workflow language for the Java platform embeddable in both standard and enterpise applications. The new 3.2.GA we just released, adds enterprise, email support, a new webconsole. Also we significantly improved the POJO versions of the timer and message services.
jPDL is extremely lightweight. Whereas other BPM technologies heavily depend on web services and XML, jPDL is a natural extension to Java. The interface is a Java API, the process variables can be any POJO and including pieces of Java code into the process is peanuts. jPDL can run on plain Java platforms like a web application deployed on Tomcat or even a standalone application.
For enterprise support, there is now an out-of-the box configuration that shows how to configure jBPM in an enterprise deployment. Along with that, there are a set of EJB's that implement the services required by jBPM, leveraging the services on the enterprise Java platform like JMS and the EJB timer service. All the dependencies are on standard JEE technologies so it is easy to run jPDL on any application server.
For email support, you can now have an email node like this:
<mail-node name="send email" to="#{president}" subject="readmylips" text="nomoretaxes"> <transition to="the next node" />
</mail-node>
But there is more. When writing a task node like the next, you can just add notification and reminder emails just with a single attribute:
<task-node name="wash"><task name="laundry" swimlane="grandma" notify="yes" >
<reminder duedate="2 business days" repeat="2 business hours"/>
</task>
<transition to='b' />
</task-node>
The console went through a major update and is now based on JSF and Facelets. Especially facelets turned out to be a very good match with task forms. Task forms are now generated at design time with the graphical designer so that developers can customize the layout if they want. The forms are facelets documents (plain XHTML) that are included in the process archive.
The POJO implementations of message service and scheduler service were rewritten to provide better and more robust support for concurrent access. Basically, you can now run the complete POJO version of jPDL in a tomcat cluster if you want; multiple threads are allowed to execute the jobs at the same time.
Go check it out:
I'm pretty fed up with the latest attempts of Intalio to get a free misleading ride on the open source wave. I can deal with competition based on features, even if we should lose. I can stand open source competition. But i can't stand that the open source is abused in the way they do.
Their latest press release called 'Intalio Donates BPMN Modeler to Eclipse Foundation' was the drop that made me cool my frustration in this blog. Currently there is only the model... and a screenshot. I wonder how long it will take them before the TODO's are done and the community will see a usable 'BPMN modeler' as they refer to it in their communication. What currently is out there doesn't even come close. Of course, they are free to choose which parts they open source and which not. I acknowledge that. But if you want to be recognized as an open source company, you got to take a different attitude. E.g. other people can use all of jBPM's technology IN FULL. With jBPM, you can even extend it, redistribute and make your money without paying us a penny.
But before this press release, I was already fed up with their cheap insinuations of being open source. For one the title of their home page says: 'Leader in Open Source BPMS'. So I checked it out and tried to download their product. This is a snippet from the license i had to click through:
(c) Restrictions. Unless otherwise agreed in writing by the Parties, Developer shall not (and shall not allow any third party to):
- (i) copy the Intalio Software or any portion thereof,
- (ii) use the Intalio Software in live production or with live data except on allowed databases or application server,
- (iii) decompile, disassemble, or otherwise reverse engineer or attempt to reconstruct or discover any source code or underlying ideas or algorithms of the Intalio Software by any means whatsoever,
- (iv) remove any product identification, copyright or other notice,
- (v) provide, lease or lend the Intalio Software to any third party or use the Intalio Software for timesharing or service bureau purposes,
- (vi) modify or create a derivative work of any part of the Intalio Software,
- (vii) load or use any portion of the Intalio Software at any site or on any equipment other than that indicated above, or
- (viii) disclose any performance information or analysis to any third party (including, without limitation, benchmarks or evaluation test results) from any source relating to the Intalio Software.
IANAL, but my guess would be that neither OSI nor FSF would consider this an open source license :-) So I made a wise U-turn when I saw this license.
I hear their defense coming: "Oh, but we didn't say that our core product was open source, we said that critical components are based on open source and we contribute to open source."
There are many companies contributing to and using open products... and that is just great! And we welcome all Intalio's contributions to open source in that perspective. But if your product contains the above restrictions, and if you only open source minimal parts of your 'critical components', i don't think you are entitled to describe your company as 'The Open Source BPMS Company'. For more insinuations of linking the brand of open source to their brand name, see this google search.
So my advice to Intalio is 'Get honest'. Either commit to open source or stop the insinuations that you are open source.
Before you get the wrong impression, I'm absolutely not religious about open source licenses. This is a completely different matter. I'm just against a misleading marketing.
Different from Intalio, recently a whole tsunami of companies have committed to open source. In most cases this is because they've been put against the wall by open source competition. These companies get my respect, but they have a hard time monetizing their open source software. Let me tell you with my limited business skills: IT IS NOT EASY. Building a scalable business on top of open source software is not easy.
IMO, JBoss and Red Hat are still very much underestimated for their pioneering work in building businesses on open source. I repeat: IT IS NOT EASY. Building communities. Developing and finetuning a completely new business model. Working with just a few of the best developers out there. Getting the right partnerships in place. Leveraging the efforts of the community. Respect that other people want to make money too. Internal development culture. And this is just the tip of the iceberg of all things that need to be just right in order to build a business on open source. For me personally, putting the very top notch developers to work closely in a very small team is the most awsome part. I often refer to it as 'an explosion of creativity'.
My response to those that are still in the phase of "you're not open source because you're making money" is the following: My project (JBoss jBPM) is now alive and doing very well only because JBoss helped me in bulding a business around it. So everyone can now download, use and redistrubute my entire team's work for free. This would never have been possible without the JBoss open source business model.
Another response is that it's middleware... Who the hell would develop professional, scalable, usable, production-ready middleware in his spare time ? Right: no-one! What DOES happen is that peole have great ideas that they want to work out. That might spark an open source project. Working out your own ideas and the community feedback can keep these enthousiasts motivated for some time. But sooner or later, there is always the moment where it gets harder to combine a day time job with your open source hobby. That is where people that don't make a living out of it give up.
I was reluctant for quite a while to express my respect for they pioneering work that JBoss has done in the field of open source middleware. Mainly because I'm an insider or... "contaminated" as some have called it :-) It's a relief that I finally came around to publish my testimonial and frustrations around bad marketing. I feel a lot better now :-) And I hope that it can inspire more people will to realize that building business on open source is not easy and give due credit to the pioneers.
The link between models and code is overdue on a serious revision. Hard core developers usually hate point-and-click IDE's. Managers make models that are not in sync with the software. The current perception that software artifacts is generated from models is seriously flawed.
