-
15. Re: Re: Re: Teiid 8.4 performance degrading with multiple concurrent requests
shawkins Feb 28, 2014 11:50 AM (in response to van.halbert)
Typically the column names/count is sent along with the result so this level of result set metadata is typically for free (for clients like JMeter that is how they determine how to walk the results). But yes it could easily be removed with a hard count in this case.
Steve
-
16. Re: Teiid 8.4 performance degrading with multiple concurrent requests
anilallewar Feb 28, 2014 12:28 PM (in response to shawkins)
The sysouts are there so that I can mimic the application reading the resultset data from Teiid and putting it to JPA objects so that I know that ORM mapping is not what is causing the range of retrieval times.
Further as I pointed out, I am more worried about the retrieval timings that happen on the source retrieval which now lies in the rage of 25 sec - 107 secs. I will work on getting similar results bypassing Teiid and post my findings.
-
17. Re: Teiid 8.4 performance degrading with multiple concurrent requests
shawkins Feb 28, 2014 12:44 PM (in response to anilallewar)
> The sysouts are there so that I can mimic the application reading the resultset data from Teiid and putting it to JPA objects so that I know that ORM mapping is not what is causing the range of retrieval times.
Other than simulating garbage collection, it would suffice just to call the relevant resultset getters. Given the time ranges were dealing with though this is not a huge concern, but is generally something to be aware of with a multi-threaded test and a slow synchronized resource such as sysout. This stemmed from when I had glanced initially at the code, I missed that you were substring-ing and thought that you could be writing a significant amount of data to the console.
If possible also run the Teiid test with autoCommit true as a comparison point.
-
18. Re: Teiid 8.4 performance degrading with multiple concurrent requests
rareddy Mar 1, 2014 10:26 AM (in response to anilallewar)
I also remember sometime back we discovered that SQL Server JDBC driver from M$ in JBoss AS had a performance issue, the similar we could not reproduce by the JTDS SQL Server driver.
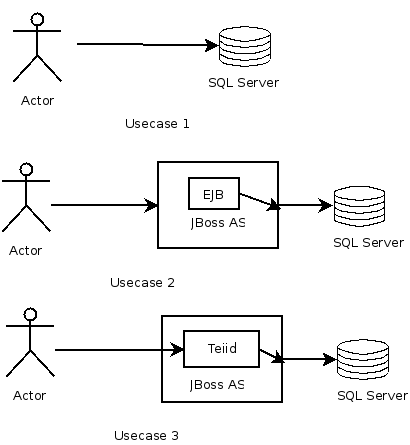
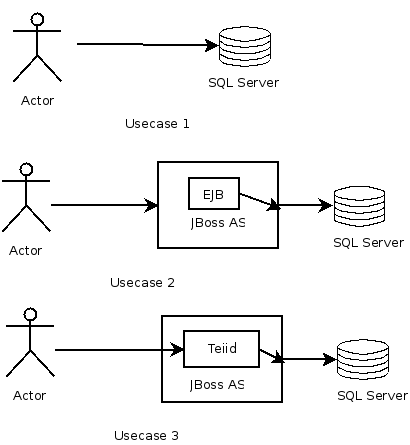
Depending upon which situation you are trying as SteveH says there are different implications in terms of access and transactions. If want compare you need understand design your tests accordingly. Also, Teiid always proactively behaves that it going to interact with multiple sources, but there are transnational settings you can turn off and behave close to Usecase 1. Teiid almost always walks the results, so that it can apply any other filters as just mere passing it through its system, so there is an extra serialization/deserialization step. So, what I am getting is to be equal even the test client needs to be adjusted for the scenario.
Ramesh..
-
19. Re: Teiid 8.4 performance degrading with multiple concurrent requests
anilallewar Mar 4, 2014 3:23 PM (in response to rareddy)
Ok, so I finally got around this
As Ramesh suspected this is a problem with the Microsoft SQL Server JDBC 4.0 driver; specifically the way it handle large resultset buffering. With version 4 of the JDBC driver the default behavior is to have the response buffering as "adaptive" which means that SQL server will determine how much rows it should read ahead and then only get those many rows. This leads to increased lock contention on the SQL server side because of number of concurrent requests that are trying to read data from the same table. The problem can be mitigated in 3 ways
1. Set a limit on the number of rows returned so that we can reduce I/O and lock contention on the SQL Server. If I set the limit to 5000, then the max response time is 5 secs while the minimum is 1 sec. The problem with this approach is how do we support server side pagination; if we keep reading data with skip and limit, then it is possible that some of the data in the page might be repeated if certain CUD operations happened between reading 2 pages. We tried out caching the results so that the next set of data can come from the cache; however I am running into issues where the query hits the cache but returns 0 rows. Again this behavior is exhibited only for the custom resource adapters we have; the cache seems to be returning data correctly for an H2 database.
