Database plays an irreplaceable role in the modern economy and is widely used in the business computing areas like Enterprise Resources Planning (ERP), Customer Relation Management (CRM), Supply Chain Management (SCM), and the Decision Support System (DSS).
Computation of structured data in the database mainly relies on SQL (Structured Query Language). SQL is the powerful, simple-to-use, and widely-applied database computing script. However, it has some native drawbacks: non-stepwise computation, incomplete set-lization, and no object reference available. Although almost all vendors have introduced and launched some non-compatible solution, such as various stored procedure like PL-SQL, T-SQL. These improved alternatives cannot remedy the native SQL drawbacks.
esProc solves these drawbacks with more powerful computational capability, much lower technical requirement, and broader scope of application. It is a more convenient database computing scripts.
- I. Step-by-step Computation
Case Description
A multinational retail enterprise needs to collect statistics on the newly opened retail store, including: How many new retail stores will open in this year? Of which how many companies have the sales over 1 million dollars? Among these companies with over-1-million sales, how many companies are abased overseas?
This question is progressive. The three questions are mutually related, the next question can be regarded as the further exploring on the current question, fit for step-by-step computation.
The original data is from the database of stores table with the main fields:storeCode, storeName, openedTime, profit, and nation. Let's check the SQL solution first.
SQL Solution
To solve such problem with SQL, you will need to write 3 SQL statements as given below.
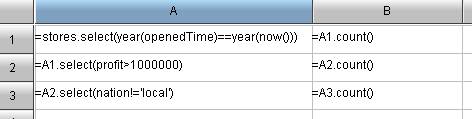
- SELECT COUNT(*) FROM stores WHERE to_char (openedTime, 'yyyy') = to_char (sysdate,'yyyy');
- SELECT COUNT(*) FROM stores WHERE to_char (openedTime, 'yyyy') = to_char (sysdate,'yyyy') and profit>1000000;
- SELECT COUNT(*) FROM stores WHERE to_char (openedTime, 'yyyy') = to_char (sysdate,'yyyy') and profit>1000000 and nation<>’local’;
SQL1:Get the result of question 1.
SQL2:Solve the problem 2.Because the step-by-step computation is impossible (that is, the results of previous computation cannot be utilized), you can only solve and take it as an individual problem.
SQL3: Solve the problem 3,and you are not allowed to compute in steps either.
esProc Solution
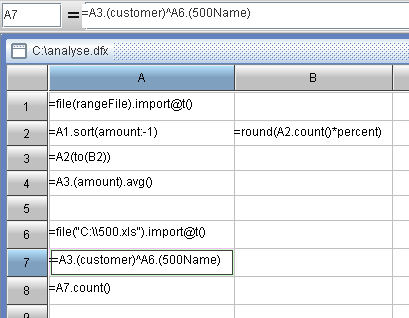
A1 cell: Get the records requested in problem 1.
A2 cell: Step-by-step computation. Operate on the basis of cell A1, and get the record meeting the conditions of problem 2.
A3 cell: Proceed with the step-by-step computation, and get the records requested in the problem 3.
B1, B2, and B3 cell: It is still the step-by-step computation. Count the corresponding records.
Comparison
For the SQL, there are 3 associations for you to compute in steps, and explore progressively. However, because step-by-step computation is hard to implement with SQL, this problem has to be divided into 3 individual problems.
esProc is to compute in steps following the natural habit of thinking: Decompose the general objective into several simple objective; Solve every small objective step by step; and ultimately complete the final objective.
In case that you proceed with the computation on the basis of the original 3problems, for example, seek "proportion of problem 3 taken in the problem 2", or"on" problem 3, group by country". As for esProc users, they can simply write ”=A3/A2”, and ”A3.group(nation)”. In each step, there is a brief and clear expression of highly readable, without any requirements on a strong technical background. By comparison, SQL requires redesigning the statement. The redesigned statement will undoubtedly become more and more complex and longer. Such job can only be left to those who have the advanced technical ability in SQL.
esProc can decompose the complex problem into simple computation procedure based on the descriptions from the business perceptive. This is just the advantage of the step-by-step computation. By comparison, SQL does not allow for computation by step or problem decomposition, and thus it is against the scientific methodology, and not fit for the complex computation.
Complete Set-lization
Case Description
A certain advertisement agency needs to compute the clients whose annual sales values are among the top 10.
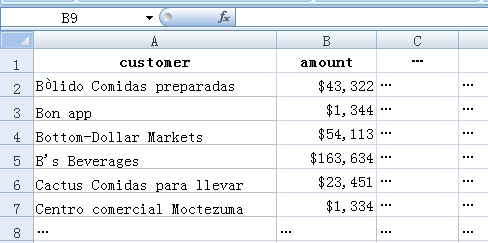
The data are from the sales table, which records the annual sales value of each client with the fields like customer, time, and amount.
SQL solution
SELECT customer
FROM (
SELECT customer
FROM (
SELECT customer,RANK() OVER(PARTITION BY time ORDER BY amount DESC) rankorder
FROM sales )
WHERE rankorder<=10)
GROUP BY customer
HAVING COUNT(*)=(SELECT COUNT(DISTINCT time) FROM sales)
Such Problem requires ranking the sets of a set, that is, group by “time” and then rank by “customer” in the group. Since the popular SQL-92 syntax is still hard to represent this, the SQL-2003 standard, which is gradually supported by several vendors, will be used to solve this problem barely.
Just a tip to compute the customer intersections in the last step, the count of years equals to the count of clients.
esProc Solution
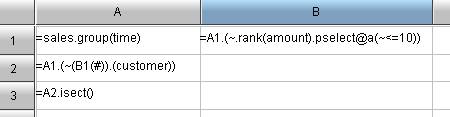
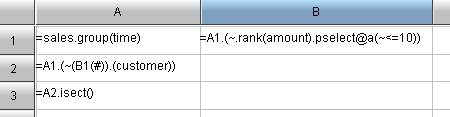
A1: Group the original dataset by year so that A1 will become a set of sets.