This is my conclusion after several years of building the JBoss jBPM process engine, which targets business users *and* developers.
After messing with assembler, programming languages grew higher and higher level. Then UML went mainstream. In that context it was assumed that developing software would be done with models in a short future. This is the typical MDA vision.
Higher level abstract models improve communication with business users. But there is the tradeoff between flexibility and complexity. To be executable, software needs to be specified precise and with lots of details. Putting all these details in the model, makes the modelling language too complex for its purpose.
Models should be projections of software artifacts. This should replace the idea that software artifacts should be generated from models.
The argumention goes like this: First, we recognize that there are different types of authors involved in creating software: business users and developers. Business users can think along on the model level, but they don't know about the technical details. Developers are the power users. They can write the actual software artifacts and communicate through the models with the business users.
Also developers should be differentiated: Currently, developers are real powerusers. They type in straight Java code way faster then any point-and-click IDE could enable them. But i think that a whole bunch of less experiences technical people are impatiently waiting until they can use languages (or subsets of languages) that are less complex. They are willing to trade flexibility for simplicity.
If models are a projection of actual software artifacts, there is no need for the models to contain all the details. A very good example of this notion is the method implementation in UML class diagrams. In UML class diagrams, method implementations not available, which is good because that makes it possible to get the overview. The collapsable compartiments in class boxes are another illustration that sometimes you don't want to show all the details in your models.
Before 'markerless round trip engineering', we have been able to experience that keeping models and code in sync is not possible for the majority of software teams. So in this context, it also makes good sense to distill the models from the actual software artifacts. That way, they can't get out of sync. I'm not even close to a UML tooling connoisseur, but the best approach I have seen in UML class diagrams was the old Together IDE. In that tool, the models were generated from the code. The diagram file only contained the graphical information which was not part of the Java code.
So in my refined model software is composed of many software artifacts in various general purpose programming languages and a bunch of domain specific languages (DSLs). The value of models is that many of these deployable software artifacts --that contain great detail-- can be projected, resulting in a visual diagram that shows the higher level concepts without the details.

In the picture above, i have represented the actual software artifacts in the middle. These software artifacts are written in a general purpose programming language or a domain specific language. DSL artifacts are usually input for runtime frameworks. But the main point is that the software artifact layer contains all the details necessary that define an exect behaviour of a runtime environment.
Some (not all) of the software artifacts can be reprensented in models. These models can be generated from the actual software artifacts. Business processes are a great example of this.
So my conclusion is that models should be projections of software artifacts. Wether people use the model-editor or the text editor to author these artifacts doesn't matter. Of course, business users will more often use the model editors and developers (the power users) will use the text editors more often.
Another aspect that is highlighted here is that software is being build as a mixture of general purpose programming (e.g. Java) and a bunch of DSL's which serve as input for frameworks. So the thing that currently is mostly overlooked is refactoring over these language boundaries. The future IDE should be able to detect and execute refactorings over language barriers. That is when we'll get really agile development teams.
Note on relativity: I know I may sound like I just had a great innovative insight. It sure feels that way :-) But most probably, as with many things in life, this will be invented, described and analysed many times before in many different contexts... If that should be the case, I thing it was definitely worth bringing it again to your attention :-)
Regards,
Tom Baeyens
Founder and Lead of JBoss jBPM
Go to the JBoss jBPM Home Page.
Updates from 3.1.2 to 3.1.3:
Features
- [JBPM-617] - keep the processdefinition.xml in the database
- [JBPM-700] - Out-of-the-box compatibility with Sybase and DB2
- [JBPM-716] - make the timer duedate optional
- [JBPM-717] - cascade persistence operations from timer to action
- [JBPM-746] - replace NullPointerExceptions with JbpmExceptions
- [JBPM-749] - extra configuration parameters for jbpm thread servlet
- [JBPM-763] - removed ehcache dependency
Bug fixes
- [JBPM-593] - suspend() and resume() failing in JBPM 3.1
- [JBPM-669] - end-tasks attribute on task-node causes all tasks to be ended, not just tasks for the current token
- [JBPM-696] - Field Instanciator problems
- [JBPM-741] - JbpmSchedulerThread does not terminate the scheduler/command threads properly
- [JBPM-748] - check variable hibernatability before serializability
- [JBPM-758] - DbPersistenceService needs update for new Hibernate version
- [JBPM-766] - cancelling a process instance doesn't propagate to subprocesses and tasks
Task
- [JBPM-740] - Document c3po configuration more explicitly
regards, tom.
On monday I spoke at the Open.BPM 2006 in Hamburg and exchanged ideas with a bunch of German academics. In contrast to typical Java conferences, ideas are challenged in amusing and heated debates. Great!
Overall, I was reinforced in my current perception of the BPM landscape:
- BPM vendors present process languages to the business users, but no runtime executional model, which causes great fragmentation in the market since no two BPM tools are similar.
- The academic approach is formal, but not very practical. Even while the constructs that they used are very simple, using petri nets or PI-calculus as a basis for process modelling is problematic. E.g. It took me 5 minuts to understand the basics of petri nets and it took me 20 minutes to understand the diagram that modelled a traffic light. That was a real masterpiece :-) But it indicates that creating and reading such models is not trivial.
- So the only way that these two worlds can come together is if they are able to define a rich set of business user constructs that can be translated into the formal semantics of PI-calculus, petri nets or something similar.
- For jBPM, process testability and refactoring over Java and process boundaries have higher priority then reasoning over process diagrams.
The most interesting discussion i had was with Frank Puhlmann of University in Potsdam. He's exploring PI calculus as a foundation for BPM modelling.
Exactly as stated above, Frank's vision is to define a set of coarse grained process constructs that are macro's made up of PI-calculus constructs. That way the coarse grained process constructs are intended for the business user and the translation to PI-calculus constructs can be used by the tools to calculate if the process is sane.
He considered PI calculus as better then petri nets because dynamic behaviour is added. Petri nets are static, whereas PI-calculus introduces a notion of reference that can be passed to other nodes in the graph. Then these references enable nodes to have dynamic bahaviour based on those references.
I think that his approach is challenging and I'm curious to see the results of that work. On the one hand, I would like to know what kind of business user constructs can be defined on top of PI-calculus constructs. Will the resulting process language be powerfull enough ? And on the other hand I'm curious what kind of information can be derived from algoritmic reasoning over PI-calculus constructs. Will it be worth while ? Will this information be interesting to the business user or the develop involved ?
