[Introduction]
JBPM (JBoss Business Process Management) is the one of famous open source BPM tool in the world! Even the orignial founder of JBPM already moved to another company but still you need admit JBPM still be good as your expectation. But as usual most BPM trigger pattern hold for user/role interaction model or some explictly rule model or some business calendar pattern, so it's not suitable for some OLTP/Emergency action need. So from my research and sprawlling in the internet, I don't find lot interesting information about the scalability and performance discussion about JBPM. So we dig into and find our way break through the barrier blocking the JBPM cannot support OLTP/Emergency action need. We did some interesting practice and get huge benefit from that, I will share that information for all of you.
[Background]
Our company main handle the communication/negotiation between planner and supplier in the meeting planning fields. And most actions finished by the online web operations, so when each peer finish their operations we need trigger some designated processes then notify the another peers about the detail information as the format with Email, SMS or FAX. The process includes serveral little complex rules, and each step output will impact next steps behavior in most situations. Then we find it mostly match with BPM pattern. So we decide use the JBPM plus MVEL. May someone will jump out say why not Drools? It's too complex for our small business requirements at least from my perspectives.
[Lessons]
So what we learned from:
The answer is JBPM 3.X. Why? Because the founder of JBPM left JBoss when the date of JBPM 4.X supposed to be released, many concept and api was designed very well. But the backend storage design still leverage the old model of JBPM 3.X (and I quite cannot believe the JBoss guys also design so badly about the schema of DB and Hibernate especially from performance perspective). After carfully and painful practices we gave up the JBPM 4.X and moved back to JBPM 3.X. Current in prod we are using JBPM 3.2.7
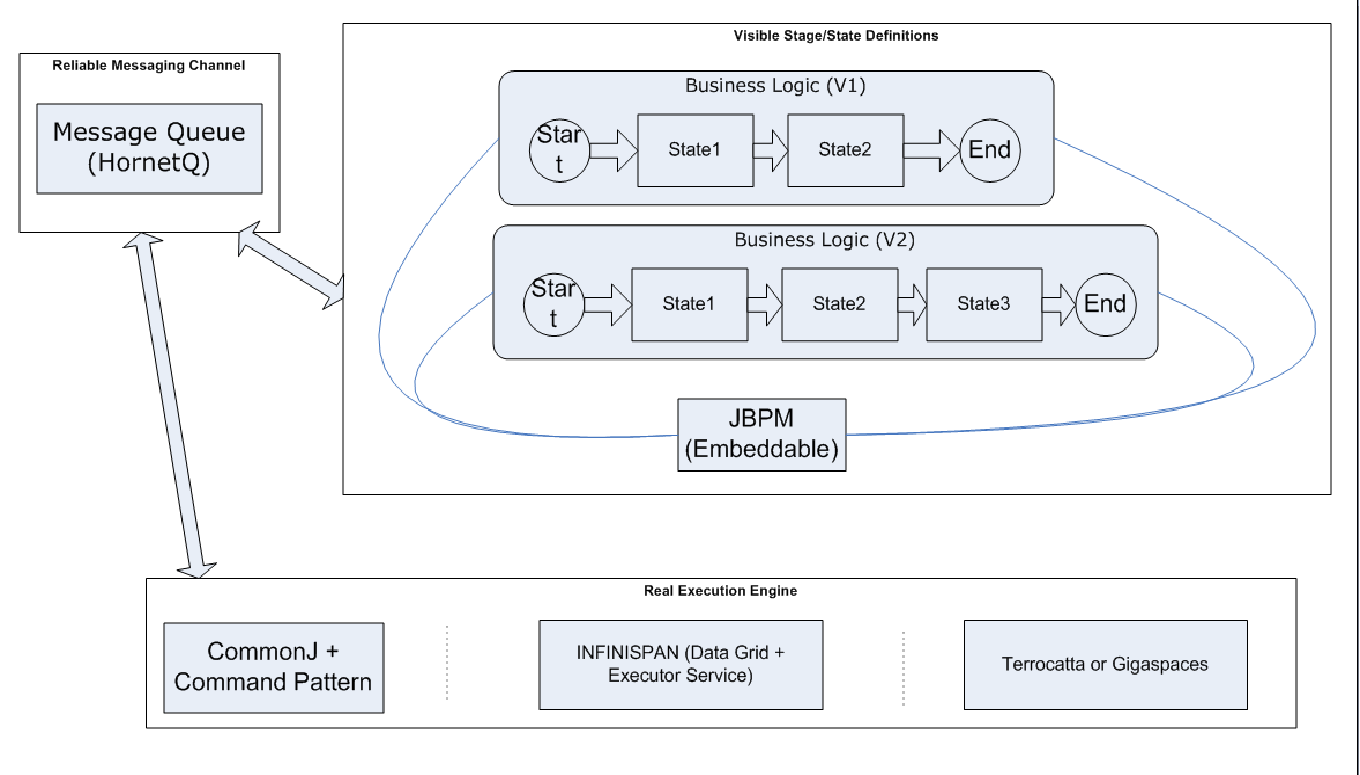
- Please don't put any execution of business logic inside JBPM VM
That doesn't mean you cannot do that, only reason if you use that you will bring lots of contention into JBPM backend model (especially DB parts) and also memory. So try your best push out the exeution outside the JBPM VM with messaging system or some distributed invocation. Current in prod we are using JMS (HornetQ is really good messaging-oriented product really supposed to be tried)
- Please don't simply persist you map variables requests into JPBM
If you are familiar with JBPM, jpbm try to transit the variables as map format (similar with java.util.Map) during process execution. So in most cases I do see many person try to simply leverage with protocol transit the variables, that was the most victim of performance devil. So we still need that protocol but please use that smartly, rather than simply persist the Map information iteratively change to only persist one key/value with unique business key/ whole serializd map. You will get huge performance indicates.