2. Set the adaptive buffering to "full" which has it reading all the resultset into memory; then the max response time is 200 secs while the minimum is 30 sec for around 768075 records. However this requires around 11-12 GB of heap memory with separate memory allocated to Teiid off heap.
3. Set the selectMethod to "cursor" to have the driver read 1 row at a time; then the max response time is 627 secs while the minimum is 509 sec for around 768075 records. While this works with 4GB heap, it takes around 10 minutes to even get the first set of records.
We had some issues using the jTDS driver primarily because it is not JDBC 4.0 compliant (no XA transaction support) and we were having some issues with transaction management.
With this background, I has a few questions
1. What are the transactional settings referred to in "but there are transnational settings you can turn off and behave close to Usecase 1. "?
2. Is it possible to control the read ahead behavior from Teiid? When I tested against standard JDBC and bypassing Teiid I noticed that the query execution took < 1 sec but closing the connection took 180 seconds. This is because the SQL server driver reads every row in the resultset before it closes it. I was able to get around this behavior so that I can close after reading only 1000 rows by cancelling the statement. So if I could do something similar on Teiid side then I would like to read the source rows (this optimization is most suited in case of non federated VDBs) only to whatever I am reading and not walk the whole source resultset.
3. I have some questions regarding the buffer manager settings but I'll post them on a new discussion so as the keep the scope focussed.
Anil
-
20. Re: Teiid 8.4 performance degrading with multiple concurrent requests
yapnel Mar 4, 2014 5:39 PM (in response to anilallewar)
MS Sql and Sybase handle locking in an inefficient way compared to Oracle. When reading large amount of data from a table it will escalate the lock from page to table level and that will cause performance issue. You might want to change the isolation level to uncommitted and try rerunning your test case again. This can be done in the data source file in jboss. Hopefully that will improve the performance.
What is the fetch size you have set on the client side issuing the query?
If the row size is larger than 2k teiid engine will scale down the batch size by half that is returned to the client automatically and that will require more round trips to fetch the data and consequently increasing the time. Turn on the processor logging and you can derive the batch size used to return back to the client.
Nelson
-
21. Re: Teiid 8.4 performance degrading with multiple concurrent requests
anilallewar Mar 6, 2014 4:14 PM (in response to yapnel)
We can't do read uncommited as that would expose the user to false view of the data store.
The fetch size I am using is 2048 and I tried testing it with fetch size of 4096. The performance actually degraded after increasing the fetch size to 4096.
I also tried using the jTDS driver with same configuration and it gives similar readings which I think lends credence to the theory that the problem would be because of SQL server table level lock escalation.
Anil
-
22. Re: Teiid 8.4 performance degrading with multiple concurrent requests
rareddy Mar 6, 2014 4:20 PM (in response to anilallewar)
Anil,
1) See OFF setting in Request Level Transactions - Teiid 8.7 (draft)
2) Because open and close is not typical usecase. Users usually open connections and hold them in pool and only close or reduce the size based on pool settings. Teiid does not proactively read all the data from source when using FORWARD_ONLY cursor. So, a cancel on Teiid query does result in cancel in source query. But doing this at boxed result count may not possible. I believe Teiid reads atleast one batch ahead.
Ramesh..
-
23. Re: Teiid 8.4 performance degrading with multiple concurrent requests
anilallewar Mar 31, 2014 11:30 AM (in response to rareddy)
Ramesh,
Is this the PROP_TXN_AUTO_WRAP property?
Anil
-
24. Re: Teiid 8.4 performance degrading with multiple concurrent requests
rareddy Mar 31, 2014 12:23 PM (in response to anilallewar)
Yes, for the transaction wrapping mode.