If this approach turns out to be usefull in practice, it would fit really well with our Graph Oriented Programming approach. (Note that we're in the middle of reshaping this to a Process Virtual Machine) Basically what we define is a framework in which it becomes really easy to implement process constructs. So if your process language is made up of constructs that can be expressed in terms of PI-calculus, then all the reasoning could be enabled. Frank's work is based on pre- and postconditions. Which would imply that with each node implementation, the node developer could indicate the pre- and postconditions that are relevant for PI-calculus reasoning. That would make it easier for node implementors then translating their node into PI-calculus constructs.
For the jBPM foundations, testability and refactoring capabilities have a higher priority then reasoning over process models. I'm certain that the former two represent real value to developers that have to make the business processes executable. Also this makes process developement fit right into plain Java development. And reasoning still has to prove itself to be usefull in practice.
Just got back from the WfMC Standards Tutorial in Mainz, Germany. What a collection of Business Process Management (BPM) expertise ! It has been a long time since someone mentioned BPM to me without it being immediatly followed by BPEL. It turned out that the whole day gave a very clear picture that i've been preaching for a while as well: BPEL is good for service orchestration but is has got nothing to do with BPM.
I didn't go there for the tutorial, but more for meeting the people behind the WfMC and get a good feeling about the direction they are heading. Where before I was in doubt wether the organisation was pining away, I now saw that they are more alive then ever.
Updating XPDL 2.0 to make sure that you could get a lossless roundtrip from BPMN is a very clever move. Now THAT is a combination for BPM. For analysing and automating business processes, the featureset of BPEL doesn't even come close to the featureset of XPDL or BPMN. And that is an understatement: It's a different planet in another solar system is probably more appropriate.
This, of course, brings up a more nasty issue, in which WfMC might have done a better job in the past: PUBLIC RELATIONS. The WfMC has been overclassed and bypassed by the marketing around BPEL. With or without WfMC becoming better at markting, I am very confident that public perception of BPM will change quite soon. More and more people are realizing that BPEL is for service orchestration, not BPM. Too bad this often requires a desillusion and a lesson learned the hard way.
This BPEL-BPM link that was at the basis of the hype is now causing quite some controversy. Infoq gives a good summary of recent discussions. Most of this controversy boiles down to the discrepancy of what BPEL actually is (service orchestration) and what has been marketed for (BPM).
So you might got the impression that I don't really like BPEL. And yet... I LOVE BPEL ! There, I said it. I think that BPEL is well conceived, complete and does one thing well: SERVICE ORCHESTRATION. How many specifcations get that kind of credit ? For publishing new services as a function of other services, BPEL is the best technology out there. I even consider it very complete. That is why I'm NOT one of those who claim that BPEL is lacking task management and needs BPEL4People. Forget about BPEL being a solution for BPM. Basically, the lack of task management and perceived need for BPEL4People is only an illusion created by their own marketing efforts of promoting BPEL for BPM.
So if you ever see me bashing BPEL again, remember, it's not BPEL itself that I'm bashing, it's the BPEL-BPM marketing link that I'm trying to get rid of. Real BPM folks get really frustrated with that link. I actually have no idea how it came about that this link turned out more stubborn than a whole bunch of greenpeace activists in a rubber boat. Hopefully, we can drop the 'Real' soon as every business and IT person will start to see the difference.
There is one thing however that I think currently is missing and could be the next step for the WfMC: a conceptual execution model. A very complex term for something that would be same as the relational model for databases. Standardizing process languages presents a unified picture to the business analyst. But as the developer needs to add technical details to that process, a unified view upon the execution model is needed. On the process modelling side, there are indeed a number of metamodels (most notable efforts are the XPDL metamodel and BPDM) that describe the process definition terminology. But there is currently a complete lack of mindshare for the executional metamodel. That is all the data that represents the current state of a process execution and how this data is updated when a process executes. All the engines that I have seen so far just is one of a very few execution models.
There is another area where we (the whole BPM industry) needs to improve. Typically, the initiative to go for BPM technology comes from business management. The approach is that processes are developed with a BPM System (BPMS) and that a link can be made to other software components wherever necessary. I think this approach only works well in a limited number of situations. I am much more in favour of considering processes as a part of your overall software development effort. Process languages are just Domain Specific Languages (DSL) and should be integrated in your plain software development environment.
OK, but where is JBoss jBPM positioned in all of this ? First of all, JBoss jBPM is a platform for process languages. At the base there is a java library to define and execute graphs. The actual process constructs like e.g. send email, user task and update database are defined on top of this. Every process language is made up of a set of such process constructs. And that is what is pluggable in this base library. On top of the JBoss jBPM base library, we have implemented several process languages as a set of process constructs: jPDL, BPEL and SEAM pageflow:
- jPDL is a process language with a clean interface to Java and very sophisticated task management capabilities. There is no standard for Java process languages, so it is proprietary.
- BPEL is a service orchestration language. As said before, in BPEL, you can write new services as a function of other services. This is typically a component of an Enterprise Service Bus (ESB).
- SEAM pageflow is a language that allows for the graphically define the navigation between pages in a SEAM web application.
After the kind words for XPDL, Why is there no support in jBPM ? Good question. The answer is that we want XPDL support in the JBoss jBPM platform. It is be relatively easy to implement XPDL on top of our base library. But it didn't yet get any priority yet because of the extra indirection to Java, lack of adoption and its XML schema that is a little to verbose.
Lack of adoption could definitely change after people realize that XPDL is the standard for BPM and BPEL is the standard for service orchestration. Also, I still think a clean compact XML schema is important, but I don't consider this a showstopper any more. That only leaves XPDL language neutrality which, if you're working only on the Java platform, introduces an unecessary indirection. That could in fact also be considered as XML verbosity. So the conclusion is that there is not much left except for market adoption. You can help resolve that part by bugging our sales people and ask them about our XPDL support :-)
Overall, the visit to the WfMC Standards Tutorial was time well spend and I can recommend it to everyone that is involved with BPM in one way or another.
jBPM jPDL is a process language targetted for the Java platform. It includes a graphical designer, the runtime engine and a web console. Main focus of the process language is a clean integration with plain Java and task management. The jPDL runtime engine and database can be easily integrated within your project. Note that other process languages like e.g. BPEL are made available in the jBPM platform as a separate package.
The thing you just HAVE to try out is the new email integration. It took us quite a while to find a good template language that could mix static email content with dyncamic process variables content. After the integration of the JSF expression language, it was an obvious consequence that we would reuse that expression language for our email integration.
