Normally we only have two ways to traversing the object graph of java.
(Assume the java object we talking is conform to java bean specification getXXX/setXXX)
* Prototype java method calling
For instance:
A a = new A();
String name = a.getName();
Benefit:
* Fast and efficient
* No need arbitrary cast
Drawback:
* Only static binding and cannot dynamic specify
* Maintance effort if high and may change regarding to object instance change.
* Java reflection
For instance;
Method method = A.getClass().getMethod("getName());
A a = new A();
String name = (String)method.invoke(null, a);
Benefit:
* Can be used in the flexible way
Drawback:
* Slowly and may cause PERM generation gc times.
* Type safety not be promised.
So if you want to traversing the object graph of java only way - balance the effiency and performance - is prototype java method. But many of us cannot affort the maintainence effort.
Right now how do we do ? We can leverage the scriptable tools. Here we have three choices: JAXB + Xml Parsing, JXpath, MVEL.
* JAXB + Xml Parsing
First use JAXB deseralize the object into XML, and then use parsing tool interpret them.
* JXpath
Use the simliar XPath methodology interpret the object graph path. It was created by Apache.
* MVEL
The scriptable container can execute the documented java programming.
At the end we select the MVEL as the library small and the execution spee is very fast and quite the little slower than JVM. For instance:
A a = new A();
String name = (String)MVEL.eval("getName()", a);
But here we still have several chanllenges for object traversing:
First, how can we get know the detail of one object.
The answer is annotation, here we can leverage XmlType.
@XmlAccessorType(XmlAccessType.FIELD)
@XmlType("A", propOrder={ "name",
"title"
})
public class A {
private String name;
private String title;
}
Then we can use the A.getClass().getAnnotation(XmlType.class).getProperOrder(). Then you will know the object fields detail.
But several things need to be handled:
* Class hierachy. Class.getSuperClass()
* Static fields. Class.getDeclaredFields()
* All detail collection variables need have a value. Because that's limitation for java reflection
So you can generate the fields collection with the following structures:
public class AutoFieldEntry {
private String simpleFieldName;
private String typeInfo;
private String fullFieldPath;
private String xpathFieldPath;
private String mvelFieldPath;
private String fieldReferenceName;
*** ***
}
Then you will have the whole object structures.
Second, how can we avoid the arbitrary object casting.
* Generics help
public T getValue(String simpleFieldName, Class<T> type, A container) {
AutoFieldEntry entry = getFieldsEntry(simpleFieldName);
if(entry.getTpeInfo().equals(type.getName())) {
return (T)MVEL.eval(mvelFieldPath, container);
} else {
throw new Exception("The type you want don't match with the class definition");
}
}
So after those things done, you have the object atrribute arbitrary access container. It reduce the reflection disadvantages and usage was more simlar with java propotype method calling with acceptable peformance ahead.
Example for understanding:
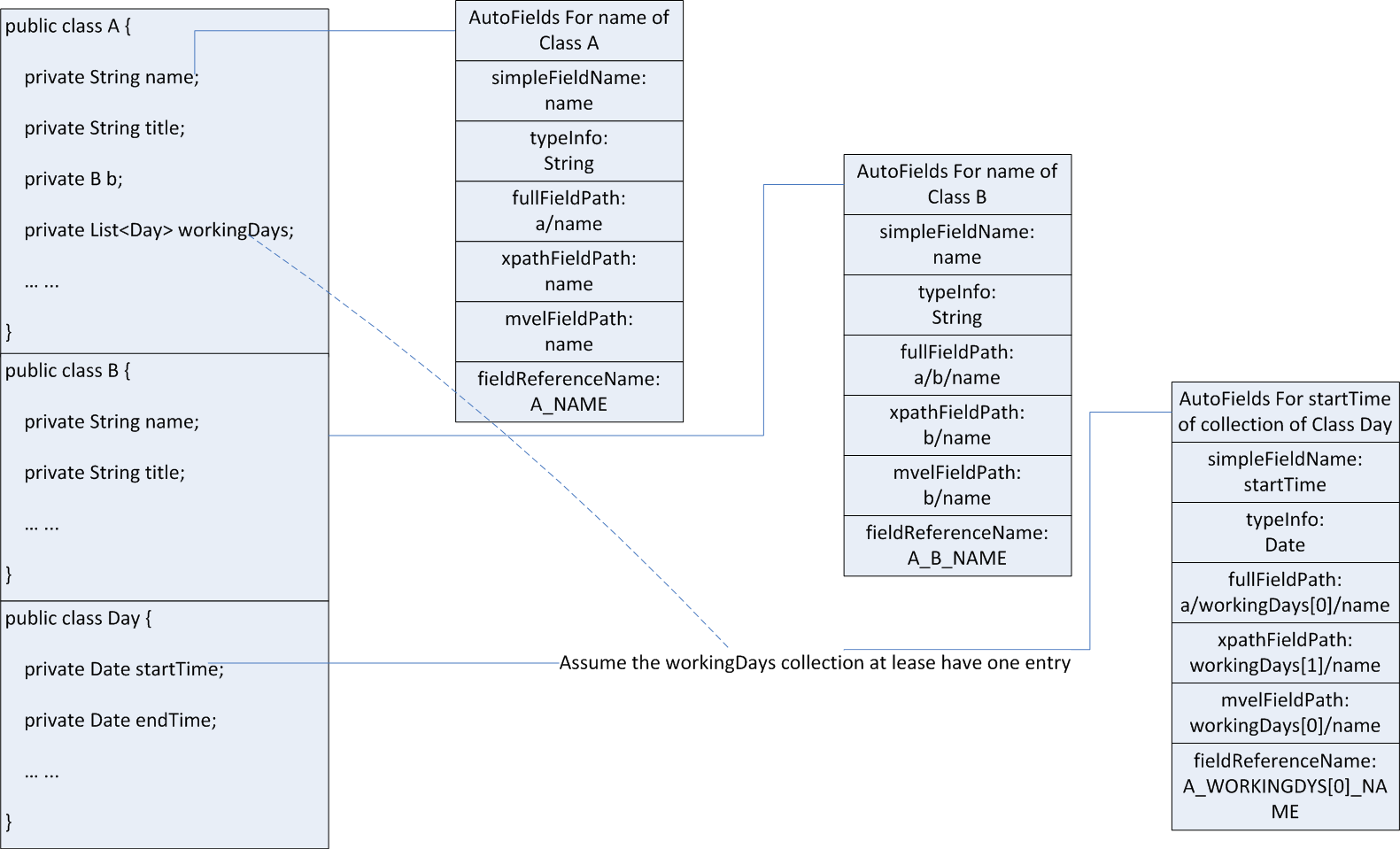
The suitable areas:
1. Data binding. Struts, UI drawing, Rule engine or other areas.
Later we will open-source the codes. So you can refer from that.
Reference:
1. JXPath: http://commons.apache.org/jxpath/
2. MVEL: http://mvel.codehaus.org/
3. Visitor for object graph traversing: http://stackoverflow.com/questions/3361608/java-object-graph-visitor-library