B1: Get the serial number of records whose sales values are among the top 10 of each group. The rank() is used to rank in every group, and pselect() can be used to retrieve the serial number on conditions. ~ is used to represent every member in the set. B1 is the “set of set”.
A2: Retrieve the record from A1 according to the serial number stored in B2, and get the customer field of the record.
A3: Compute the intersection of sets.
Comparison
The SQL set-lization is incomplete and can only be used to represent the simple result set. Developers cannot use SQL to represent the concept of “set of set”. Only the queries of 3-level-nested-loops are available to barely perform the similar computations. In addition, SQL cannot be used to perform the intersection operation easily that developers with advanced techniques can only resort to the unreadable statements to perform the similar operations, such as “count of years equal to the count of clients”. It equals to compute the intersection of client sets.
The set is the base of massive data. esProc can achieve set-lization completely, represent the set, member, and other related generic or object reference conveniently, and perform the set operations easily, such as intersection, complement, and union.
When analyzing the set-related data, esProc can greatly reduce the computation complexity. By taking the advantage of set, esProc can solve many problems agilely and easily that are hard to solve with SQL.
III Ordered Set
Case Description
Suppose that a telecommunication equipment manufacturer needs to compute the monthly link relative ratio of sales value (i.e. the increase percent of sales value of each month compared with that of the previous month). The sales data is stored in the sales table with the main fields including salesMonth, and salesAmount.
SQL solution
select salesAmount, salesMonth,
(case when
prev_price !=0 then ((salesAmount)/prev_price)-1
else 0
end) compValue
from (select salesMonth, salesAmount,
lag(salesAmount,1,0) over(order by salesMonth) prev_price
from sales) t
The popular SQL-92 has not introduced the concept of serial number, which adds many difficulties to the computation. Considering this, the designer of SQL-2003 has partly remedied this drawback. For example, the window function lag() is used to retrieve the next record in this example.
In addition, in the above statement, the “case when” statement is used to avoid the error of division by zero on the first record.
esProc Solution
- sales.derive(salesAmount / salesAmount [-1]-1: compValue)
The derive() is an esProc function to insert the newly computed column to the existing data. The new column is compValue by name, and the algorithm is “(Sales value of this month/Sales value of previous month)-1”. The “[n]” is used to indicate the relative position, and so [-1] is to represent the data of the previous month.
On the other hand, for the data of the first record, the additional procedure for division by zero is not required in esProc.
Comparison
From the above example, even if using SQL-2003, the solution to such problem is lengthy and complex, while the esProc solution is simple and clear owing to its support for the ordered set.
Moreover, SQL-2003 only provides the extremely limited computation capability. For example, esProc user can simply use the ”{startPosition,endPosition}” to represent the seeking of a range, and simply use ”(-1)” to represent the seeking of the last record. Regarding the similar functionality, it will be much harder for SQL user to implement.
In the practical data analysis, a great many of complex computations are related to the order of data. SQL users are unable to handle such type of computations as easily as esProc users because SQL lacks of the concept of Being Ordered.
IV Object Reference
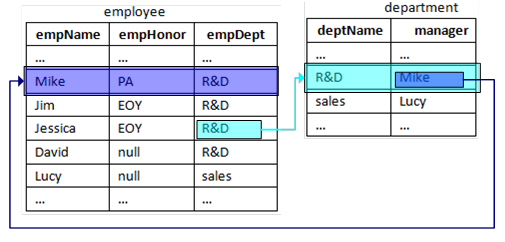
An insurance enterprise has the below analysis demands: to pick out the annual outstanding employees (Employee of the Year) whose Department Manager has been awarded with the President Honor. The data are distributed in two tables: department table (main fields are deptName, and manager), and employee table (main fields are empName, empHonor, and empDept).
empHonor has three types of values: null value; ”president's award”, PA for short; and ”employee of the year”, EOY for short. There are 2 groups of correspondence relations: empDept and deptName, and Manager and empName.
SQL solution
SELECT A.*
FROM employee A,department B,employee C
WHERE A.empDept=B.deptName AND B.manager=C.empName AND A.empHonor=‘EOY’ AND C.empHornor=‘PA’
SQL users can use the nested query or associated query to solve such kind of problems. In this case, we choose the association query that is both concise and clear. The association statement behind the “where” has established the one-to-many relation between deptName and empDept, and the one-to-one relation between manager and empName.
esProc Solution
employee.select(empHonor:"EOY",empDept.manager.empHornor:"PA")
esProc solution is intuitive: select the employee of “EOY” whose Department Manager has be awarded with “PA”.
Comparison
The SQL statement to solve such kind of question is lengthy and not intuitive. In fact, the complete association query language is “inner join…on…” style. This statement is simplified in the above example. Otherwise it will be much hard to understand.
esProc users can use ”.” for object reference. Such style is intuitive and easy to understand. The complex and lengthy association statement for multiple tables can thus be converted to the simple object access, which is unachievable for SQL. When there are more and more tables, the complexity of SQL association query will rise in geometric series. By comparison, the esProc user can always access the data intuitively and easily by taking the advantage of object reference.
Regarding the multi-table associations of complex computation, esProc can handle it more intuitively and conveniently than SQL.
From the comparison of the above four examples, we can see that esProc is not only characterized with step-by-step computation, complete set-lization, sorted sets, and object reference. The analysis style is intuitive, the syntax style is agile, and the function is powerful. esProc is a tool especially designed for mass data computation, and a more convenient database computing script.
About esProc: http://www.raqsoft.com/product-esproc