Step 1) -- Thou shall download and try out jBPM jPDL 3.2.Alpha1 --
Step 2) If you still didn't click and install the download, put on your hypnotizing-voice, do some magical handwaiving and goto step 1.
Here's my current schedule:
- 28-29 SEP : WfMC meeting : Mainz, Germany : The WfMC Standards Tutorial is adjacent to the Business Process Management 2006 event.
- 16 OCT : open.BPM 2006 : Hamburg, Germany : an academic workshop organised at the university of Hamburg. Both academics and practitioners will be present. I'll be speaking about how BPM Systems relate to BPM and give an update on current state and future of workflow management systems.
- 24 OCT : Enterprise SOA Conference : Brussels, Belgium : a BeJUG event. I'll be speaking about JBI, ESB and orchestration.
- 20-22 NOV : JBossWorld Berlin : Berlin, Germany : I'll be having a great time, that's for sure. I hope you can join us.
- 11-15 DEC : JavaPolis 2006 : Antwerp, Belgium : Great conference. Don't miss it !
The process modeling versus implementation debate continues:
Other posts in this discussion:
- What BPM can learn from a Spreadsheet
- The Promise of Unified Process Modeling and Implementation
- BPM modeling as easy as a spreadsheet
- http://www.ebizq.net/blogs/bpmblog/2006/07/spreadsheets_and_bpm_part_i_de.php
- BPM: The Glue Between Analysis and Implementation
The clean handoff says business does modeling, IT does design, and anything that blurs that separation is inherently dangerous. (In fact, even directly creating skeleton design from the model is somewhat distasteful, but don’t worry, IT can change it later…) The collaborative vision says the line between modeling and design is a fine one and blurring rapidly. ... Ogren sums it up in one line: “The process model is the implementation.”
The difficulty in getting concensus in this discussion is that there are various skill levels of business people. Some just barely know how to use a word processor, while others are able to do some minimal coding.
As you put it nicely, we are in the "the clean-handoff vision" camp. But I don't think that the two visions are that far apart. I would like to refine our position and show where I see the touch point.
The clean-handoff vision doesn't imply you need IT to make it executable. Even in the clean-handoff vision you can strive for good coverage of process langauge constructs. The more constructs the better. But there is a fundamental tradeoff: A process language with a process construct for everything that a business person ever might want to express in a process diagram box will become too complex. The more coverage of the process language, the more complex it will be. The simpler the process language, the simpler the GUI will be and the lower the entry barrier for less technical business people. This implies that we are not looking for the ultimate process language. We can think of many process languages that make sense, I would even include Keith's spreadsheet as one of them.
So that is why it is hard to agree upon a specific process language: there is a whole range of process languages on the spectrum. A process language targetted to have non-technical business people create executable business processes will be very different from a process language that tries to have a broad coverage.
In my opinion, the process only 'is the implementation' in case the used process constructs are covered by the (always limited) process language. I would like to rephrase this as 'The process can always be a projection of the implementation'.
In this context, I see 2 features missing in most of todays BPMS solutions:
- Pluggability of process constructs: Most languages offer a fixed set of process constructs. The bridge to a general purpose programming language has to be natural in such a way that a developer can code the process construct if it is not available out of the box. In jBPM (based on graph oriented programming) and windows workflow foundation this is key. I see the article by Daniel Rubio on Winfows Workflow Foundation as one the first signs that this idea is being picked up.
One of the nice implications is that you will have a kind of empty process engine with a default set of process constructs that come out of the box. The process constructs will be deployed in the engine in a packaged format. A process construct package includes the runtime implementation, and optionally a description of the configuration parameters, an icon, a UI form for the configuration parameters, a projection that filters the design time information from the runtime information to be used during process deployment,...
- Hidden actions: A developer has to be able to add technical details invisibly so that the business people can remain in control of the graphical representation of the process. This can be realized with some kind of event mechanism in which general purpose programming code can be associated with events in the process without the requirement of representing this visually.
OK, so here's my prediction of two movements that will be happening in the BPM arena. Please, interpret this overstatement as a challenge and motivation to write your response down :-)
1) The quest for the ultimate process language will be replaced with embracing a model like windows workflow foundation or graph oriented programming. These are actually models that define the interface between the process engine and the process constructs thereby making them pluggable.
And 2) More emphasis will be on the individual process constructs and less on complete process languages. That is much more feasible then trying to come up with a complete process language. This will result in node packages that you can drop in a kind of deployment directory in our generic engine. Once the interface between the engine and the node packages is defined clearly, this can create a similar component model as with e.g. JSF-components.
To conclude: I see the clean handoff vision as an extension to the collaborative vision. In the collaborative vision, business people model the process and the process is the implementation. It is certainly possible to have business people create executable processes in some scenarios. Depending on how complex your process language is (or how many simple process languages you combine), and the technical skills of your business people, the scope of this kind of process automation will vary. I subscribe to the above and see the clean-handoff as an addition. A technical developer should be able to easily integrate programming logic in case the business person cannot express an activity with the process constructs offered by the process language.
Comments can be posted here in the jboss forums.
regards, tom.
Finally, an interesting online discussion about BPM workflow and orchestration ! :-) This is a reply on Keith Swenson's What BPM can learn from a Spreadsheet. For a long time I was jealous at the Aspect Oriented Programming (AOP) community with their lively and high quality online debates which actually helped to get extremely fast mindshare in that field. I can only hope we can reproduce such speed of discussions in BPM, workflow and orchestration.
First of all, apologies if my writing style would suggest in any way that i know things better. I know that I get interpreted sometimes that way. It's unintended cause after all these years, I really still feel like a beginner. I can only assume that all of us (in BPM) are in this exploration of how to create and use BPM technology to the fullest of its potential.
Now for my response: Yes, I'm in the camp that think that 3GL will be necessary in certain environments. Note the nuance 'in certain environments'. I don't believe in BPM becoming a graphical 4thGL for developing software. For each recurring problem in Java and other general purpose programming languages, little computer languages are created called Domain Specific Languages (DSLs). Of course, this is not a new phenomenon. I see the future of software development as mature DSLs, optionally embeddable in a general purpose programming langauge.
Currently, many of the DSL's are hosted in XML because of the easy syntax, parsing and tools support. First generation of language workbenches are on their way to promote DSLs to first class citicens of software development. But there still is quite a road ahead in that direction, I believe.
The point I make is that a process language DSL needs to be embeddable in a 3GL general purpose programming langauge. So that you can use em stand alone but also integrated into a programming environment if you need the extra flexibility.