Before Recommend
//Initialize the Map //Initialize the Map
Map<String, ?> variables; Map<String, ?> variables;
.... .... .... ....
variables.put("hello", 10); variables.put("hello", 10);
variables.put("hello1", 20); variables.put("hello1", 20);
variables.put("hello1", new HashMap()); variables.put("hello1", new HashMap());
... ... ..... ....
//Call JBPM api //Call JBPM api
ProcessInterface pi = getProcessInterface(); ProcessInterface pi = getProcessInterface();
ContextInterface ci = pi.getContextInterface(); ContextInterface ci = pi.getContextInterface();
for (Map.Entry<String, ?> aEntry : variables.entrySet()) { String serilizedText = ToStringUtil.
serializedByJason(variables);
ci.setVariable(aEntry.getKey(), aEntry.getValue()); Context.setVariable("BusinessKey", serilizedText);
}
After at least 10 rounds of performance testing we got the following comparable results:
total invocation(start process) per hour Avg Time (milliseconds)
Before 1,000 8,982
Recommend 2,000 412
Almost we got 20X increasing from performance perspective.
[Sharding !!!]
Sorry for so late we came to the main point, here introduce the sharding.

Pros:
- Every node should consist the same process definitions (not mandatory, I will discuss some variants)
- You should have your own distributor or LB controller (inter-jvm or intra-jvm will be fine, only difference you want scale-up or scale-out)
- Try you best be aware of your single node capacity, if your application request far beyond the single node or clustering nodes capacity then try this pattern.
Cons:
- The load of your application (for JBPM part) will divided into X parts (X means how many sharding you want to setup) and also keep the performance of single nodes under specific loads. Increase total capacities.
- Maintainence is harder than before, some deployment or other useful tools need be developed by yourselves.
- Issue diagnostic will be even harder than before. You should have some centralized logging system helpping you dig into the process existed within which nodes, etc.
- Archiving strategy need clearly definied and controlled. Otherwise you will be messed up.
Suitable areas:
- Can be used in any areas, but need resolve the process locality/stickness issues. I will discuss that later.
[Knowledges]
Within single JVM we started multiple JBPM shardings, the distributor will be easily become the java method calling
Running multiple JVMS holds for different JBPM shardings, the distributor will be designed as remote method calling:
- Web Services
- Socket
- JMS
Current in prod we use the intra-Jvm design
- Distribution Algorithm
- Consistent Hashing LB
- Weight LB
- Round robin LB
- Process Locality/Stickness
JBPM ProcessInstance structure cotain one not used field "key", so when we create process instance in jbpm we can put the sharding ID of jbpm into process instance. So later we need populate that key information when do node event handling and signal process continuation.
pros:
Very easy and useful, not spof
cons:
Hard to diagnostic
Current in prod we use that design, but we will log the process creation information into logging system
Create one centralized JBPM process DNS lookup table, similar with other DB sharding design. But you also meet spof and maintainence issues.
Invocation Cnt (1 hour) Avg Invocation Time(Milliseconds)
Single JBPM 9,000 412
JBPM Clustering (4 JBPM nodes + 1 JBPM storage) 10,000 350
JBPM sharding (4 JBPM nodes + 4 JBPM storages) 38,000 370
+ Intra-JVM distributor
So we can see the throughputs and performance increase a lot.
- Other variants
- Computing Grid + JBPM sharding (TBD)
- Clouding + JBPM sharding (JBPM clouding) (TBD)
[Note]
Please forgive me poor english, that skill need to be long-going improvements as I'm Chinese guy.
All testing setting:
1. JVM: jdk 1.6 u21
2. Marchine: Single machine (VM), with dual core cpu and 4G memory
[Reference]
- JBPM site: http://jboss.org/jbpm
- JBPM 3.2.7 docs: http://docs.jboss.com/jbpm/v3.2/userguide/html_single/
- JBPM Clusering references: http://www.theserverside.com/news/1363588/Scalability-and-Performance-of-jBPM-Workflow-Engine-in-a-JBoss-Cluster
- Consistent Hashing: http://michaelnielsen.org/blog/consistent-hashing/
- CommonJ pattern: http://commonj.myfoo.de/
- Terracotta: http://www.terracotta.org/
- My twins photo: http://cid-afd8b274e5b99db9.photos.live.com/browse.aspx/10%e6%9c%885%e6%97%a5
[My Bio]
I am living and working in Shanghai of China, my current company was StarCite. I worked as technical leader in that company and my most forcus was scalability and performance design.