An example of a stand alone use case of BPM technology is the typical hello-world-bpm-demo-look-ma-no-code. In those demo's a new process is created from scratch. A few clicks in a graphical designer and instant deployment to a runtime environment. Voila, no code written and we have a new application. I DO think that this is a viable software development strategy in some limited number of environments. But i HATE the marketing pitch that usually comes with these demos like "You can get rid of your expensive, stubborn developers and replace them with business aware analysts".
The process diagram is just 1 aspect of a typical application. In some limited number of cases, you can stay within the boundaries of what the tool offers with forms around the graphical diagram. But this can never be taken to the level of flexibility to implement a comple typical project. In such a project, there are a bunch of requirements. And in most project's, only a part of the requirements will be covered by what you can do with a BPM DSL. In some projects that part will be big, in others it will be small. So We focus on a clean integration between those two worlds, rather then trying to expand the BPM DSL to cover every thing.
Main research is not how far can we take BPM process languages, but how can we raise the bar so that it becomes a new ubiquitous paradigm in software development. In that context, we defined 'Graph Oriented Programming' (very similar to M$ workflow foundation). In essence this is a technoque on how to bind pieces of programming code to a graph and how to execute it. On top of this technique, you can build process languages and complete BPM Suites, orchestration engines and other process languages.
In our experience, we have found that the easiest language to support BPM is a language that has fairly rich semantics, meaning that you have a large pallette of workflow constructs out of the box. Those constructs can then be used and configured without coding. But 'Graph Oriented Programming' is a very extensible foundation. It's very easy to include custom node- (or activity-) types and also to include pieces of code that are hidden from the process diagram. Those features are key in creating a clean bridge between the BPM Suites world and the programming world. So my main point is that I believe BPM Suites approach can be used IN COMBINATION with plain programming. They don't need to exclude each other. Note that with 'in combination' I mean a nice and clean integration. Not a bridge that shows it 'is possible' to get the two worlds to talk to each other.
So we currently have a limited number of functional constructs out-of-the-box (e.g. an email-node is on its way). We know that is an area we have to work on. But users appreciate the fact that a developer can just revert to the java API in case it's necessary. So the business analyst that draws the diagram doesn't have to be concerned with checking if there is a process construct available for what he/she is about to draw.
As an alternative to BPMN, i want to position our current graphical approach. By no means we claim that our approach is better. It's just different in the sense that it's simpler and more informal. So we present nodes as rectangles and inbetween nodes you can draw transitions as arrows. Out-of-the box node constructs can have an icon that is shown inside of the rectangle to indicate the type of behaviour. We envision some graphical decorations, but not much. All of this to lower the entry barrier for business analysts. Formal analysis languages like BPMN have the advantage that they're more expressive. But the downside is that you have take the learning curve in order to take advantage of the extra expressiveness. I still have an open mind wether the ubiquitous BPM language of the future should be like our simple approach, BPMN, something inbetween or both.
Hmmmm. the '2 lines of introduction to my answers' have turned into a bit more i see. Sorry for that. But the good part is that we'll have a good basis for explaining my answers :-)
Consider how Excel has allowed people to directly construct the application. They put in a few numbers, then a few formulas. Before too long, they have a spreadsheet where numbers can be entered in one place, adn answer appear in other places.
A spreadsheet is a very good example. It's a simple DSL.
Some people are able to fill in fields. Others are able to create simple formulas and the pro's are able to define nice graphics and include VB script. The more tech savvy you are the more flexibility you can get from it and the wider the coverage of use cases.
Another aspect that can be shown with spreadsheets is that the more you want to coverage with your language, the more complex it will be. E.G. Overall, spreadsheets do a fantastic job of putting the simple things in your face while keeping the advanced features on the background. Which is very important and a lot less obvious in text based language design. In our jPDL process language we have spend a fair amount of energy on creating and selecting the right defaults.
But by definition, a DSL will never be a general purpose programming language. And so the two will be used together and the DSL has to be embeddable into a general purpose programming language in a nice and clean way.
I disagree. Consider how Excel has allowed people to directly construct the application. They put in a few numbers, then a few formulas. Before too long, they have a spreadsheet where numbers can be entered in one place, adn answer appear in other places. The “searching for how things work” (which is what Tom defines analysis as) is completely integrated in the implementation of the final application.
Integrating the analysis environment into the implementation environment can indeed be very helpfull. This has been our focus for BPM and process flows.
Why can’t the same be true for BPM? Why can’t we simply draw a sequence of step, describe them in English, assign them to people with simple formulas, define a number of variables to hold values in, and have a working application? Will it be any possible application? No. But this type of programming could cover a wide range of applications that are needed today.
Integrating the analysis with the implementation is what led us to our simple graphical notation. That is how close we could take modeling to the analyst without loosing executability, which is our primary goal. Focus is on giving the analyst freedom of the diagram and the ability to document in free format text. I believe that it is impossible to integrate analysis and implementation environments with more formal languages like e.g. BPMN. Especially if the ties with the executability are kept in place. Things become different when looking at pure analysis languages like in IDS-Sheers ARIS. That's a language that is primarily targetted at writing down an analysis. Making these analysis models executable is not straight forward. While they claim a link with SAP's NetWeaver as an implementation platform, they add that this link will never be automatic and transparant because the primary focus of the ARIS language is analysis.
There is a strong business need to take BPM out of the software development lab.
If you replace 'take out' with 'expand to the analysts', we agree :-)
But just like those users who got tired of waiting for R&D to code up those reports turned instead to VisiCalc to do it themselves in 1980, so also will the business users turn to BPM tools that allow them to implement the application directly, without traditional programming.
You can make BPM languages that can be operated by business people. But in my opinion, they always must be embeddable in to plain programming for extra flexibility when you need it. 'When you need it' depends on the skills of the BA's, the complexity of the language and the requirements.
In conclusion I do not think that our vision is mutually exclusive with Keith's. I see exactly the same use cases for BPM technology as Keith does. The only aspect that i would like to add to the picture is that BPM process langauges can and should be made embeddable in a general purpose programming language like e.g. Java.
regards, tom.
Can workflow or BPM simplify the way that software is being build ? Yes and no. Yes, it can improve the way that requirements are being translated into software. No, it will not enable business analysts to write software. BPM technology walks the edge between requirements and implementation. BPM vendors suggest the miracle that drawing a graphical process in their BPM tool will unify analysis, requirements and implementation. I guess it makes sense when you put it like this. But regrettably, many BPM vendors have a poor story on the bigger picture.
This post will address the two main problems i have with current thinking around BPM and workflow:
- BPM vendors often overpromise by hinting that BPM tools can unify analysis with implementation
- Lack of integration between processes and plain general purpose programming language
Analysis and implementation cannot be unified
Wether software development though a programming language like Java or wether it is developed through processes in an executable process language doesn't change the fact that a translation has to be made from the analysis over software requirements to an executable software model. The fact that it is graphical doesn't change a whole lot in that respect. A process developer has a set of process language constructs and needs to come up with a process that is a solution for the software requirements.
For the sake of this post, I'll define analyzing, as trying to understand the problem domain and creating a description of the problem domain. And let's define creating an implemention as creating software artifacts that are executable by a computer system. My main point is this: "You can analyze or you can implement, but you can't do both at the same time." This will have far reaching consequences and it was an important factor during conception of our jPDL process language.
Analyzing means searching for the way things work. You're concerned with understanding the problem domain and describing it as good as possible. Creating an implementation means that you are creating an algorithm in terms of primitive constructs. Executable process languages provide a different set of primitive constructs than a plain programming language like Java. But if the process language is executable it implies that you're building an algorithm.
Keith Swenson and David Chappell have been arguing that BPMN is (going to be?) the analysis model and that BPEL is to be seen as the runtime model. They triggered me in formulating these ideas. Consider the following as my comments on the bigger picture of their statements.
The more formal an analysis language, the easier it is to make the result executable, but the harder it will be to use it for analysis purposes. E.g. a text processor like "Word" and a drawing sketch will always be flexible enough to describe your problem domain. But that doesn't translate automatically into executable software. On the other hand, when using e.g. BPEL to describe your problem domain, --which is an executable process language-- you will be specifying an algorithm and forced to think in terms of how the computer system will execute your process. An executable process language is already executable, but it is less flexible to be used for analysis purposes.
The relation between BPM and Business Process Management Systems (BPMS) is often misunderstood. Even by many of the BPMS vendors. They often make it look like their graphical process designer tool enables to analyse the problem domain (in terms of processes), distill the software requirements and create an implementation in one go.
To illustrate our point of view, we'll show two separate chains and we'll discuss them in both directions.
Analysis Chain People and systems working together in an organisation /\ || || \/ Informal description of people and system working together in e.g. natural language or a sketch /\ || || \/ Formal description in a strictly formal analysis language
Implementation Chain Informal description of an algorithm /\ || || \/ Formal description in e.g. general purpose programming language or an executable process language /\ || || \/ Creation of the runtime artifacts. E.g. compilation. /\ || || \/ Deployment of the executable process into a runtime environment /\ || || \/ Runtime execution of the process
First of all let me make the remark that this list is only intended to illustrate the direction concept and the difference between analysis and implementation. It's does not intend to show that all of these stages need to be done in sequence. In practice, these stages can be skipped and executed in any order analogue to the iterative software development model.
The analysis chain shows that there are various levels of formality in which you can describe your target domain: Ranging from pure english text to a formal analysis method. As an example in this domain, IDS Sheer's ARIS is a good tool to write down your analysis in a formal language.
Separating the two chains represents the fact that we believe there is no natural link between the result of analysis and creating an implementation for software requirements. The direction we're taking in our jPDL process language is that we try to enhance the process with free format annotations and decorations such that it can accomodate some parts of the analysis domain. In many cases that might just be sufficient. But that doesn't change the fact that we're showing an implementation model.
Also the way we conceived the jPDL language was to be an executable process language (an implementation model) but with features so that it can accommodate parts of the analysis model. Of course, never in the pretension that we can replace an analysis model. In essence, the jPDL language defines how a graph can be specified, executed and how java code can linked in that graph.
jPDL comes out-of-the-box with a set of preimplemented node constructs (as like any other process language). But a developer can write code and link this code as the implementation of the behaviour for a node in the graph. This means that a business analyst can draw a node visually and describe the behaviour in plain english. Then the developer can write the java code to implement the description.
Also jPDL contains a mechanism for inserting pieces of Java code in the process without changing the diagram. This is necessary to give the developer enough freedom to make the process executable without messing with the business analyst's diagram. No other process languages I know of has a similar feature. And yet, it seems crucial to me to have some sort of separation between the diagram, owned by the business analyst, and making the process executable, a responsibility of the developer.
Without this feature, process creation always boils down to visual programming. First of all because other process languages restrict the process designer to use a fixed set of process constructs. Each process construct has a runtime behaviour so an analyst needs to think in terms of runtime execution rather then the process that needs to be expressed. Also because no hidden code can be inserted, every little detail needs to be represented in the diagram, even if the business analyst is not even slightly interested. The interest of the business analyst should be the discriminator: IF the BA is interested, it should show up in the diagram, otherwise it should be hidden.
Going back to the direction from informal to executable, you can now see that a business analyst can start modelling a process with nodes (rectangular boxes) and transitions (arrows). As long as there is undefined pieces in the process, it's not executable. Sometimes the business analyst already might pick the right node types from the pallette and configure them properly depending on his/her skills level. But most often, there will have to be some custom code tied to the process either as node behaviour or as actions which are hidden from the graphical diagram. Only when that is complete, the process becomes executable.
As a side note, we believe that it is bad practice to overload the graphical representation with massive amount of decorations to try and express every little technical detail of the process. But the most important point is that you can create a common language between the technical developer, who is responsible for making the process executable and the business analyst, who is responsible for coimmunicating the requirements. Having these discussions around a graphical diagram is extremely helpfull. That is why we created the simplest possible graphical representation for our processes: boxes and arrows. Only an optional icon and the stereotype in the box can give a hint to the actual runtime behaviour.
In the other way round, developers can start extracting and centralizing state management from their application logic and create processes to speed up development of a plain java application. Then, they can use a graphical print of the process in meetings with stakeholders. Note that the graphical diagram does not have to be kept in sync with round-trip engineering. The graphical diagram is in fact a projection of your runtime artifact. It's just 2 different views upon the same process.
BPM automation requires easy integration of programming logic
If you compare all software artifacts being created in a today's software development project, typically the largest portion of that will be written in a general purpose programming language like Java. Apart from that you have e.g. ant build scripts, hibernate mappings, deployment descriptors and various configuration files. In all of the BPM world, there is a complete LACK of vision on how processes fit in there. Processes are always considered separate.
While on the one hand, we try to accommodate analysis data in our jPDL process language, on the other hand, we made sure for a very clean integration with Java. In fact, the Graph Oriented Programming principles, which form the basis for jPDL can be applied to any other object oriented programming language.
In practice, this means that programming logic (Java code in case of jPDL) must be easily integratable into a process. Also processes must be accessible and executable via a simple Java API. And last but not least the API must integrate with the transactions and other services in the overall application environment in which the process is used.
Without a simple and clean integration with a general purpose programming language, a process language is not really suited for automating business processes. Take BPEL for example. While it's an excellent integration technology with great value, it's not very well suited for automating business processes. To include a piece of programming logic, you need to write a piece of code, expose it as a WSDL service and invoke that service from your process. Even without the XML/object conversion that would be a pain.
Process languages have 2 key features which are not available in programming languages like Java: support for wait states to express long running executions and a graphical view of the execution flow. Process languages targetted at simplifying BPM automation should focus on those two key features and leverage plain programming languages for what they are good for. Looking at most process languages, the process constructs are mostly configurable versions of some API usage where the API offers more flexibility.
Conclusion
Despite the suggestion by most of the BPM tooling, analysis and implementation cannot be unified. However it is possible to add features for analysis to an executable process language. But that doesn't change the fact that it's implementing and cannot replace an analysis model.
Currently BPM is associated with BPEL and integration. We believe that BPM is much better served with a process language that integrates nicely with a general purpose programming language such as Java. That doesn't imply that BPEL is bad. On the contrary, BPEL is a great integration technology. We simply want to pinpoint that the association between BPEL and BPM is inappropriate. For making the automation of business processes easier focus should be on creating clean integrations between process language and programming language such as we did with the jPDL process language.
Comments can be posted on this topic in the JBoss jBPM user forum.
Read this blog carefully and you're in for a PAYRAISE. Workflow and business process technology will be essential in developing next generation applications. The knowledge about it is scarce. So it is an easy way to be better then your collegues.
There is a very clear difference between concurrency in a workflow and java concurrency. And yet, on a regular basis I meet people that get them mixed up in quite ugly ways. So under the assumption that everyone reads this blog, this effort will wipe out all related confusion in one go.
We suppose that the reader is familiar with the very basic idea of a Thread in Java. I will explain in detail what workflow is and how it relates to the notion of a Java Thread.
Now, let's look at what workflow is first and then proceed to process concurrency. A workflow or business process always contains a description of a state machine. That is one of the two fundamental differences between workflow and plain Java. When a state machine is created it enters the initial state. After that, signals can be applied to the state machine, causing the statemachine to move to a new state.
For more backround on state machines, see Wikipedia's explanation of Finite State Machines or this intro to UML State Diagrams
Many parts of a business application can be expressed in terms of a state machine. Typical examples are handling an insurance claim, hiring a new employee, the procedure to go public with a company,... All of these are some form of execution that span a long time. When using Java-only, the good ol' top-down approach can't be applied. Cause Java doesn't support persistent wait states. All of these examples include long wait states in which your server application is waiting for someone else or something else to initiate continuation of the overall execution. With Java (or any other imperative programming language) you just don't have a way to program a persistent wait state. Hence you can not express the overall process in Java. The solution is to use a workflow language in which you can express processes. The process has a state machine nature. It can express the overall, long running process.
On a side note, I just HATE the term 'long running transactions' that is sometimes used for this. It just sends people barking up the wrong tree. A long running process is made up of many SHORT-LIVED! transactions and long waiting periods inbetween.
First thing we need to highlight is the transactional nature of a state machines. A traditional state machine is always in one state. Then because of some signal input it moves to the next state. A state machine can never be 'somewere halfway the transition'. State transitions are considered instantaneous. This maps perfectly to the ACID properties of database transactions.
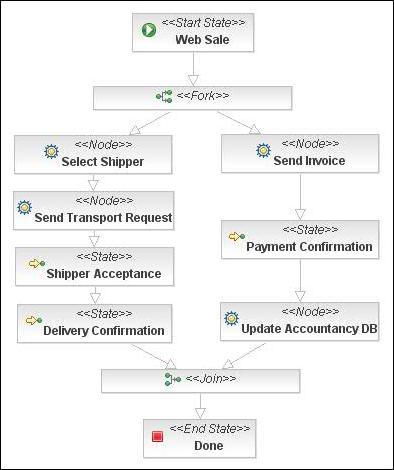
Now comes the most difficult part. A traditional state machine is not sufficient to express real life processes. Real life processes can have multiple concurrent paths of execution, whereas a traditional state machine only has one. The best example of concurrent paths of execution is the billing and shipping path in a sale process as shown in the picture above. Each of those can have several sequential steps. But the billing path can execute completely independent of the shipping path.
The clue of this blog is that the state machine semantics remain in tact even when multiple concurrent paths of executions are involved. Suppose that for a given sale, we are half way down the shipping and billing path. The whole sale process still acts as a state machine. A signal that comes in will bring the process into a new state. E.g. when a payment notification arrives from the bank, the billing path will transition to the next state, while the shipping path will remain where it was. The overall state of the process is the combination of the states for all the paths of execution.
Now, we saw already two important ingredients: processes are in fact state machines and state transitions map perfectly onto transactions. Inside of the transaction, all we have to do is calculate the next state from a given state and the signal that is applied. This calculation does not at all require any multithreaded computing. In fact, the transactional nature of a state transition implies that a single thread is most applicable. Working with multiple threads on one transaction is nasty business.
To illustrate further the difference between process concurrency and java concurrency, let's look at the synchronization needed on the level of the workflow process. Consider 2 signals that potentially can arrive at the same time. E.g. One signal is expected from the shipper, accepting the order to carry the goods from the warehouse to the customer. Another signal that can arrive simultaneous is the bank's notification of payment by the customer. Suppose that there is one global process variable that keeps track of the total number of signals received. So the state of the process execution and the process variable 'nbrOfSignals' are stored in the database.
Here's the scenario of how things can go wrong: the two signals arrive simultaneous, resulting in 2 separate database transactions being started. Then, both transactions read the 'nbrOfSignals' variable from the database, increment it and update it. Then both of these transactions will try to commit. What is the outcome ? The answer is that it depends on the configuration or your database isolation level and the locking strategy used (pessimistic or optimistic). Nothing new has to be reinvented for handling process concurrency. It all comes down to handling database concurrency.
For more on isolation levels and database locking, see the wikipedia explanation for isolation and this exerpt about transaction isolation from an oreilly EJB book.
In summary: Multithreaded computing does not have anything to do with process concurrency. Process executions move from one state to the next in a database transaction. One such transaction can always be calculated in one simple thread. Each signal is handled in one database transaction. So when multiple incoming signals can arrive simultaneous, the database synchronization features (locking and isolation levels) can be leveraged to handle process concurrency.
If you got this far and still got a clue, MENTION IT ON YOUR NEXT EVALUATION and you can be sure that you're in for a big payraise :). Actually I'm serious ! Knowing how business processes relate to plain java and database transactions is KEY to make the software for your project simple, robust and maintainable.
I suspect that the first person to associate BPEL (Business Process Execution Language) with BPM (Business Process Management) was a great mind in marketing from some PR agency and never read the actual BPEL specification. The specification is not that easy to read. So i guess that is why this marketing buzz spreads itself much faster and further then then the knowledge of the specification.
How's BPEL different from BPM
BPEL is a web services programming language. You can write new web services as a function of other web services. Interface to a BPEL process is XML based (WSDL to be pore precise) and the variables inside of a BPEL process are XML snippets.
Oracle is currently the only force pushing BPEL in the marketplace. I got a Google alert on 'BPEL' and rougly 7 out of 10 items are from them. Recently launched Oracle Fusion. That is their new ERP platform that combines all their purchased products. In their Fusion vision, they put BPEL as the integration glue between all those applications. I think that makes sense. That is using BPEL as an integration technology. But they still associate all this integration with BPM. I consider this a legacy misunderstanding.
The goal of BPM is to make an organisation run more efficiently by carefully managing the core procedures and operations. Information technology can be a big factor in making it happen. But most often the inertia of software can't keep track with the changes in the business processes. That is what all the BPM software products are aiming for. Creating an information technology that supports easy automation and easy maintenance of software for supporting the core business processes of an organisation. Little concensus about the foundations of such a technology have been established and hence this still is a highly fragmented market.
Agility is key... also in BPM
Achieving this goal requires software agility. Also Phil Gilbert, the CTO of Lombardi has got it right on in his blog 'BPElephant". Congrats to Phil for standing out in the crowd. It made me realize that i got tired of fighting the BPEL-BPM misconception. Thanks Phil, for sparking my fire again :-)
Agility in software development means removing all overhead from the software development process. The effort spent on software updates because of changing requirements should be minimized. Test Driven Development has been proven a crucial factor in this. So in our vision, a business processes should be developed exactly the same way. For each process, there should be a number of test scenarios with assertions that verify if the process does what it is supposed to do. Only with an extensive test suite (also for your business processes) you can implement changing requirements efficiently. Integration technologies like BPEL are *very* hard to unit test. And concequently it will never lead to an agile organisation when all of your business processes are modelled in BPEL.
Actually, this shouldn't be interpreted as if we (JBoss jBPM) are against BPEL in any way. On the contrary, we think it is a great *integration* technology. We just want to fight the perception that it is also a good BPM technology. We have not always said that clear enough. So to make that really clear: BPEL is one of the process languages in the jBPM suite and it's got half of our resources dedicated to it.
So what's the alternative
Now that you know that BPEL is not a BPM technology, what's the alternative. I wish that we could claim something like: "Look at tech X, it's stable, mature and it's backed by a broadly supported standard" We're not there yet, but there are already some very interesting products that can get you a long way.
IMHO, two products take a different perspective and are leading the way to consensus in how BPM software should look like: JBoss jBPM and Microsoft's Windows Workflow Foundation. The goal of traditional BPM products is to create the ultimate process language The best process language ever ! JBoss jBPM and Microsoft's Windows Workflow Foundation support multiple process languages. Different environments require different process langauges.
For the first time in the BPM market place, two individual (at least to my knowledge:-) developed products look very similar. For Microsoft, this may have been a pragmatic approach, because they have multiple workflow and other graph based execution languages. So it makes sense for them to create a reusable base framework for all of these languages.
We started with Graph Oriented Programming 4 years ago. That is the simple and solid foundation for building graph based execution languages. In my future view, a limited number of process languages will be built on top of this technology. BPEL is one, but also a process language that cleanly integrates with the Java language is necessary. I can forsee a few other languages as well, but not a big number.
Knowing Graph Oriented Programming helps to understand BPM concepts in general. It's similar like the knowledge about tables, tuples, foreign keys and transactions in the world of database systems. In the broad BPM market, such a common foundation is completely lacking and has resulted in fragmented BPM marketspace we have.
Conclusion
BPEL is a good integration technology, but it is a clumsy way of supporting your business processes. We need an alternative. The most interesting alternative is the approach taken by JBoss jBPM, called Graph Oriented Programming and Microsoft's Windows Workflow Foundation. These are base frameworks on top of which graph based execution languages can be built. That approach is in my opinion a very good candidate for improving agility in automating Business Process Mangagement (BPM). IMHO, 2 things should happen with the highest priority:
- All technical architects should be prepared ! Have a look at what BPEL *really* is. So that they can tackle the misunderstandings their business managers make when reading marketing materials about BPEL.
- BPM vendors should challenge Graph Oriented Programming and the (similar) concepts of Microsoft's Windows Workflow Foundation. We should take the community of AOP (Aspect Oriente Programming) as an example. In the past year and a half, a public debate has lead to concensus and a great leap forward. My biggest wish is that we can duplicate such a story in the BPM community.
regards, tom.
JBoss jBPM 3.1 final has been released. Downloads available at sourceforge
Also check out the updated chapter on Graph Oriented Programming. Now, it reflects much better the ideas and vision that we have for the project. It now also includes references to 4 source files. Less then 120 lines of code that clearly show the fundamental concept of jBPM. Including logging and comments ! I really think that the ideas and vision in that article give a view on how software development will be like in a few years from now. There's still a few TODO's in that article, but I'm already excited about it ! I'll keep you posted once it is completely finished. http://jbpm.org/gop
The main updates from 3.0.x to 3.1 were:
- Asynchronous continuations (see user guide Chapter 'Asynchronous continuations')
- Configuration framework (see user guide Chapter 'Configuration')
- Task instance variables (see user guide Chapter 'Task Management' section 'Task controllers')
- Externalized the hibernate queries: (see user guide Chapter 'Customizing queries')
- Added support for JSF like expressions in actions and assignments: (see user guide section 'Expressions').
- TaskInstanceFactory replaced the task instance class configuration (see user guide Chapter 'Task Management' section 'Customizing task instances')
A migration guide is present in the release.notes.html
I hope it's equally fun to use as it was to develop. Enjoy it !
regards, tom.Actions
Filter Blog
By date: